
DIGEST PODCAST
1,2,3,4,5UG Student, Department of Computer Science and Engineering, PSG College of Technology, Coimbatore. ***
Abstract - This is the age of instant gratification. Browsing the entire Publication is dawdle , hence we have proposed an application that summarizes all your reading’s in a snap of time using AI technologies The system is composed of Optical Character Recognition(OCR) engine to convert the image to text and transformer to summarise the text, dispensing recurrent networks followed by feature prediction network that maps character embeddings to mel-spectrogram and a GAN based vocoder to convert spectrogram to time based waveforms. Through extensive experiments we demonstrate digest podcast ability to recognize, summarize, speech synthesis for summarized audio generation. Our code can be found at https://github.com/mitran27/Digest_Cassette.
Index terms: Optical Character Recognition,segmentation, summarisation,mel-spectrogram,GAN,speechsynthesis

1.INTRODUCTION
Readingandinterpretinga protractedsegmentof textisachallengingtask.Theaboveprocessinnaturalscene textisgenerallydividedintothreemajortaskslikeOptical CharacterRecognition,Summarization(interpretation)and synthesizingtheaudio.
The promise of deep learning architectures to produce probability distributions for applications such as natural images,audiocontainingspeech,natural language corpora.Thereareveryfewapplicationsoverthedecadeto combinedifferenttechniquestodominatethefield.Dueto the wide range of vocabulary in the language and speech generated bythemodel wasnotpromising.Wepropose a new podcast application which overcome the above drawbacks.
Intheproposedapplication,thearchitectureisbuilt withthestateoftheartnetworksafterabunchofresearch studiestofindbettermodelswiththeirhyperparameters.
The OCR model is built using the scene text detection and text recognition using the computer vision architectures which are proved to give promising results The summarization model is built using the transformer eschewingrecurrentnetworksandrelyingentirelyonselfattentionmechanism,whichallowsmoreparallelizationto reach the new state of the art model. The choice of abstractiveorextractivesummarizationisgiventotheuser. Thepodcastmodelwhichgeneratesthenaturalspeechfrom the summarized text is built using two independent networksforfeaturepredictionandspeechsynthesis.The layersinthemodelarechosencarefullytoavoidartifactsin the sound. Hyperparameters are chosen properly to generatesyntheticspeechmorenaturalcomparedtohuman speech.
2. RELATED WORK
Recognizingtasks/problemshavebeenefficiently addressed by Hidden Markov Model, Recurrent Neural Networks,LongShort-TermMemory(LSTM)network These methodsuseartificialneuralnetworksorstochasticmodels tofindtheprobabilitydistributionoftheoutput.Although thesemethodsareefficient,theyhaveadrawbackoflimited variationofinputs.So,weuseTransformers[1],whichuses attentionmechanismstofindtheoutput.Transformersisan architecturewhereeachwordinthetextwillpayaweighted attention to the other words in the text, which makes the model work with large sentences. Transformer model exhibitsahighgeneralizationcapacityoftextwhichmakesit stateoftheartintheNLPdomain.
TextRankalgorithm[2]whichwasinspiredbythe PageRankalgorithmcreatedbyLarryPage.Inplaceofweb pages, we use sentences. Similarity between any two
sentencesisusedasanequivalenttothewebpagetransition probability. The similarity scores are stored in a square matrix,similartothematrixMusedforPageRank.TextRank is an extractive and unsupervised text summarization technique.
Segmentationresultscanmoreaccuratelydescribe scenetextofvariousshapessuchascurvetext.However,the post-processingofbinarizationisessentialforsegmentation DBnet[3] suggests trainable dynamic binarization had a greaterimpactonpredictingthecoordinatesofthetext.
Recognition involves extracting the text from the inputimageusingtheboundingboxesobtainedfromthetext detection model and the text is predicted using a model containinga stack of VGG layersandtheoutputis aligned andtranslatedusing CTC[5] loss function. Baek suggested thatusingrealscenetextdatasets[4]hadsignificantimpact thansyntheticallygeneratedtextdataset.
