
Diabetes Prediction Using ML
1Shubham Sain, Dept. of Computer Science Engineering, Maharaja Agrasen Institute of Technology, Delhi, India
2Aayush Singh, Dept. of Computer Science Engineering, Maharaja Agrasen Institute of Technology, Delhi, India
3Dharmender Bhatnagar, Dept. of Computer Science Engineering, Maharaja Agrasen Institute of Technology, Delhi, India
4Assistant Professor Shallu Juneja, Dept. of Computer Science Engineering, Maharaja Agrasen Institute of Technology, Delhi, India ***
Abstract - Diabetes is a chronic condition brought on by either insufficient insulin production by the pancreas or inefficient insulin use by the body. The hormone insulin controls blood sugar levels in the human body. Since, it is a disease for which a cure is yet to be found, it becomes essential to detect the symptoms for diabetes in a patient early on to help manage it before it develops and becomes lethal. For this reason, we will build a prediction model by machine learning techniques which will help us in early prediction of diabetes in a patient or a human with high accuracy of prediction. On a dataset, we will measure the precision accuracy of different models, each built by using different machine learning algorithm and a comparative analysis is done to select the model with a better accuracy.
Key Words: ML, Logistic Regression, KNN, SVC, Decision Tree, Gaussian NB, Random Forest, XGBoost, Ensemble ModelofRandomForestandSVCalgorithms.
1. INTRODUCTION
Diabetes has become a very familiar word in the presentdaysocietyandisamajorprobleminbothdevelopedand developing countries. It is a chronic condition brought on byariseinbloodsugar,mostlybecausethebodyproduces littleornoinsulin,orbecausethecellsstopreactingtothe insulin that is generated in the body. Glucose can be absorbedfrommealsintothebloodcirculationduetothe pancreas' secretion of the insulin hormone. Diabetes is a condition in which there is insufficient production of the insulin caused by the pancreatic dysfunction. Diabetes patients may experience many complications like coma, renal and retinal failure, cardiovascular dysfunction, cerebral vascular dysfunction, peripheral vascular disorders,andpathogeniceffectsonimmunity[1,2].
Uncontrolled diabetes frequently results in hyperglycaemia, which over time severely damages numerousorgans,especiallythenervesandbloodvessels. The number of people with diabetes has risen globally in the previous ten years. There are more than 200 million infected individuals and a 7% yearly increase in the prevalence of diabetes worldwide [3]. There were 425
million diabetics worldwide as of 2017, and a survey by the International Diabetes Federation in 2017 predicted the number will rise up to 625 million by the year 2045 [4]
The four different kinds of diabetes are: Type-1, Type-2, Gestational,andPre-Diabetes.
Type-1diabetes,alsoknownasinsulin-dependent diabetes, is characterized by the absence of insulinproductionbythepancreas.
Type-2diabetes,commonlyknownasnon-insulin dependent diabetes, is characterized by normal insulin production but insulin resistance in the body.
Pregnancy-related diabetes is known as “Gestationaldiabetes”.
Blood glucose levels that are higher than average level but not high enough to be diagnosed as diabetesarereferredtoas"Pre-Diabetes"[5]
Type-1diabetes(T1D)and Type-2diabetes(T2D)arethe two most prevalent forms of the disease. In T1D, insulin insufficiency is brought on by the loss of the pancreatic beta cells, whereas in T2D, it results from inadequate insulindeliverytothecells.Life-threateningconsequences are possible with either kind of the illness. Therefore, in ordertoenhancepatient'squalityoflifeandprolongtheir life span, early identification and prediction of diabetes arecrucialforanyonewhoispronetothedisease[4]
With the use of machine learning, diabetes may be predictedanddetectedearly.Machinelearningisabranch of artificial intelligence that makes use of statistical analysisandisacknowledgedasapromisingfieldthatcan aid in patient categorization or probability prediction regardingthepatient'sdiabetesstatebasedonthedataset ofdiabeticsprovided. The major benefitof thesemethods relies in the algorithms' capacity to learn from the data andapplythatlearningtofuturepredictions.[2]

Numerousbioinformaticsresearchershavemadeaneffort tocombatthisconditionanddevelopprogramsthatwould aid in the prediction of diabetes. Typically, they used different kinds of machine learning techniques, such as classification algorithms, to build prediction models. The most popular algorithms used were Decision Trees, SupportVectorMachine(SVM)andLinearRegression[6]
The performance of five different machine learning classifiersbasedonthek-nearestneighbors(k-NN),radial basis kernel support vector machine (SVM-RBF), artificial neural network (ANN), and multifactor dimensionality reduction (MDR) algorithms and a combined model to predict diabetes in patients has been examined in this research. Combining two or more classifiers is what is referredtoasacombinedmodel.Theycouldcombinetwo ormoreML methodologies,forinstance.Thisstudyoffers athoroughanalysisoftheeffectivenessofseveralmachine learningclassifiers[6,7]
In this study, we applied the following character traits: Number of pregnancies, PG Concentration (Plasma Glucose at 2 Hours in an Oral Glucose Tolerance Test), DiastolicBloodPressure(mmHg),TriFoldThick(Triceps SkinFoldThickness(mm)),SerumInsulin(2-HourSerum Insulin (mu U/ml)), Body Mass Index ((weight in kg)/ ((height in m)^2)), Diabetes Pedigree Function (DP Function), Age (years), Diabetes (Whether or not the personhasdiabetes)[3].
