Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072


Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
G
Bangar1
, Dr. S. N. Holambe2
1 Department of computer science and Engg TPCT’s COE Osmanabad Osmanabad, India
2 Professor, Department of computer science and Engg TPCT’s COE Osmanabad ***
Abstract Wehumansshareouremotions,thoughtsby speaking with each other. If we consider an automatic machine,voicecontrol isthemost convenient wayfor us than carrying a remote controller. Automatic speech recognition system(ASRS) works by breaking down the audio of a speech recording into individual sounds, analyzing each sound, using algorithms to find the most probable word fit in that language, transcribing those soundsintotextandusethattextasacommand.Buthere comes a drawback due to noisy environment. We cannot deliver a clean voice to a machine since speech is degraded by background noise signals. This degraded speechreducesthespeechrecognitionrate. Thepurpose of this proposed method is the enhancement of noisy speechsignalsanditseffectsonemotionrecognition.This method can be applied as pre-processing stage to smart Internet of Vehicle Things (IOVT). The quality of enhancedspeechisevaluatedbysubjectiveandobjective evaluation parameters such as, PESQ, SNRLoss, and overall signal quality. Here we meet best scores by proposed EMSS i.e. about 50 % improvement than ModSpecSub and noisy speech stimuli. For airport noise SNRseg.improvementis55.14%.ForcarnoiseSNRseg. is improved by 60.97 %. For traffic and train noise SNR seg.Improvementis44.99%and39.69%respectivelyat 0dBinputSNRisreported.
Keywords IOVT internet of vehicle Things, Enhanced Modulation Spectral Subtraction (EMSS)
Recentlythereisahugedemandofpreprocessingstagein smart automatic vehicles. Many speech enhancement systems maydegrade speechrecognition performance of emotionsduetobackgroundnoise.
Figure 1 shows generalized system applications for secureIoVT.
In the process of speech enhancement, it is very importanttoacquaintwiththespeechoutput,thespeech signal,andalot ofacousticfeaturesofspeechperception usedbyindividuals.Whiledoingso,wemustpreservethe
properties of speech, need to have high quality and intelligibility of speech. This requires knowledge of Electronic Engineering, Biomedical, and Computer engineering.
To investigate the effect of background noise (such as airport, car, restaurant, railway station etc.) on a typical speech emotion recognition system (such as anger, happiness, fear, sadness etc.) using proposed Enhanced ModulationSpectralSubtraction(EMSS)methodasapreprocessing stage. In order to evaluate the potential performance of proposed approach, objective evaluation havebeenperformed.
In this study we investigated the speech emotion recognition problem under various real-time noise conditionsbyconsideringmodulationdomainprocessing as a preprocessing stage. To investigate speech emotion recognitionperformanceofproposedEMSSenhancement method applied, as preprocessing stages, to speech recognition systems different speech emotion and noise type are employed. The speech emotion stimuli such as anger, happy, fear and neutral are taken from speech emotion database IMMOCAP. The clean speech emotion stimuli are the degraded by different noise type such as airport, car, train and traffic at different input SNR to constructnoisyemotionspeechstimuli.
