
Volume: 10 Issue: 03 | Mar 2023 www.irjet.net p-ISSN:2395-0072

Heart disease classification using Random Forest
Arpit Gupta, Ankush Shahu, Masud Ansari, Nilalohit Khadke, Prof. Ashwini Urade
Students, Department of Computer Science J D College of Engineering and Management Nagpur, India Professor, Department of Computer Science J D College of Engineering and Management Nagpur, India ***
Abstract: Cardiovascular disease is still the leading cause of death worldwide, and the early prediction of heart disease is of great importance. In this paper, we propose a supervised learning algorithm for early prediction of heart disease using old patient medical records and compare the results with a well-known supervised classifier – Random Forest. Patient record information is classified using a CNN (Cascade Neural Network) classifier. At the classification stage, 13 features are provided as input to the CNN classifier to determine heart disease risk. The proposed system will help doctors diagnose diseases more efficiently. The effectiveness of the classifier was tested on 303 patient records. The raw data comes from a combination of 4 databases: Cleveland, Hungary, Switzerland and VA Long Beach data from the UCI Machine Learning Repository. This result suggests that CNN classifiers can more effectively predict the likelihood of heart disease. The proposed method allowed the model to achieve an accuracy of 95.17% in predicting heart disease. Experimental results show that our algorithm improves theaccuracyofheartdiseasediagnosis.
Keywords: Random forests, heart disease prediction, Machinelearning.
I. INTRODUCTION
Many medical data records created by medical professionals are available for analysis. Data mining techniques are methods of extracting valuable and hidden information from large amounts of available data. Medical databases consist mostly of fragmentary information. Therefore, making decisions usingdiscrete data sets becomes a complex and difficult task. Machine learning (ML), as a subfield of data mining, can efficiently handle well-structured large-scale datasets. In medicine, machine learning can be used to diagnose, detect and predict variousdiseases.
Themainpurposeofthisarticleistoprovideatool to help doctors detect heart disease at an early stage. This will help to effectively treat patients and avoid serious consequences. ML plays a very important role in detecting hidden discrete samples and thus provides data analysis. Afteranalyzingthedata,machinelearningtechnologyhelps predictheartdiseaseandmakeearlydiagnosis.Thisarticle presents an analysis of the performance of random forest techniquesinthepredictionofearlyheartdisease.
II. RELATED WORK
BackgroundResearch:
Applying ML classifiers on ECG dataset for predicting heart disease
IEEE,2021
AdibaHossain SabitriSikder
Current SVM model has 85.49% accuracy.Infuture,more analysis can be performed with the different combinations ofalgorithmstoobtaina better heart disease predictionmodel.
Ahealthylifestyleandearlydetectionaretheonly ways to prevent heart disease. The greatest challenge in healthcaretodayistoprovidethehighestqualityofservice and accurate and efficient diagnosis. Although heart disease has proven to be the leading cause of death worldwide in recent years, it is also a disease that can be effectively controlled and managed. Any precision in the management of diseases depends on the right timing of these diseases. The proposed work attempts to detect these heart diseases early enough to avoid catastrophic
The human heart is the main organ of the human body.Anytypeofdisturbanceinthenormalfunctioningof the heart can be classified as heart disease. In today's modernworld,heartdiseaseisoneoftheleadingcausesof mostdeaths.Heart disease canbecaused byanunhealthy lifestyle, smoking, drinking alcohol, and eating too much fat.AccordingtotheWorldHealthOrganization,morethan 10 million people worldwide die of heart disease every year. outcomes.
©
Using machine learning to predict heart disease
Latest trends of heart disease prediction using ML and image fusion
CCLAUSA, 2022 NikhilBora
Elsevier,2020
ManojDiwakar
P.Singh
Thelowestaccuracywas from Naïve Bayes of 79.83% against highest accuracyof94.12%from RandomForest.
Quality of dataset is an important factor, and thus hospitals should be encouraged to publish highqualitydatasets.
Heart Disease Prediction
IRJETS,2022
NakkinaRajjani
Thescopeistocheckthe availability of heart disease with fewertasks and attributes that gives highaccuracyand efficiency.
Title Publication, Year Research Gap
Random forest swarm optimization for heart diseases diagnosis
Machine Learning Models for prediction of co-occurrenceof diabetes and cardiovascular diseases
Prediction of Heart Disease utilising SVM andANN
Improving the prediction of Heart Failure Patients’ Survival using SMOTE and Data Mining Techniques
Elsevier,2021
Shahrokh Asadi Michael Kattan
Springer, 2022
Ahmad
Abdalrada
JemalAbawajy
IJEECS,2021
AlaaKhaleel Faieq
IEEE,2021
AbidIshaq, Muhammad Umer
III. METHODOLOGY
Manyothermulti-objective optimization methods appear in the literature such as non-dominated genetic algorithm ii which canbeemployedinsteadof MOPSO.