The remaining paper is structured as follows: Literature Review is present in the Section II. The Research Methodology containing the dataset, data pre-processing techniques and the applied machine learning technique are all presented in Section III. The evaluation metrics usedinthisstudyarepresentedinSectionIV.Thevarious experimental results are provided together with an interpretation in Section V. In Section VI, the study is ended with a conclusion and a discussion on future work [1].
2. LITERATURE SURVEY
SeveralresearchershaveutilizedthePimaIndiandiabetes dataset (PIDD) for the prediction of the diabetes using machine learning (ML). The Pima Indian Diabetes dataset (PIDD) has 768 records of female patients described by 9 attributes.
Inthissection,afewstudiesthatarecloselycorrelatedare addressed.
datasets with 80% and 20% records respectively. They applied various Machine Learning algorithms (Logistic Regression, K-Nearest Neighbor, Decision Tree classifier) on the training dataset to train the model to predict the presenceofdiabetesandthentestedthealgorithmsonthe testing dataset. Upon performing the Comparison Evaluation, the classification accuracies of all the algorithms were comparedand it was found that the KNN algorithmhadthehighestclassificationaccuracyof78%on thetestingdataset.
In this study, the authors implemented ML and DL algorithms for the diabetes prediction. The different algorithms that were used in this study were Support Vector Machine (SVM), Random Forest (RF), and Convolutional Neural Network (CNN) algorithms. After analysing the accuracy for all the three algorithms, it was found that the Random Forest (RF) algorithm with an accuracyof83.67%significantlyoutperformedtheSupport Vector Machine (SVM) algorithm with an accuracy of 65.38% and also the DL-based Convolutional Neural Network(CNN)algorithmwithanaccuracyof76.81%.
2.3 Deepti Sisodia, Dilip Singh Sisodia [10]
Theauthorscreatedamodelthatestimatestheprobability ofdiabetes.TheyusedthePimaIndiansDiabetesDatabase (PIDD)availableinaUCIlearningrepositoryforthisstudy. Three different ML algorithms that were used to build thesemodelsaretheSupportVectorMachine(SVM),Naive Bayes (NB), and Decision Tree (DT) algorithms. Different evaluationmetricssuchasaccuracy,precision,recallandfscore were used to analyse the performance of these models. After comparing the results of all the three algorithms, it was found that the Naive Bayes (NB) algorithm had the greatestaccuracy of 76.30% and hence, outperformstheotheralgorithms.
2.4 Jobeda Jamal Khanam, Simon Y. Foo [11]
The authors split the Diabetes dataset containing 768 records and 9 attributes into the training and testing
For this research, the authors used the Pima Indians Diabetes Database (PIDD) and pre-processed it using the WEKA tool. After using the feature selection method and dropping three attributes, they utilized the remaining dataset with seven different machine learning algorithms: DT, KNN, RF, NB, AB, LR, SVM. Each of the 7 algorithms wereperformedbyboththeK-foldcross-validationandthe 85% train/test splitting method. Apart from these algorithms, ANN model with 1, 2, 3 hidden layers varying with the epochs 200, 400, 800 were also performed. After performingthecomparativeanalysis,itwasshownthatthe accuracy found for Logistic Regression (78.8571%), Naive Bayes (78.2857%), and Random Forest (77.3429%) were
better but the ANN model with hidden layer 2 and 400 epochsprovidedthemaximumaccuracy(88.57%).
2.5 Md. Maniruzzaman, Md. Jahanur Rahman, Benojir Ahammed and Md. Menhazul Abedin [12] Inthisstudy,theauthorsproposedaMLbasedsystemwith a combination of Logistic Regression & Random Forest algorithms. They conducted a comparative analysis to analyse the results of this combination with the other algorithms to find the best model among them. The proposed combination achieved the highest accuracy of 94.25%forK10protocol.
2.6 Usama Ahmed, Ghassan F. Issa, Muhammad Adnan Khan, Shabib Aftab, Muhammad Farhan Khan, Raed A. T. Said, Taher M. Ghazal, Munir Ahmad [13]
Inthisstudy,decisionlevelfusionwasusedbytheauthors to develop a machine learning-based decision assistance system for diabetes prediction. The suggested model incorporates two commonly used machine learning approachesthroughtheuseoffuzzylogic.Theaccuracyof thesuggestedfuzzydecisionsystemis94.87,whichiseven greaterthanthatoftheanyothersystemsthatare already inuse.