AMS framework processes the degraded signal in the frequency domain using Fourier analysis. For spectral
e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
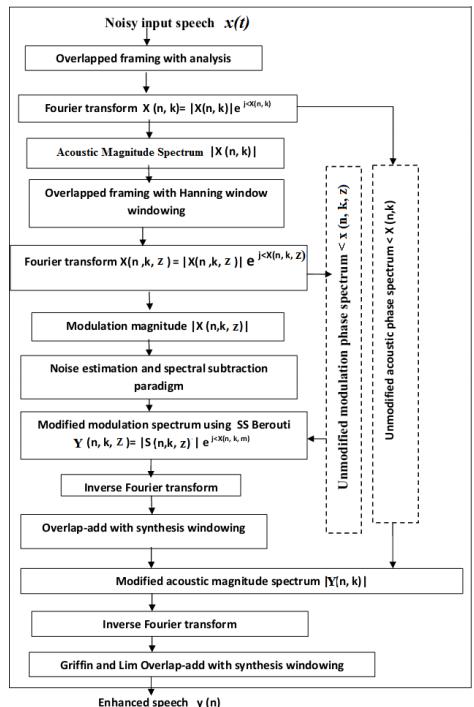
analysis,manyspeechprocessingtechniquesemployAMS framework. In order to achieve this some speech enhancement methods some method employ short time Fouriertransform(STFT)[1,3,4].Hereinthisthesis,the later approach of STFT spectrum which is composed of short time magnitude spectrum and short time phase spectrum is investigated. The modification on this magnitude spectrum is applied to enhance degraded speech. Hence, we have to built the phase spectrum the magnitude before the stage of synthesis. After the overlap-add stage that rebuilt stimuli generated are selectedforthelisteningteststhataresubjectivetestand objective tests to check out enhanced speech quality. To analyzeit, werequirea particularframework in orderto attain modifications in short time spectral domain. We will consider an AMS framework established by Allen Rabiner, 1977 GrifinLim 1984.In order to applyFourier transform, it is compulsory that the input signal be in infinite in length and stationary in nature. This is contradictory to both requirements as speech is nonstationary and infinite in length. The speech signal conveys information thus it cant be stationary. That is why for more obvious reasons, it is impractical to be infinite. Therefore to make Fourier transform practically, weneed touseshort-timeanalysis.ThegeneralizedAMS frameworkinfigure1 decomposesthespeechsignalinto short time frames. Since speech can be considered as quasi-stationary, it can be analyzed frame wise using short-timeFourierTransform.
AMS method [40] is an efficient method for signal enhancement.AMSusesfollowingsteps.
First, framing of the input speech signal with suitable window function and Second, STFT of windowed frames with some frame shift. Third, inverse Fourier Transform and fourth retrieving signal by overlap and add (OLA) method.Let'sconsideradditivenoisescenarioasinEq.
Wherex(n)isnoisyspeech,s(n)iscleanspeechandN(n) isbackgroundnoise Inthisthediscretetimeindex.
As due to non-stationary nature of speech the AMS framework, processing of speech is done over a short frame duration applying short-Time Fourier Transform. Nowthe STFT of noisemcorrupted speechinequ2 x(n) is
Where M is acoustic frame duration in samples, l is an acoustic frame number and index of discrete acoustic frequency represented by k. In our method we applied modified W(n) Hamming window as an analysis window function for both acoustic and modulation domains. This Hamming window is found to be efficient over other window function. In modulation domain processing the AMS framework is repeated after acoustic domain processing.Thespeechsignalspectralsubtractionisdone in modulation domain [2] speech signal with the speech enhancement technique [1, 2, 3] as shown in Figure 3 Nowapply STFTtoEqu2,aswhichgivesfollowing
(3)
Where X(n,k) is noisy speech, s(n,k) is clean speech and N(n,k) is background noise. The fourier transforms representation of X(n,k) is combination of acoustic magnitude spectrum, acousticphase spectrum asshown inEq.4.
(4)
(2)
International Research Journal of Engineering and Technology (IRJET)
e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
The modulation spectrum X(n,k,z) is derived from traditional Allen and Rebiners 1977 AMS based acoustic spectrum elaboratedin Section2.2 .It is computedusing every frequency bin achieved during acoustic spectrum transform by STFT. The frame by frame each frequency componentderivedintheacoustic
Fig.2:FlowchartofaproposedEMSS,AMS-basedspeech enhancementmethod
Traditionallythespectralsubtractionby SSboll method Idonebysubtractingshorttimespectralamplitudeofthe estimated noise from background noise. Thissubtraction yields negative spikes magnitudes spectra. To remove this noise flooring B a shown in Equ 5 is applied as a function of the over-subtraction factor. The modified spectrumisgivenbytheEq.4
In Equ 4 when ᵞ=1 it is Magnitude spectral subtraction andwhenᵞ=2itIpowerspectralsubtraction. αisknown aspectralsubtractionfactor.NoisefloorBisasfollow
(5)
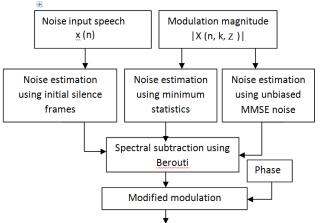
Fig.3:Noiseestimationandspectralsubtraction Paradigm
Fig.3showsnoiseestimationandsubtractionparadigm. processing by repeating AMS framework along time. The modulationspectrumX(n,k,z)is
(6)
Wheren,kisnumberofdiscreteacousticframeandindex ofdiscreteacousticfrequency respectively.zisknown as an index of the discrete modulation frequency. The modulation frame duration L is in terms of acoustic frame. The w(n) is modified Hamming analysis window function. In our study the modified Hamming window withoptimalframedurationof128msandframeshiftof 16 ms is applied for second AMS framework that is modulationdomain.