The model has high accuracy and in the future, itcanbeemployedasatool for web-based and mobile phone application, thus increasing its reach among people and healthcare providers
SVMisemployedcurrently. While in the future, other techniques can be applied to predict other heart diseases using the same data
To improve the performanceofMLmodels, better features selection techniques can be devised In this case, metaheuristics can be used due to NP-hard nature of featureselectionproblems.
A. Data Collection and Preprocessing
The dataset used is the Cardiology dataset, which is a combination of 4 different databases, but only the UCI Cleveland dataset was used. The database contained a totalof76traits,butallpublishedtestsonlyreferenceda subset of 14 traits. Therefore, we use the UCI Cleveland processing dataset available on the Kaggle website for analysis.Table1belowgivesa fulldescriptionofthe14 attributesusedintheproposedwork.
TABLE I. FEATURES SELECTED FROM DATASET
1.
Age- represent the age of a person Multiplevalues between29&71
2. Sex- describe the gender of person(0-Feamle,1-Male) 0,1
3.
CP- represents the severity of chestpainpatientissuffering. 0,1,2,3
RestBP-Itrepresentsthepatient’s BP Multiplevalues between94&200
4.
5.
6.
7.
8.
9.
10.
Chol-It shows the cholesterol levelofthepatient. Multiplevalues between126& 564
FBS-It represent the fasting bloodsugarinthepatient. 0,1
Resting ECG-It shows the result ofECG 0,1,2
Heartbeat- shows the max heart beatofpatient Multiplevalues from71to202
Exang-usedtoidentifyifthereis an exercise induced angina If yes=1orelseno=0
0,1
OldPeak-describes patient’s depressionlevel Multiplevalues between0to62
11 Slope- describes patient conditionduringpeakexercise.It is divided into three segments(Unsloping,Flat,Down sloping)
1,2,3
12 CA-Resultoffluoroscopy. 0,1,2,3
13 Thal- test required for patient suffering from pain in chest or difficultyinbreathing.There are 4kindsofvalues whichrepresentThalliumtest
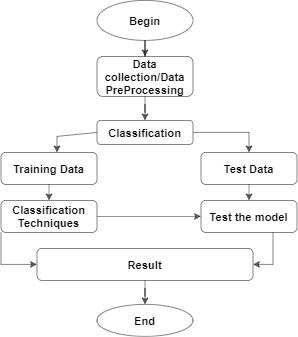
Proposed Model: Fig. 1 shows the entire process involved.
Target-It is the final column of the dataset It is class or label Colum Itrepresentsthenumber
0,1,2,3
0,1
14 ofclassesindataset Thisdataset has binary classification i.e. two classes (0,1)In class “0” representthereislesspossibility of heart disease whereas “1” represent high chances of heart disease
The value “0”Or“1” dependsonother13attribute
Dataexploration,alsoknownasexploratory data analysis (EDA), is an essential step in the machine learning process. It involves analyzing and understandingdatasetstobetterunderstandthedata and identify patterns, relationships, and anomalies. While exploring data, we use a variety of statistical and visualization techniques to summarize and describedata.Thesetechniquesinclude:
1) Descriptive statistics: the mean, median, mode, standard deviation, correlation and other statisticsareusedtosummarizethedata.
2) Data Visualization: Histograms, scatter plots,boxplots,heatmaps,andothervisualizationsare used to visually explore data and identify patterns andtrends.
3) Dimensionality reduction: Use principal component analysis (PCA), t-SNE, and other techniquestoreducethedimensionalityofthedataset andvisualizeitinalow-dimensionalspace.
4) Outlier detection:Identifyandanalyzeoutliersto determineiftheyaretruedatapointsorfalsedata points.
model.Performanceiscalculatedandanalyzedbasedon different metrics used, such as accuracy, precision, retrievability,andF-score.
C. Training data using random forest
Random Forest: Random Forest is a popular machine learning algorithm used for classification, regression, and other tasks. An ensemble learning method that combinesmultipledecisiontreestomakemoreaccurate predictions. In random forests, a set of decision trees is createdonarandomsubsetoftheoriginaldataset.Each decisiontreeintheforestisbuiltusingadifferentsubset of features and training examples. The process of buildingeachtreeisrepeateduntilthespecifiednumber oftreeshavebeencreated.