ConnectionistTemporalClassification[5]suggests that training a sequence-to-sequence language model requirescomputationoflosstofinetunethemodel,vanilla modelsutilizecrossentropyforfindinglossderivatives.Text recognitionissequencetosequencemodelsbutsuffersfrom a drawback that they do not have fixed output length and they are not aligned with the input. So, in order to Label UnsegmentedSequenceData,weuseCTCwhichcomputes lossbyfindingallthebestpossiblepathofthetargetusing conditionalprobabilityfromtheprobabilitydistributionof classesavailablefromalltimesteps.
Asequencetosequencemodelwithattention and location awareness[6] is used to convert the summarized texttospectrograms,which isanintermediatefeaturefor audiousinganencoder-decoderGRU[9]
Generative Adversarial Network[7] is an unsupervisedlearningtaskinmachinelearningthatinvolves automatically discovering and learning the regularities or patternsininputdatainsuchawaythatthemodelcanbe used to generate or output new examples that plausibly couldhavebeendrawnfromtheoriginaldataset.
High-FidelityAudioGenerationandRepresentation
LearningWithGuidedAdversarialAutoencoder[8]thatHiFiGAN consists of one generator and two discriminators: multi-scaleandmulti-perioddiscriminators.Thegenerator anddiscriminatorsaretrainedadversarial,alongwithtwo additionallossesforimprovingtrainingstabilityandmodel performance.
MelGAN[10]hasgeneratorwhichconsistsofstackof up-samplinglayerswithdilatedconvolutionstoimprovethe receptive field and a multiscale discriminator which examinesaudioatdifferentscalessinceaudiohasstructure atdifferentlevels.
3. MODEL ARCHITECTURE
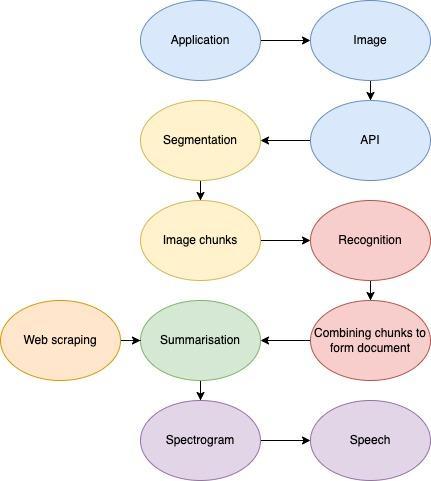
Our proposed system consists of six components, showninFigure1
(1) Semantic segmentation model with differentiable binarization
(2) TemporalrecognitionnetworkwithCTC
(3) Abstractive summarization model using attention mechanism
(4) Extractive summarization algorithm using PageRankalgorithmwithword2vecembeddings
(5) Feature prediction network with attention and locationawarenesswhichpredictsmel-spectrogram
(6) Generative model generates time domain waveformsconditionedonmel-spectrogram
3.1. DIFFERENTIABLE BINARIZATION SEGMENTATION NETWORK
DBnet uses an differentiable binarization map to adaptivelysetthresholdforsegmentationmaptopredictthe result.Spatialdynamicthresholdsfoundtobemoreeffective thanstaticthreshold.
Static binarization
if(Pi,j>threshold) Bi,j=1 else
Bi,j=0
Dynamic binarization
Bi,j = div(1,1+exp(-K*(Pi,j-Ti,j))) whereBisthefinalbinarymap, Pisthepredictionmap, Tisthethresholdmap, Kisarandomvalueempiricallysetto50
Thestaticbinarizationisnotdifferentiable.Thusit cannotbetrainedalongwiththesegmentationnetwork.
The segmentation architecture of our method is shown in Figure 2. Initially the image is passed through feature pyramid network and the output features are concatenated and the final prediction is passed through predictionandthresholdnetworkswhichconsistsofcouple oftransposedconvolutionlayerstoupsampletoitsoriginal size.