Most important step in spectral subtraction for enhancement of speech is appropriate estimation noise. We examine the effect of several noise estimation methods on the proposed method. To reduce the computational load, optimal noise estimates for speech enhancement is computed. In modulation domain spectral subtraction, extensive experimental evaluation basedondifferentnoiseestimation methodsaredone.In thefiirst,estimationof noiseusinginitialsilenceframeis done and in the second, minimum statistic noise estimation approach is used. The first approach employs a voice activity detection(VAD) algorithm to renew the noise during pause between the utterances and non-
International Research Journal of Engineering and Technology (IRJET)
e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
speech frames. Hence, there is greater computational load. In the proposed EMSS method, it is observed that during frame shift and atlarge frame duration, no appreciable effect of noise renewing is found during the modulation domain processing in experimental evaluation. Therefore, to reduce the computational load on the conventional ModSpecSub [2] method, we deter the use of the VAD [7] algorithm to update noise and apply minimum statistic noise estimation perspective in themodulationdomain.
3.1 Modulation domain spectral enhancment subtraction:
FollowingEq.7computes modulationdomainspectra (8)
WherecleanspeechsignalestimatesisS(n,k,z)
TheModulationdomainprocessingindifferentaspectsof noise estimation is evaluated by the application of NOIZEUS speech corpus database. The speech emotion stimuli such as anger, happy, fear and neutral are taken fromspeechemotiondatabaseIMMOCAP.
The clean speech emotion stimuli are the degreed by different noise type such as airport, car, train and traffic at different input SNR to construct noisy emotion speech stimuli. We evaluate performance result of proposed EMSSmethodintermsofobjectiveevaluationparameters suchas SNRseg.,PESQ
Theover-subtractionfactorαismanipulatetheamountof subtraction of noise estimate from the noisy speech signal.Table1showstheconfusionmatrixforcarnoise.
TABLE1 Confusion matrix results for different methods in car noise Over-subtraction and is traditionally can be used between 0-6. ᵞ=1 it is Magnitude spectral subtractionandwhenᵞ=2itIpowerspectralsubtraction. Inminimumstatisticsmethod[12,13ofnoiseestimation case α, this should be between 0 and 3. The enhanced output results were obtained at α= 1. The second noise estimation method unbiased MMSE noise estimator, yields enhanced objective scores between 0-1 for α For unbiasedMMSEnoiseestimatorIthasbeenobservedthat α= 0.1 yields enhanced objective scores, but for α= 1, objective scores decays In our study over-subtraction factor α is 0:1≤α≤3. For implementation and result analysis we used α= 1, β= 0:0001 and power spectral
subtraction domain The observation study shows that spectralsubtractiongivesenhancedobjectivescoresatᵞ= 2, α=1.HerewemeetbestscoresbyproposedEMSSi.e.