To predict the use of a random forest, we walk through each tree in the forest and make a classification or regression decision. The predictions from each tree are then combined to form the final prediction. The combined prediction is done by majority vote (in classification)orbyaverage(inregression).
The advantages of random forest algorithm are:
1) High accuracy: Random forests are known for the highaccuracyoftheirpredictions.
2) Robustness: Random forests are less prone to overfitting thanindividualdecisiontrees.
3) Ease of use: Random Forest does not require extensivedatapreparationandcanhandlemissingdata.
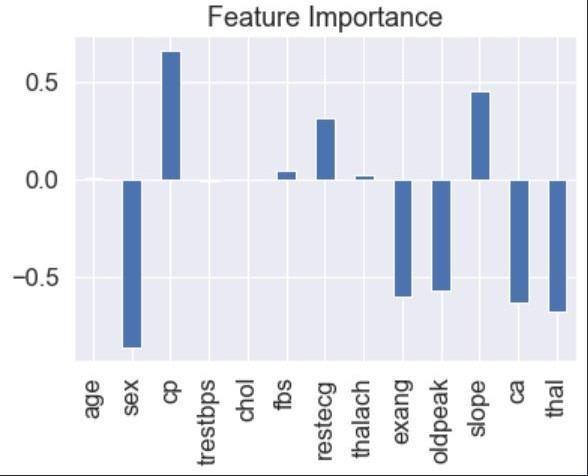
4) Feature Importance: Random forests provide a measureoffeatureimportancethatcanhelpidentifythe mostimportantfeaturesforprediction.
Optimizing the accuracy of the model: The initial predictions of the model are not always correct. To further improve accuracy and precision, we performed thefollowingsteps:
Figure1:FeatureImportance
B. Classification:
The input dataset is split into 80% of the training dataset and the remaining 20% of the test dataset. Trainingdataset
isthedatasetusedtotrainthemodel.Thetestdataset is used to verify the performance of the trained
1) Hyperparameter tuning: Hyperparameter tuning is theprocessofselecting the bestset ofhyperparameters for a machine learning model. Hyperparameters are parametersthatare notlearnedduring training, butare set before training begins, such as the learning rate, the strengthofregularization,orthenumberofhiddenunits inaneuralnetwork.
Hyperparameter settings are important because model performance depends on the hyperparameters chosen. We do this through trial and error by training models with different combinations of hyperparameters and evaluatingtheirperformanceonthevalidationset.
We automate this using techniques such as grid search, randomsearch,orBayesianoptimization.
Proper tuning of hyperparameters can significantly improve the performance of a machine learning model,whileimpropertuningcancausethemodelto performpoorlyorevenfailcompletely.
2) Confusion matrix: A confusion matrix is a table that summarizes the performance of a classification model on a set of test data whose true values are known. It is a way to visualize the performance of machine learning algorithms by comparing predicted and actual values. The confusion matrix is typically a 2x2matrixforbinaryclassification,withfourpossible outcomes:
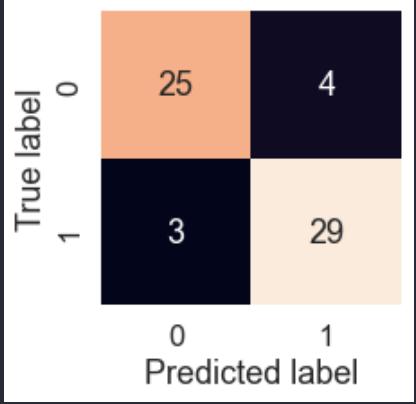
Truepositive(TP):Themodelpredictsapositiveand theactualvalueispositive.
False Positive (FP): The model predicts a positive outcome,buttheactualvalueisnegative.
TrueNegative(TN):Themodelpredictionisnegative andtheactualvalueisnegative.
False Negative (FN): The model predicted negative, buttheactualvaluewaspositive.
Theconfusionmatrixcanbeusedtocalculatevarious evaluation metrics for classification models, such as accuracy,precision,recall,F1score,etc.Thesemetrics provide insight into model performance and help identifyareasforimprovement.
