International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
***
Abstract - cardiovascular diseases are responsible for the majorityofdeathsglobally.Inmostsituations,thecertaintyof heart disease is known, but it may be anticipated early utilizing various machine learning methods. A proper diagnosis of heart patients can be made based on variables that are readily apparent. Age, diabetes, hypertension, cholesterol, obesity, and physical activity are a few of the contributing variables. In this study we are going to find an algorithmwhich predicts accurately. The dataset contains 14 attributes/features and 270 instances, out of which 150 have heart disease and 120 are considered to be normal. The data seems to be complete with no null values so we are going to use supervised machine learning models. To find out the best model we are going to compare five machine learning algorithms such as Random Forest classification, Support Vector Machine, AdaBoost Classifier, Logistic Regression and Decision Tree Classifier. The goal of this paper is to do comparative research on machine learning algorithms accuracy. This research is going to be developed further for best accuracy model prediction.
Key Words: Random Forest Classification, AdaBoost Classifier, Logistic Regression, Decision Tree Classifier, Support Vector Machine, Algorithm, Instances.
AccordingtotheWorldHealthOrganization,everyyear15 million deaths occur worldwide due to heart disease. The loadofcardiovasculardiseaseisrapidlyincreasingallover the world from the past few years. Many researches have beenconductedinattempttopinpointthemostinfluential factors of heart disease as well as accurately predict the overall risk. Heart Disease is even highlighted as a silent killerwhichleadstothedeathofthepersonwithoutobvious symptoms.Theearlydiagnosisofheartdiseaseplaysavital role in making decisions on lifestyle changes in high-risk patientsandinturnreducethecomplications.Inthisproject, wehavedevelopedandresearchedaboutmodelsforheart disease prediction through the various heart attributes of patientanddetectimpendingheartdiseaseusingMachine learning techniques on the dataset available in the UCI repository, further evaluating the results using confusion matrix and cross validation. The author had used various machinelearningtechniquestopredicttheaccuracyoftest model such as Random Forest, Support Vector Machine, AdaBoostClassifierandwehavecleandatasetwhichcanbe readilyusedwithoutcleaningormodifyingthedataset.
There any many research works done on heart disease diagnosisbyvariousfactors.Inthisstudy,wearegoingtodo a comparative analysis of different classification and regressionalgorithmsandtheresultsrevealedthatRFhad obtainedanhigheraccuracywhichisthehighestamongstthe other algorithms. Authors had proposed a Random Forest ClassificationforHeartdiseasePredictionbyintegratingPCA and Cluster techniques. This study provided a significant contributionincomputingstrengthscoreswithcompelling predictors in heart disease prediction. Compared to five machine learning algorithms-Support Vector Machine, Decision Trees, Random Forest, AdaBoost Classifier and Logistic Regression-to predict heart disease. Among these algorithms, Random Forest gives the best accuracy, at 85.22%comparedtootheralgorithms.Thesystemevaluates alltheparametersusingthetrainingandtestingtechnique. The dataset is evaluated in python coding language. The coding language is then further processed in a Jupyter notebook which evaluates the process by a step-by-step manner.Differenttypesoftrainingandtestingphaseswere implemented.Intheend,thebestpairoftestingandtraining were selected and used in the process for achieving the highestaccuracy.