Table -1: SpeechRecognitionscores: car noise
Typeof Stimuli Neutral Anger Joy Sad Fear
Neutral Noisy 16.5 0 33 50.5 0 EMSS 30.5 16.5 26.5 21.5 5 Traditional Spectral(SS Boll)
12.5 18.5 9.5 51.5 8
Paliwal’s ModSpecsub 8.25 12.5 79.25 0 0
Anger Noisy 0 18.8 28.5 14.7 8 EMSS 0 93.5 6.5 0 0 Traditional Spectral(SS Boll)
12.5 9.5 18.5 51.5 8
Paliwal’s ModSpecsub 0 52.5 47.5 0 0
Sad
Fear
12.5 51.5 18.5 8 9.5
Noisy 11.5 38.5 41.5 8.5 0 EMSS 0 19.5 81.5 0 0 Traditional Spectral(SS Boll)
Paliwal’s ModSpecsub 0 23.5 76.5 0 0
Noisy 5.5 0 44.5 9.5 40.5 EMSS 19.5 0 0 46.5 34.25 Paliwal’s ModSpecsub 0 8.568.25 23.25 0
Noisy 0 0 52.2 32.5 15.25 EMSS 4.5 0 0 42.5 53 Traditional Spectral(SS Boll)
8 9.5 18.5 12.5 51.5
Paliwal’s ModSpecsub 6.2 5 0 046.25 47.5
about52%improvementthanPaliwalsModSpecSuband noisy speech stimuli. For airport noise SNR seg. Improvement is 55.14 %. For car noise SNR seg. is improvedby65.82%.FortrainandtrafficnoiseSNRseg. enhancementis39.69%and40.50%respectivelyat0dB inputSNR.
International Research Journal of Engineering and Technology (IRJET)
e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
Toinvestigatespeechemotionrecognitionperformanceof proposed EMSS enhancement method applied, as preprocessing stages in IOVT to speech recognition systems different speech emotion and noise type are employed. Thespeechemotionstimulisuchasanger,happy,fearand neutral are taken from speech emotion database IMMOCAP. The clean speech emotion stimuli are the degreedbydifferent noisetypesuchasairport,car,train and traffic at different input SNR to construct noisy emotion speech stimuli. We evaluate performance result ofproposedEMSSmethodintermsofobjectiveevaluation parameterssuchasLLR,SNRseg.,PESQ,SNRloss.Forthe speech emotion type anger and happy (with different noise type and input SNR) on structured by treatment type of the proposed scheme, as compared with the traditional ModSpecSub method. Here we meet best scores by proposed EMSS i.e. about 50 % improvement than ModSpecSub and noisy speech stimuli. For airport noiseSNRseg.improvementis55.14%.ForcarnoiseSNR seg. is improved by 60.97 %. For traffic and train noise SNR seg. Improvement is 44.99 % and 39.69 % respectivelyat0dBinputSNRisreported.
[1] Sunil Kamath and Philipos Loizou. A multi-band spectral subtraction method for enhancing speech corrupted by colored noise. In ICASSP, volume 4, pages44164{44164.Citeseer,2002.
[2] KuldipPaliwal,KamilWojcicki,andBelindaSchwerin Single-channel speech en-hancement using spectral subtraction in the short-time modulation domain. Speechcommunication,52(5):450{475,2010.
[3] Rainer Martin. Bias compensation methods for minimum statistics noise power spec-tral density estimation. Signal Processing, 86(6):1215{1229, 2006.
[4] Yariv Ephraim and David Malah. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Transactions on acous-tics, speech, and signal processing,32(6):1109{1121,1984.
[5] P Loizou. Noizeus: A noisy speech corpus for evaluationofspeechenhancementalgorithms.Speech Commun,49:588{601,2017
[6] Philipos C Loizou.Speech enhancement: theory and practice.CRCpress,2007.
[7] Nathalie Virag. Single channel speech enhancement based on masking propertiesof the human auditory
system. IEEE Transactions on speech and audio processing,7(2):126{137,1999
[8] Rainer Martin. Noise power spectral density estimation based on optimal smoothing and minimum statistics.IEEE Transactions on speech and audioprocessing,9(5):504{512,2001.
[9] Yi Hu and Philipos C Loizou. Evaluation of objective quality measures for speech en-hancement.IEEE Transactions on audio, speech, and language processing,16(1):229{238,2008.
[10] PC Loizou. Subjective evaluation and comparison of speech enhancement algorithmsSpeech Commun, 49:588{601,2007
[11] Pavan D Paikrao, Sanjay L. Nalbalwar, 'Analysis Modification synthesis based Opti-mized Modulation Spectral Subtraction for speech enhancement',International jour-nal of Circuits, Systems and Signal Processing, Vol . 11, pg 343352,2017.