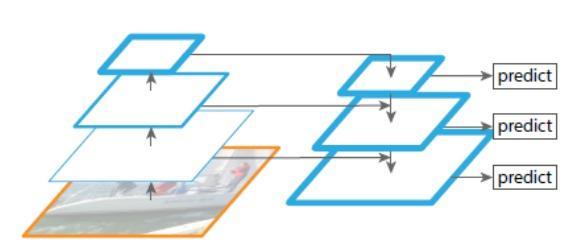
Ourmodelworkswellwithlightweightbackbone, with the backbone of RESNET 18. Features were taken at threestagesatthescaleof(8x,16x,32x)oftheoriginalsize. The outputs of the FPN produced features of dimension dmodel=256.
ThelossiscomputedusingDICElossforprediction mapandbinarymapandL1lossforthresholdmap.Losses arecomparedtothegroundtruthmapoftheoriginalimage.
3.2. RECOGNITION
Temporalimagerecognitionisperformedinword images to recognize the words in the text format. This is achieved by constructing a model which consists of VGG networkforfeatureprediction,GRCNNcanbeusedincases wherehighaccuracyisneededneglectingthespeedofthe model.Thefeaturesaretransposedtotemporaldimension andpassedtotwolayeredbi-directionalLSTMmodelwith 1024unitstopredicttheoutputtemporally(Figure3).The outputfromthemodelisnotalignedwiththeinputimage. SoConnectionistTemporalClassification(CTC)modelisused because CTC algorithm is alignment free, CTC works by summingtheprobabilityofallpossiblealignments.
functionwithrespecttotheoutputandbackpropagationis donetotrainthemodel.

Fig-3: PredictionfromtheLSTMmodel
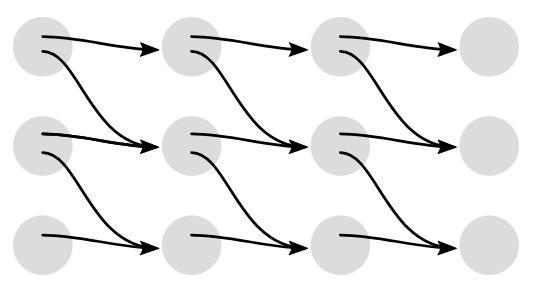
CTC is a neural network which uses associated scoringfunctionstotrainrecurrentnetworkssuchasLSTM, GRUtotacklesequenceapplicationswheretimeisvariable. CTC is differentiable with output probabilities from the recurrent network, since it sums the score of each alignment(Figure 4), gradient is computed for the loss
3.3. ABSTRACTIVE SUMMARIZATION
Theabstractivesummarizationisachievedbyusing sequence to sequence models recurrent networks, LSTM, GRUarefirmlyestablishedintextsummarization.Theusage ofthesemodelsrestrictstheirpredictioninshortrange.In contrast, transformer networks allows to capture longer range.Weusedself-attentionnetworkasabuildingblockfor transformers with embedding layer for word embeddings and positional encoding for positional embeddings since positionalembeddingsworksforvariablesentences.
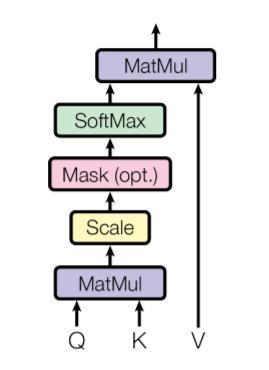
ScaledDot-ProductAttention
The word embedding along with its position are passedtotheencoderwhereattentionmechanismisused (Figure5)tolearnbymappingaqueryandasetofkey-value pairstoanoutputvector.Thebasicideaisthat,ifthemodel is aware of the abstract, then it provides high level interpretationvectors.
A decoder with similar architecture mentioned in encoder is used to obtain the output prediction using the interpretedvectors.
3.4. EXTRACTIVE SUMMARIZATION
The extractive approach involves picking up the significant phrases from the given document, which is
achieved by creating a sentence graph and measuring the importance of each sentence within the graph, based on incoming relationships. The value of the incoming relationshipsaremeasuredusingcosinedistancebetween sentence embeddings. The created graph passed into the PageRankalgorithmtorankthesentencesinthedocument.