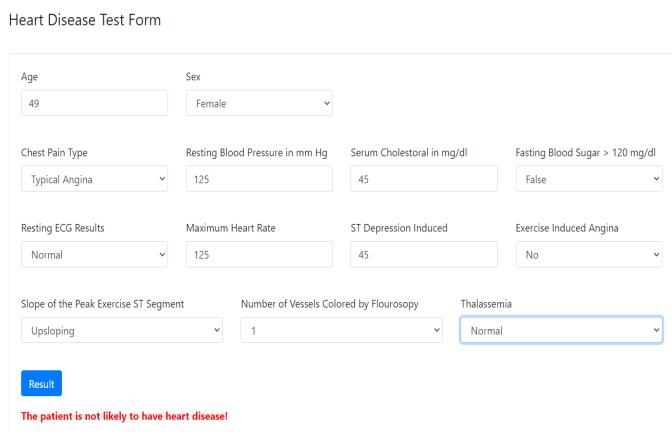
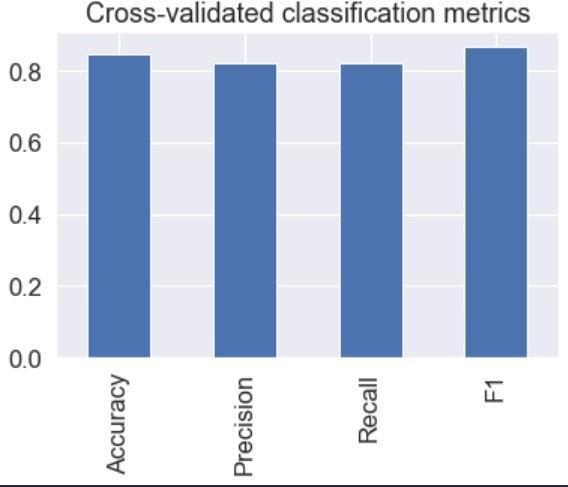
algorithm and using a larger data set than used in this analysis, which would lead to better delivery of results and help health professionals. Heart disease can be predictedeffectively.andefficiently.
D. Result and Analysis:
With the increasing number of deaths from heart
disease, it is imperative to develop an efficient and accurate heart disease prediction system. The motivationforStudy
was to find the most efficient ML algorithm for detecting heart disease. The random forest algorithm achieved86%accuracyinpredictingheartdisease.In thefuture,theworkcouldbeimprovedbydeveloping a web application based on the Random Forest
IV. FUTURE WORK
The quality of the data used to train a model has a significant impact on the final predictions of the model. Future work may involve improving data quality by cleaningandpre-processingthedatamorethoroughlyor collecting more data. Additionally, collecting data from patients of all age groups can lead to significant improvements.Morefine-tuningofhyperparameterscan be performed to help improve model accuracy. Heart diseasecanalsomanifestindifferentways,soclassifiers areconstructedfordifferentoutcomes(eg:heartattack, stroke, cardiac arrhythmia) may be more helpful. This can help develop more targeted interventions and improveoverallhealth.
V. CONCLUSION
In this paper, Random Forest data mining algorithm was implemented to predict heart disease. In the proposed work, weachieveda classificationaccuracy of86.9%forpredictingheartdiseasewithadiagnosis rate of 93.3% using the random forest algorithm. As anextensionofthiswork,differenttypesofclassifiers canbeincludedintheanalysisandfurthersensitivity analysis can be performed. This classifier can also be extended by applying the same data set analysis of other bioinformatics diseases and seeing the performanceoftheseclassifierstoclassifyandpredict these diseases. Cloud computing technology can also be used for the proposed system to manage large volumesofpatientdata.
VI. REFERENCES
1. J. Krishnan Santana; S. Geetha “Prediction of Heart Disease Using Machine Learning Algorithms”. 2019 1st International Conference on Innovations in Information and Communication Technology (ICIICT)Publisher: IEEE
2. Mohan,S., Thirumalai,C.,& Srivastava,G.(2019). “EffectiveHeartDiseasePredictionusingHybrid MachineLearningTechniques”.IEEE Access,1–1. doi:10.1109/access.2019.2923707
3. Rajdhan Apurb, Agarwal Avi, Sai Milan, Ravi Dundigalla, Ghuli Poonam.” Heart Disease Prediction using Machine Learning” INTERNATIONAL JOURNAL OF ENGINEERING RESEARCH&TECHNOLOGY
4. AbdullahAS.“ADatamining Modelforpredicting theCoronaryHeartDiseaseusingRandomForest Classifier”, Proceedings on International Conference in Recent trends in Computational Methods, Communication and Controls (Icon3c); 2012.p.22–5.
5. Kelwade JP. “Radial basis function Neural Network for Prediction of Cardiac Arrhythmias basedonHeartrate”