One Stop Recommendation
Shloka Ramesh Daga1 , Bhavesh Bholanath Maurya2 , Chiragkumar Shalendra Maheto3 , 4Kaajal Sharma1MCT Rajiv Gandhi Institute of Technology, University of Mumbai

2 MCT Rajiv Gandhi Institute of Technology, University of Mumbai.
3MCT Rajiv Gandhi Institute of Technology, University of Mumbai.
4MCT Rajiv Gandhi Institute of Technology, University of Mumbai.
Abstract –
Currently, recommender systems are one of the most promising strategies for online businesses that specialize in services and goods related to the Internet. The business models of Google, YouTube, Facebook, LinkedIn, and Amazon are typical instances of how these recommender systems are fundamental to their operations. A category of information filtering systems are recommender systems. These systems are specialized software parts that are typically included in bigger software systems but may also beusedindependently.
A category of information filtering systems are recommender systems. These systems are specialized softwarepartsthataretypicallyincludedinbiggersoftware systems but may also be used independently. The primary objective of a recommender system is to offer the user software ideas for things that might be useful. The advice relates to many approaches for making decisions, such as which product to buy, which movie to watch, or which vacationto book. The initiative primarily aids in suggesting titles of films and television shows from various OTT platforms including Netflix, Amazon Prime Video, and Hotstar. The project essentially unifies many recommendationsystemsontoasingleplatform.
Key Words:
Recommendation Model, OTT Platform, Netflix, Amazon Prime Video, Hotstar, Streaming Platform, Dashboard .
1.INTRODUCTION
Thefiltering procedure becomes essential whenthere are a lot of users on a system and a lot of stuff to provide for them. Nobody can reasonably expect a user to manually shift through tens of thousands or even millions of different items whether they are movies, goods, or news inordertodiscoverwhatheislookingfor.Without recommendations, consumers would only be exposed to direct search results, which in cases when there are a lot ofitems,wouldonlyreturnafewtensorevenhundredsof
items if the user looked through several pages. Even on smaller news or e-commerce websites with wellorganized product categories, there may be too many items fora user tosortthroughinorder todiscover what they are looking for. In terms of design, recommender systems typically only focus on a single sort of item, such as movies or music, and both its primary suggestion mechanismandgraphicaluserinterfacearespecializedto thatparticulartypeofitem.Becauserecommendationsare typically created by taking into account the distinctive qualities of the users, different people or groups of users receive different suggestions. It is simpler to make nonpersonalized recommendations, which are primarily foundinpublicationsornewspapers.
Usersmayfindsomeparticulargoodsthatasystemhasto offer intriguing, but if the system offers too many items, they may never learn about them. The recommender's objective is to present the user with a fresh selection of optionsthattheymightnothavediscoveredontheirown.
1. ContentBasedFiltering
Content-based filtering's fundamental tenet is that every item has certain characteristics. A model or user interest profile of the user's interests is created by recommender systems using a content-based recommendation strategy to analyse a set of documents and/or descriptions of products that the user has previously evaluated. Users havea setofpreferencesconnectedtothecontentsofthe items. A profile might be specifically constructed by the user or built automatically based on his or her prior behaviours. The user's interests are organized into a profile, which is then utilized to suggest new, intriguing stuff. Comparing the features of the user profile with the attributesoftheitemishowthesuggestionprocessworks. The result is a relevance score, which reflects the user's level of interest in the particular item. A user profile's abilitytoaccuratelypredictauser'sinterestsisextremely beneficial to the efficiency of an information retrieval operation.
2. CosineSimilarityBasedRecommendation
Here,weusetheCosineSimilarityfunctiontocalculatethe cosine similarity. Regardless of size, the cosine similarity metriccanbeusedtoassesshowsimilartwopapersare.It mathematically calculates the cosine of the angle formed by two vectors cast in a multidimensional space. Even if twocomparabledocumentsareseparatedbytheDistance measure(takingintoaccountthesizeofsuchdocuments), theyarelikelyto beorientatedclosertogetherbecause of thecosinesimilarity.Theangleisnarrowerthehigherthe cosine similarity. Applications for text matching, informationretrieval,anddata miningall makeuseofthe measure. A typical approach in information retrieval is to use weighted TF-IDF and cosine similarity to quickly locatedocumentsthataresimilartoasearchquery.