The dimensions for the word embeddings are empiricallysetto100.
Fig-7: Outputwithoutlocationalawareness

The encoder converts the character sequence to characterembeddingwithdimension512whicharepassed throughbi-directionalGRUlayercontaining512units(256in each direction) to generate the encoded features. The encodedfeaturesareconsumedbythedecodermodelwhich containstwolayerofautoregressiveGRUof1024unitsand an attention network with dimension 128. The attention networkisrepresentedbythebelowequation.
a(st-1,hi)=vT tanh(W1hi+W2St-1 +W3(conv(a(st-2,h)))
3.5. ALIGNER – INTERMEDIATE FEATURE REPRESENTATION
Converting text(200 tokens) to audio waveform(200K tokens) is not possible. So we chose low levelintermediaterepresentation:mel-spectrogramtoactas a bridge between the aligner and the vocoder. Melspectrograms scale down the audio to 256x times. Melspectrograms are created by applying short-time Fourier transform (STFT) with a frame size 50ms and hop size 12.5ms and STFT is transformed to mel-scale using 80 channel mel-filterbank followed by log dynamic range compression, because humans respond to signals logarithmically.
Sincethedimensionofspectrogramsaremorethan thedimensionoftext,sequencetosequencemodelisused Themodelconsistsofencoderanddecoderwithattention andlocational awareness.Attentionmechanismisused to handle long range sequences. Experiments without locationalawarenessproducemadethedecodertorepeator ignoresomesequences(Figure7).
wherearepresentstheattentionscores, srepresentsthedecoderhiddenstates, hrepresentstheencoderhiddenstates, W1,W2,W3 representsthelinearnetwork, convrepresentstheconvolutionnetworktoextract featuresfromtheattentionscores.
Theconvolutionnetworkforlocationalawarenessis builtwithkernelsize31anddimension32.
A pre-net is built using feedforward network to teacher-force the original previous timestamp to the decoder.Experimentswithdimension128and256madethe decoderaltertheinputratherthanattendingtheencoded features.Dimension64withhighdropouts(0.5)forcedthe decodertoattendtheencodedfeaturesbecausethereisno full access to the teacher-forced inputs. This makes the decoderpredictcorrectlyevenifthereisaslipinthecurrent timestampinput(previoustimestampoutput)
The output from the decoder is passed through featureenhancernetworktopredictaresidualtoenhance the overall construction of spectrogram which consists of fourlayersofresidualnetworksofdimension256withtanh activation and dropouts are added at each layer to avoid overfitting. We minimize the mean squared error (MSE) frombeforeandaftertheenhancertoaidconvergence.
3.6. VOCODER – GANS
Converting spectrograms to time domain waveforms auto-regressively is a tedious and time consumingprocess.
3.6.1. GENERATOR
Aspectrogramisapproximately256xsmallerthan theaudio. AGenerativemodel isbuiltusing(8x,8x,2x,2x) up-sampling. Experiments were carried to find the best scaling factors to attain 256x. Firstly, a feature extractor networkisusedtoextractfeatureswithakernelsize7and dimension512tofeedtheup-samplinglayers.Up-sampling layer network consists of transposed convolution with its correspondingscalefactorandsomeconvolutionalnetworks to increase the receptive field. Experiments are made for increasingthereceptivefield,aftertransposedconvolution thereceptivefieldwouldbelow.Receptivefieldofastackof dilatedconvolutionincreasesexponentiallywithnumberof layers,whilevanillaconvolutionsincreaseslinearly.
The stack dilation convolution consists of three dilatedRESNETswithkernelsize5anddilations1,5,25.The receptive field of the network should look like a fully balanced symmetric tree with kernel size as the branch factor.Finally,convolutionallayerisusedtopredictthefinal audio(dimensionofsize1)andantanhactivationfunction.