Thedatasetiscollectedfromanonlineresourcealsoknown astheUCIrepository.Thesedays,thedataisavailableevery dayanditisbesttoimplementthemodelonadatasetwhich is available from a reliable resource. The dataset contains variousattributes/featuressuchasage,gender,fastingblood sugar, serum cholesterol, chest pain type, resting electrocardiographic results, exercise induced angina, ST depression,slopeofpeakexercise,restingbloodpressure, numberofmajorvessels,thalassemiaandtarget.Thedataset contains270instanceswith14attributes.TheTable1gives usideaabouthowthedatasetisimplementedbynumerical values Figure 1 presents us a general overview of the datasetbyindicatingthat44%ofpatientsarenotdiagnosed withheartdiseaseand56%ofpatientssuffercardiovascular disease.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
Age Ageinyears
Sex Male-1,female-0
ChestPain
Typicalangina-0, Atypicalangina-1, non-anginalpain-2, Asymptomatic-3
Resting Blood Pressure 94-200mminHg
Cholesterol 126-524mg/dl
FastingBloodSugar True-1,False-0
Resting Electrocardiographic Normal-0,ST-Twaveabnoramility-1, Leftventricularhypertrophy-2
MaximumHeart 71-202heartrate
Exercise Induced Angina Yes-1,No-0
STDepression 0-6.2values
Slopeofpeakexercise STsegment Upsloping-0,flat-1,downslopping-2
Number of major vessels 0-3values
Thalassemia 0-normal,1-fixeddefect,2-reversable defect
Heartdisease(Target) No-1,Yes-2
Table - 1:DatasetAttributes
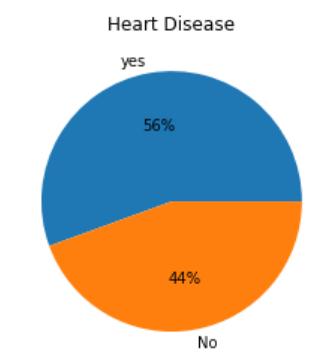
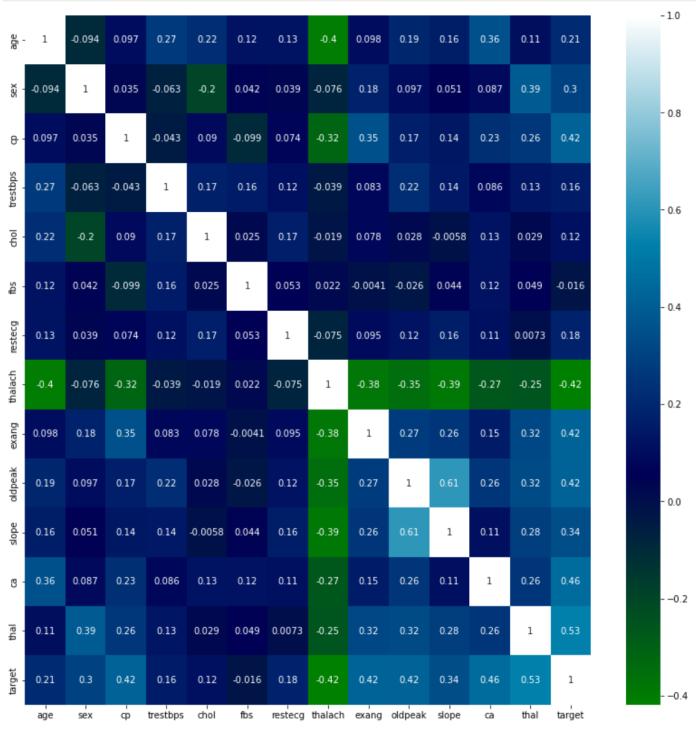
Data correlation, null value verification, loading python libraries,andpartitioningthedatasetintotrainingandtest portions are all steps in the preprocessing of the dataset. Preprocessingprovidesinsightintohowthecharacteristics ofthedataareinfluencingthedata. Individualelementsin thebelowcorrelation,testing,andtrainingdataaredirectly predictiveofheartdiseaseillness.Peoplewithheartdisease areshowninFigure2alongwiththeirlinktootherrelevant variables. The primary factor impacting heart disease has beenfoundasthehighestheartrateattained.Finally,Figure 3 provides us with a comprehensive connection of all features,whichhelpsusidentifythecausesofheartdisease. Thisunderstandingisexceptionalbecauseitdistinguishes betweenbigandsmallelementsinregardtothegoalvalue andisextremelyhelpfulevenwhenthereisalinkbetween them
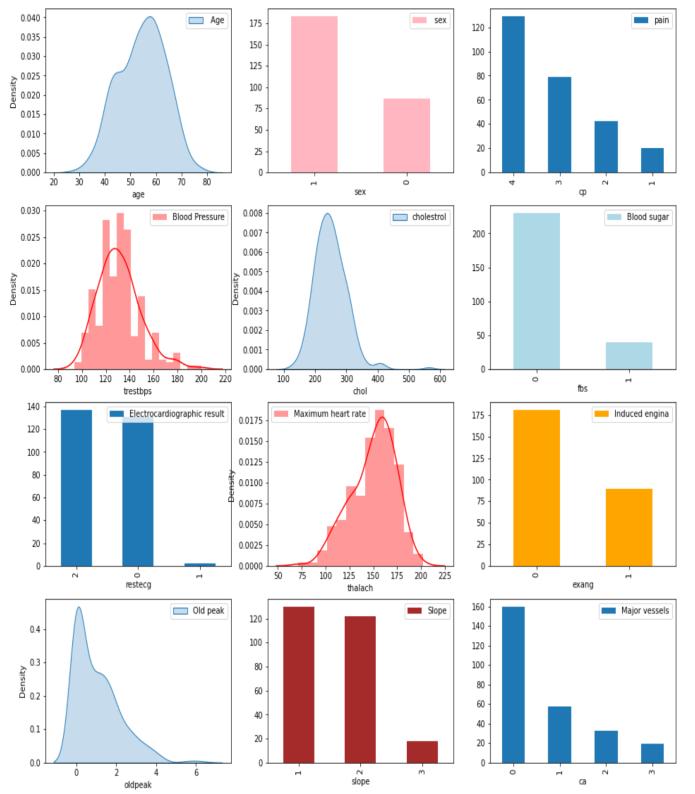
Fig - 1:PercentageofHeartDisease
Fig -2:Attributesinrespecttoheartdiseasepatients
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
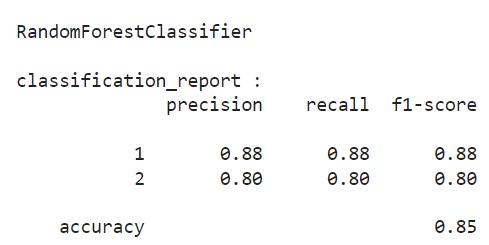
ensemble learning approach. It can used to solve for regression or classification problems. The Random Forest Classifieralgorithmisusedanditstestaccuracywas85.22 percent.