TF-IDF Vectorizer Text vectorization is the process of converting text into a quantitative feature. It compares a phrase's "relative frequency" in a document to the consistency of that term across all papers. The TF-IDF weight shows a phrase's relative importance in the document and throughout the corpus. Phrase Frequency (TF) is a measure that displays how frequently a phrase appearsinadocument.Duetodocumentsizedisparities,a term may appear more frequently in a large document than in a short one. As a result, the document's length is usuallyseparatedbytermfrequency.TF-IDFisamongthe most extensively used text vectorizers, and the computation is straightforward. It distinguishes between the uncommon word heavier weight and the more frequenttermreducedweight.
2.RELATED WORKS
The paper presents the development and the comparison of multiple recommendation systems[1], capable of making item suggestions, based on user, item, and useritem interaction data, using different machine learning algorithms[4]. Also, the paper deals with finding different ways of using machine learning models to create recommendation systems, training, evaluating, and comparingthe differentmethodsto providea general but accuratesolutionforrankingprediction.
In this paper, they propose a deep learning approach basedonautoencoderstoproduceacollaborativefiltering system that predicts movie ratings for a user based on a large database of ratings from other users, using the MovieLensdataset.Weexploretheuseofdeeplearningto predict users’ ratings on new movies, is difficult to patch through and requires high end systems to perform the tasks[3].
3. DATASET
The Netflix, Prime Video, and Hotstar movie data were acquired via Kaggle, each of which contained more than 5000entries,whilethedatafortheanalysiswasextracted using Google forms and the majority of the analysis was performed on the data that was collected using our own Google form. The main goal of using a google form to gather information is to learn people's preferences for streamingservices,whichwillhelpusfindtheanswerthat our project is trying to provide. Additionally, the public dashboard for the project includes a link to the google form so that anyone using the dashboard can voluntarily fill out the form and contribute to attaining a better accuracyintheresultsprovided.
NetflixDataset
The Netflix Dataset comprises of more than 9000 data entries.
AmazonPrimeDataset
The Amazon Prime Video dataset consists of more than 9000dataentries.
HotstarDataset
The hotstar dataset consists of more than 6000 unique data.
GoogleFormDataset
TheGoogleformdatasetisalivedatasetwhichisincluded inthedashboard,sowhenevernewentriesareincludedin the google sheet, it gets automatically updated on the dashboard.
4.PROPOSED SYSTEM
The current recommendation system suggests only movies, but in this project, we would suggest movies and television series for several OTT platforms including Netflix, Prime Video, and Hotstar. We would be creating a dashboard with many screens, each of which would feature a different OTT platform. We would gather data using Google Forms as well as different websites, such as Kaggle. In essence, it serves as a single platform to obtain movie suggestions for various OTT services. With its highly dynamic graphs and charts that can be hovered as needed, the project's suggested solution would also assist usersinderivingpracticalinsightsfromthedata.
Chart-1:WorkflowDiagram
Wewillobtaintheproject'sdatasetfromKaggle,andwe'll also use Google Forms to gather user information. The Kaggle dataset will be utilized for content-based and matrix-based recommendations, while the data from Google Forms will be used for collaborative recommendationsystems.