3.6.2. DISCRIMINATOR
Discriminators are used to classify whether the given sample is real or fake. We adopt a multiscale discriminatortooperateondifferentscalesofaudio.Feature PyramidNetworks(Figure2)areusedtoextractfeaturesat different stages on scale 2x,4x,8x with kernel size 15 and dimension64.Thefeaturesfromeachstagearepassedtothe discriminatorblock.
Eachdiscriminatorblocklearnsfeaturesofdifferent frequencyrangeoftheaudiobystackofconvolutionallayers withkernelsize41andstride4andafinallayertopredict thebinaryclass(real/fake).
4. EXPERIMENTS AND RESULTS
4.1. TRAINING SETUP
I. SegmentationmodelwastrainedonRobustReading CompetitionchallengesdatasetslikeDocVQA202021,SROIE2019,COCO-Text2017whichcontained document image dataset along with their coordinatesofthewords.
II. Recognitionnetworkwastrainedusingtwomajor syntheticdatasets.MJSynth(MJ)whichcontains9M word boxes. Each word is generated from a 90K English lexicon and over 1,400 Google Fonts. SynthText is generated for scene text detection containing7Mwordboxes.Thetextsarerendered ontoscenearecroppedandusedfortraining.
III. Summarization model was trained using two different datasets. The inshorts dataset which contains news articles along with their headings. CNN/DailyMail non-anonymized summarization dataset.Itcontainstwofeatures.Oneisthearticle which contains text of news articles and the highlights which contains the joined text of highlightswhichisthetargetsummary.
IV. Ourtrainingprocessinvolvedtrainingthefeature prediction network followed by training the vocoder independently. This was predominantly done using the LJ speech dataset consisting of 13,100shortaudioclipsofasinglespeakerreading passages from 7 non-fiction books which also includesatranscriptionforeachclip Thelengthof theclipsvaryfrom1to10secondsandtheyhavean approximatelengthof24hoursintotal.
4.2. HARDWARE AND SCHEDULE
WetrainedourmodelsonNVIDIAP100GPUsusing hyper-parameters described throughout the paper. We trained the segmentation, recognition, summarization models for 12-24 hours(approx.) each. Feature prediction andvocoderweretrainedfor1-2weeks(approx.)each
4.3. OPTIMIZERS AND LOSS
Table-1: Optimizersandlossusedtotraindifferent models
4.4. EVALUATION
We evaluated the OCR model(segmentation + recognition)withrealtimescenetextimages.Wecompared themodelwithtesseractandEasyocrenginesandachieved better results than them. Sample results of this model is showninFigure8.
Fig-8: ResultofOCR
During the evaluation of transformers, after converting the source text into encoded vectors and modellingthesummarizedtext,duringinferencemode,the groundtruthtargetsarenotknown.Therefore,theoutputs fromthepreviousstepispassedasaninput.Incontrastto the teacher-forcing method used while training. We randomly selected 50 samples from the test dataset and evaluated the model. The context between the each evaluatedresultandthegroundtruthweresimilar.Sample resultsofthismodelisshownbelow
Sample Result-1:
Source: summstartridehailingstartupubersmainrivalin southeastasia,grabhasannouncedplanstoopenaresearch anddevelopmentcentreinbengaluru.thestartupislooking tohirearound200engineersinindiatofocusondeveloping itspaymentsservicegrabpay.however,grabsengineering vp arul kumaravel said the company has no plans of expandingitsondemandcabservicestoindia.summend
Model output : summstartubertoopenresearchcentrein bengalurusummend
Ground truth : summstartuberrivalgrabtoopenresearch centreinbengalurusummend
Sample Result-2:
Source: summstartwrestlersgeetaandbabitaphogatalong with their father mahavir attended aamir khan s 52nd birthday celebrations at his mumbai residence. dangal is based on mahavir and his daughters. the film s director niteshtiwariandactorsaparshaktikhurrana,fatimashaikh andsakshitanwarwerealsospottedattheparty.shahrukh khan and jackie shroff were among the other guests. summend
Model output: summstart geeta babita phogat attend birthdaypartyslagaaamirsummend
Ground truth: summstartgeeta,babita,phogatfamilyattend aamirsbirthdaypartysummend
Generatingspeechduringinferencetopredictthe nextframe,theoutputfrompreviousstepistakenasinputin contrast to teacher-forcing, we generate random text sequences evaluated on the model. The spectrograms predictedfromthemodelisconvertedtoaudiousinggriffinlimalgorithmtocheckthemappingofcharacterembeddings tothephonons,ignoringthequalityofthespeech.