DecisionTreeisastructuredclassifierwhereinternalnodes standinforadataset’sfeatures,branchesforthedecisionmaking process, and each leaf node for the classification result.IthastwonodessuchasDecisionnodeandLeafnode. Thetestaccuracywas74.34percent.
Support Vector Machines implement nonlinear class boundaries using a linear model. The target classes are separatedusingsupportvectors.BeforetrainingalinearSVM model to classify the data in a higher-dimensional feature space to deal with a nonlinear condition, the model transforms the input using a mapping function. The test accuracywas67.43percent.
Fig – 3:Correlationofdata
Thetrainingphaseretrievesthecharacteristicsfromthedata whilethetestingproceduredeterminesthemodelbehaviour for prediction. While the testing phase uses dependent factors,thetrainingphaseusesindependentvariables.There aremanyportionsofthedata.Thesearethestepsoftesting andtraining.90%ofthedatasetisusedfortraining,while 10%isusedfortesting.Weconsidertherandomstatetobe1. Todecidehowthedatawillbesplitintotrainandtestindices, weusetherandomstateparameter.Wecanbecertainthat the method will always generate the same set of random integersifwesettherandomstatetoaconstantvalue.The algorithmsarealreadysetupinaJupyternotebook.
FIG - 4: Splittingdata
Thereareseveralsortsofalgorithms,someofwhichdiffer fromoneanotherwhileothersaresimilar;nonetheless,we nowuseallofthesealgorithmstocomparetheiraccuracyso that the one with the best accuracy may be chosen for improvedpredictability.
Alargenumberofdecisiontreesarebuiltduringthetraining phase of the random forests or random decision forests
An AdaBoost classifier is a meta-estimator that first fits a classifierontheoriginaldataset,thenfitsadditionalcopiesof the classifier on the same dataset with the weights of instancesthatwereincorrectlyclassifiedbeingchangedso thatsubsequentclassifiersconcentratemoreonchallenging cases.Thetestaccuracywas78.59percent.