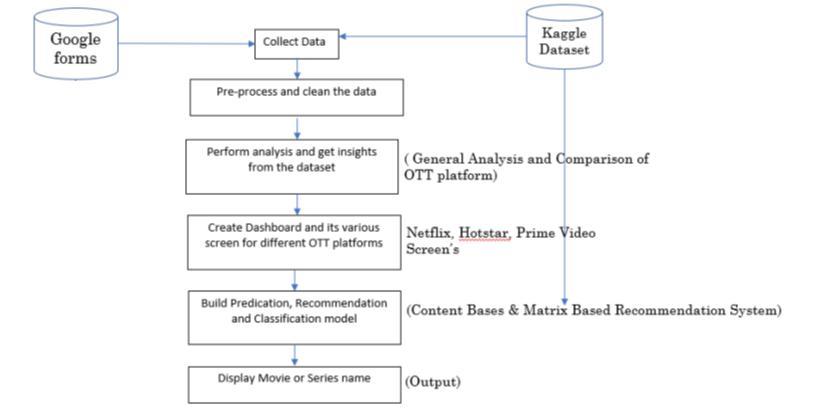
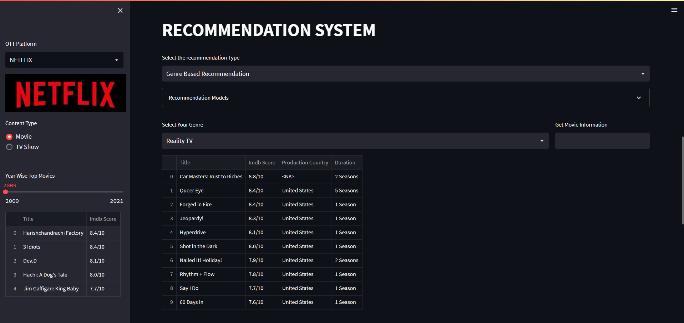
Data pre-processing will be carried out after data collection. Pre-processing would be followed by OTT platform-specificanalysisoneachscreeninordertoglean some actionable insights from the interactive charts. For each OTT platform, such as Netflix, Prime Video, and Hotstar, there would be a separate screen on the dashboard.
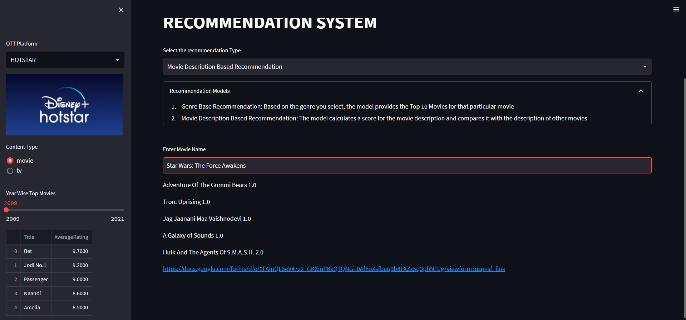
Thecustomerwillhavethechoicetoreceiveseveraltypes of recommendations for each OTT platform depending on their needs. The models will calculate the input when the user offers it, and depending on the results, they will recommendmoviesasinput.
A variety of recommendation models are included in the project.1.Content-DependingRecommendation:Theuser willreceiverecommendationsforalistofmoviesbasedon their favourite genre. Using the genre name as input, the model will output the top films according to their IMDb scores.2.Matrix-BasedRecommendations:Inthismethod, the model compares the user-provided movie description to the descriptions of other films to determine which five films most closely fit the user's description. 3. Collaborative Recommendation: In this case, the model will suggest or recommend a movie or TV show by giving itstitlebasedonthepreferencesofotherindividualswho preferasimilargenre.
5.ANALYSIS
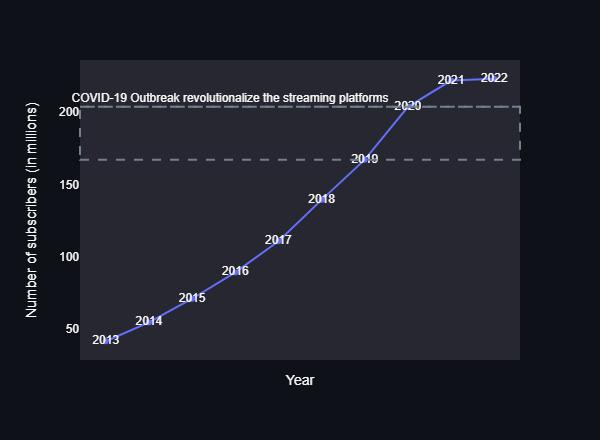
The dashboard Analysis Page's information was gathered through Google Forms, and it includes graphs that demonstrate how the number of OTT subscribers increased significantly during the COVID19 outbreak. The analysis unmistakably demonstrates that COVID19
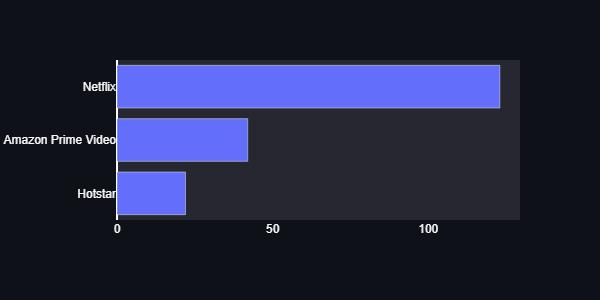
revolutionized the use of streaming platforms, and that thisusehasgrowntothepointwheremorepeoplechoose to see new movies on streaming platforms than in actual cinemas. Even with its higher prices, Netflix continues to be the most popular streaming platform. Those who do not like Netflix may not like it because it has more expensive subscription costs than other streaming services. The dashboard can also be helpful for a director who wants to choose what kind of film to make based on the audience's age or gender, as the projects help to deal withthisissueaswell.