Generativevocoderisusedtogeneratehighquality speechfromthespectrogram.Thesynthesizedaudioisrated in respect to their clarity and natural sounding speech. A sampleevaluationofthismodelisshownbelow.
Sample input:
For although the Chinese took impressions from wood blocks engraved in relief for centuries before the woodcuttersoftheNetherlands,byasimilarprocess.
Sample output:
5. CONCLUSIONS

These models segmentation, text recognition, extractiveandabstractivesummarisation,spectrogramand speechsynthesisaretargetedatsummarisingthecontentin theimagegivenandthenconvertingitintoaudio.Withthese models,theuserwillhaveover90%accuracyinconverting theimagewithtextintoaudio.
To handle a wide range of words, wecan add the entireEnglishvocabularywhichrequireshighperformance GPU’s. We have trained the models only with English language.Further,themodelscanbetrainedwithdifferent languagesforwiderusage.Asofnow,theOCRmodeldeals with a specific professional style of font. This could be furtherimprovedbytrainingitwithfontsofdifferentstyles. The audio output could be made more human-like by trainingthemodelmorevigorously.

ACKNOWLEDGEMENT
We extend our gratitude to the Department of Computer Science and Engineering, PSG College of Technologyforsupportingusthroughouttheresearchwork.
REFERENCES
[1] AshishVaswani,NoamShazeer,NikiParmar,Jakob, Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin, “Attention is all you need”, 2017, In Advances in Neural Information ProcessingSystems,pages6000–6010.
[2] K.U.Manjari,"ExtractiveSummarizationofTelugu DocumentsusingTextRankAlgorithm,"2020Fourth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), 2020, pp. 678-683,doi:10.1109/I-SMAC49090.2020.9243568.
[3] Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang, “Real-time Scene Text Detection with Differentiable Binarization”, 2020, Proc.AAAI.
[4] Baek, Jeonghun and Matsui, Yusuke and Aizawa, Kiyoharu, “What If We Only Use Real Datasets for Scene Text Recognition? Toward Scene Text Recognition With Fewer Labels”, IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR),2021.
[5] E.Variani,T.Bagby,K.Lahouel,E.McDermottandM. Bacchiani, "Sampled Connectionist Temporal Classification,"2018IEEEInternationalConference onAcoustics,SpeechandSignalProcessing(ICASSP), 2018, pp. 4959-4963, doi: 10.1109/ICASSP.2018.8461929.
[6] J.Shenetal.,"NaturalTTSSynthesisbyConditioning Wavenet on MEL Spectrogram Predictions," 2018 IEEEInternationalConferenceonAcoustics,Speech and Signal Processing (ICASSP), 2018, pp. 47794783,doi:10.1109/ICASSP.2018.8461368.
[7] A.Creswell,T.White,V.Dumoulin,K.Arulkumaran, B. Sengupta and A. A. Bharath, "Generative AdversarialNetworks:AnOverview,"inIEEESignal Processing Magazine, vol. 35, no. 1, pp. 53-65, Jan. 2018,doi:10.1109/MSP.2017.2765202.
[8] K. N. Haque, R. Rana and B. W. Schuller, "HighFidelity Audio Generation and Representation LearningWithGuidedAdversarialAutoencoder,"in IEEEAccess,vol.8,pp.223509-223528,2020,doi: 10.1109/ACCESS.2020.3040797.
[9] R. Dey and F. M. Salem, "Gate-variants of Gated RecurrentUnit(GRU)neuralnetworks,"2017IEEE 60thInternationalMidwestSymposiumonCircuits andSystems(MWSCAS),2017,pp.1597-1600,doi: 10.1109/MWSCAS.2017.8053243.