Logistic Regression is also known as Analytical modelling technique.Itisutilizedtoanalyzedatasetswithoneormore independentfactorsthataffecttheoutcome.Arandomstate of0wasimportedagainforlogisticregression.Thetraining modelwasthenfitted.Thetest’saccuracywas81.23percent.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
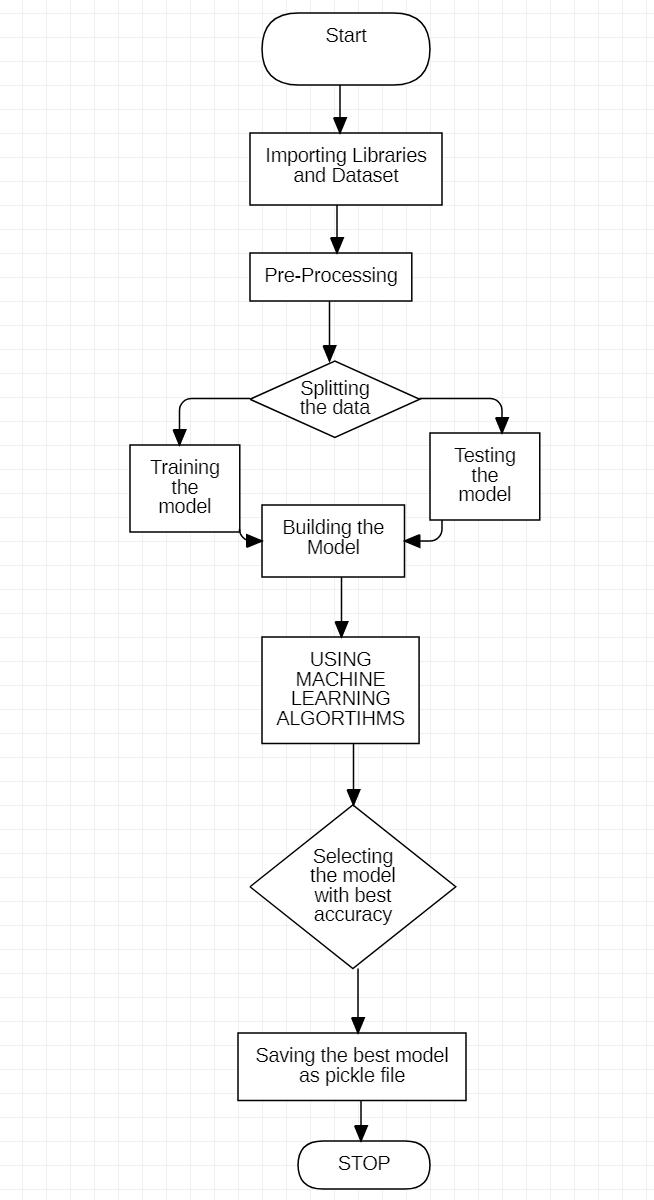
Fig
The flowchart explains how the dataset is utilized while developing a prediction model. Understanding this study reportrequiresunderstandingthisflowchart.
Accordingtothetable,RandomForesthasthebestaccuracy of all the classifiers, at 85.22 percent. Python was used to trainthemodels,splitthedatasetintotrainingandtestdata, andmeasurehowaccuratetheywere.Belowisacomparison of the algorithms' results, along with a table listing their accuracypercentages Sl. No. Algorithms
Therefore,wehavefinalizedthatRandomForestClassifier hasattainedthehighestlevelofaccuracy,asindicatedbythe numericalfigures.AlthoughLogisticRegression,AdaBoost Classifier,DecisionTree,andSupportVectorMachineallhad accuracy levels greater than 50%, they underperformed Random Forest. When compared to the other methods discussed, it can be reasoned that the random forest approachmayalsoattainsuperioraccuracy.
Additionally, researchers may contrast this research’s hierarchy levels to those from other datasets and draw interestingconclusions.Theauthors'intendedstudywillaid in the creation of more accurate, reliable, and productive methodsforpredictingsickness,whichwillbenefitnotjust themedicalcommunitybutalsonumerousothergroupsand individualsthroughouttheglobe.
[1] PouriyehS,VahidS,SanninoG,DePietroG,ArabniaH, Gutierrez J. A comprehensive investigation and comparison of machine learning techniques in the domainofheartdisease.In:2017IEEEsymposiumon computers and communications (ISCC). IEEE. p. 204–207.
[2] https://archive.ics.uci.edu/ml/datasets/statlog+(heart).
[3] "Prediction of Heart Disease using Machine Learning Algorithms" Krishnan J Santhana and S Geetha ICIICT |Year:2019|ConferencePaper|Publisher:IEEE
[4] Bouali H, Akaichi J. Comparative study of different classification techniques: heart disease use case. In: 201413thinternationalconferenceonmachinelearning andapplications.IEEE.p.482–86.
[5] World Health Organization. http://www.who.int/cardiovascular diseases/en. 2019.I.S.JacobsandC.P.Bean,“Fineparticles,thinfilms and exchange anisotropy,” in Magnetism, vol. III, G.T.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
RadoandH.Suhl,Eds.NewYork:Academic,1963,pp. 271-350.
[6] ChauhanR,BajajP,ChoudharyK,GigrasY.Framework to predict health diseases using attribute selection mechanism. In: 2015 2nd international conference on computing for sustainable global development (INDIACom).IEEE.p.1880–84.
[7] "Effective Heart Disease Prediction Using Hybrid MachineLearning Techniques" Senthil Kumar, Mohan Chandrasegar Thirumalai and Gautam Srivastva |Year :2019|ConferencePaper|Publisher:IEEE.
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page81