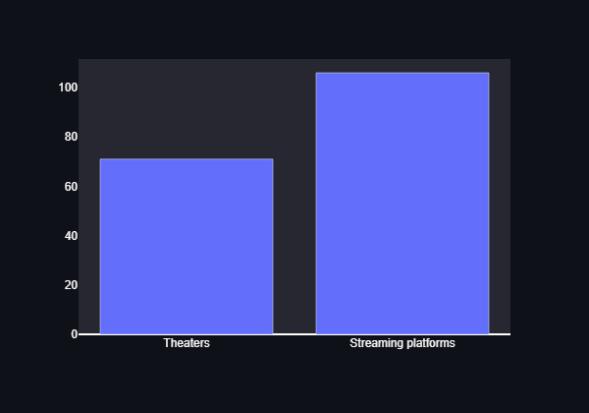
This finding is corroborated by another graph that demonstrates how people now prefer to watch newly released films on OTT platforms rather than going to theatres. The project's dashboard also displays the most popular streaming services, including Netflix, Amazon Prime Video, and Hotstar. Other significant questions are includedinthegoogleformandareusedinthedashboard to help the audience understand the information and insights. The primary goal of utilizing Google Forms to collect data is to enable more accurate results and conclusions by taking into account the preferences that individualscurrentlyhold.
6. CONCLUSIONS
New possibilities for finding personalized information on the Internet are made possible by recommender systems. Italsoenablesuserstoaccessgoodsandservicesthatare not immediately available to users on the system, which helpstorelievetheissueofinformationoverload,whichis a fairly typical situation with information retrieval systems.Wehavedevelopedarecommendationalgorithm forNetlfix,PrimeVideo,andHotstarthatcansuggestfilms and television shows based on a user's affinity for a particulargenre.Themodelsalsomakerecommendations forfilmsthatarecomparabletothemoviedescriptionthat users enter in the input area. Additionally, our dashboard offers a thorough picture of how Covid19 contributed to the era of streaming platforms, as well as information on which OTT platform users prefer, how much time they spendthere,andtheirpreferredgenres.
REFERENCES
G.C. Capelleveen, C. Amrit, D.M. Yazan, W.H.M. Zijm, “The recommender canvas: A model for developing and documenting recommender systemdesign”.Expertsystemswithapplications, pp.97-117,2019.
F. Ricci, L. Rokach, B. Shapira, Introduction to Recommender Systems Handbook. Boston, Massachusetts, United States of America: Springer,2010.
Y. Lim, “A Primer to Recommendation Engines”, Sep10,2019
By Daniil Korbut, Statsbot, “Recommendation SystemAlgorithms:AnOverview”,Jan.2022.
Richmond Alake, “Understanding Cosine Similarity And Its Application: Understand the basics behind a technology that is used across differentfieldsanddomainsofMachineLearning” Sep.15,2020
Mukesh Chaudhary, “TF-IDF Vectorizer Scikitlearn: Deep understanding of TF-IDF Calculation by Various examples, why is so Efficiency than otherVectorizerAlgorithm,Apr.24,2020.
Plotly, “Introducing Plotly Express”, Marc. 20, 2019.
Andy McDonald, “Getting Started with Streamlit Web Based Application: A gentle Introduction To CreatingStreamlitWebapps”,May23,2022.