In this research, firstly the authors, utilizing the 10-fold validation approach, compared the results of six machine learning classification algorithms. Then after that, they suggested a Diabetes Prediction, Monitoring and Application(DPMA)framework.Theoretically,itshouldbe more effective to use several machine learning classifiers than just one. According to the research observations, the greatestclassificationaccuracy is 74%and thehighestF1measurescoreis0.74.
Inthisresearch,theauthorssuggestedaframeworkcalled as “eDiaPredict” which is used to predict diabetes in the patientsdependingupontheglucoselevelsintheirbodies. The PIMA Indian Diabetes dataset is utilised in this study, and it has been pre-processed using imputations and computations for missing values. To choose the best features, feature selection focused on Recursive Feature Elimination is also carried out. In the suggested approach, many ML models are used to introduce variety to the resultant ensemble model. The results show that the "eDiaPredict" can accurately and effectively forecast diabetes in patients based on blood glucose levels. In the suggested strategy, individually XGBoost reaches a 92% accuracy. Prediction accuracy is 95% when XGBoost is used with RF. The outcomes using "eDiaPredict" are compared to those from previously proposed techniques, which had accuracy levels of 80% and 90%, respectively. This comparison reveals improvements of 15% and 5%. The fact that both theXGboost and RF algorithms operate on the notion of iteratively lowering bias and finding the optimum solution is what accounts for the increase in outcomes.
In this study, the authors suggested a framework that automatically detects diabetes and notifies themedical staff so they may take prompt action. The system createdused cloud integration to combine various consumerandhealthcaregadgets,anditgavetheobtained readings to doctors so they could make better diagnostic decisions. The top-performing supervised ML algorithm out of four that was built was used using the suggested framework. This was empirically demonstrated to be the SVM-RBF, which attained accuracy, sensitivity, and specificity values of 83.20%, 87.20%, and 79%, respectively. This study's biggest contribution is the incorporation of a diabetes prediction model into an RPM framework that is flexible, versatile, and needs little patient interaction. The system is vendor-neutral and is compatible to interoperate to allow for the potential inclusion of additional prediction models and portable medicalequipmenttoenhancepatientoutcomes
3. RESEARCH METHODOLOGY
3.1 Dataset and Attributes
For the implementation of various ML algorithms in this study, the diabetes dataset is collected from the URL: https://www.kaggle.com/saurabh00007/diabetescsv
The name of the dataset is ‘diabetes.csv’ [8]. In the PID dataset, all the patients are female, and at least 21 years old. The dataset contains information about 768 patients and their corresponding nine unique attributes. The nine attributes that are used for the prediction of diabetes are Pregnancies, Glucose, Blood Pressure, Skin Thickness, Insulin level, BMI, Diabetes Pedigree Function, Age and Outcome. The ‘Outcome’ attribute is taken as a dependent/target variable, and the remaining eight attributesaretakenasindependent/featurevariables.The diabetesattribute‘outcome’consistsofbinaryvaluewhere 0meansnon-diabetesand1impliesdiabetes[11]
3.2 Data Pre-processing
DataPre-processingaidsintransformingthedatasothata moreaccuratemachinelearningmodelmaybecreated.To enhance the quality of the data, the data pre-processing conductsavarietyoftasks,includingidentifyingandfilling in the missing values, feature selection, and data normalization.
Duringtheidentificationofmissingvaluesinthedataset,it was found that there were no null values present in the dataset.
After confirming the absence of any null value in our dataset, we conducted feature scaling by performing normalizationofthedatasettonormalizetheentiredataset between the range of 0 to 1. This resulted in the better performanceofthealgorithms.
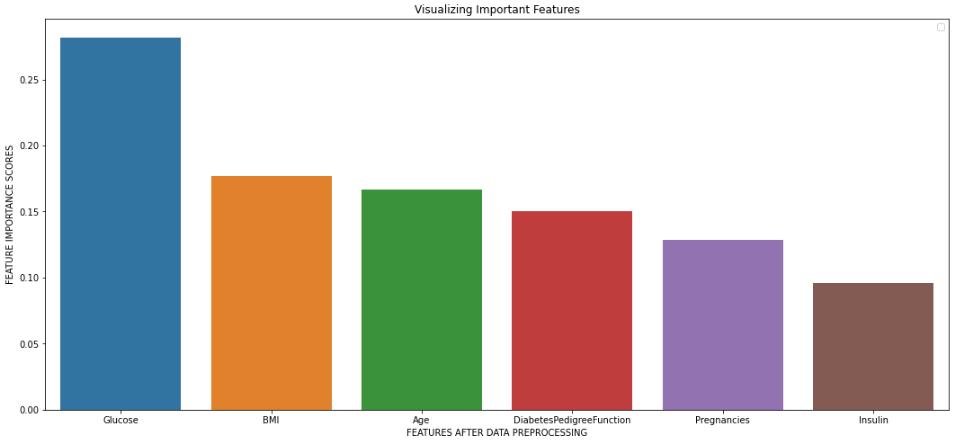
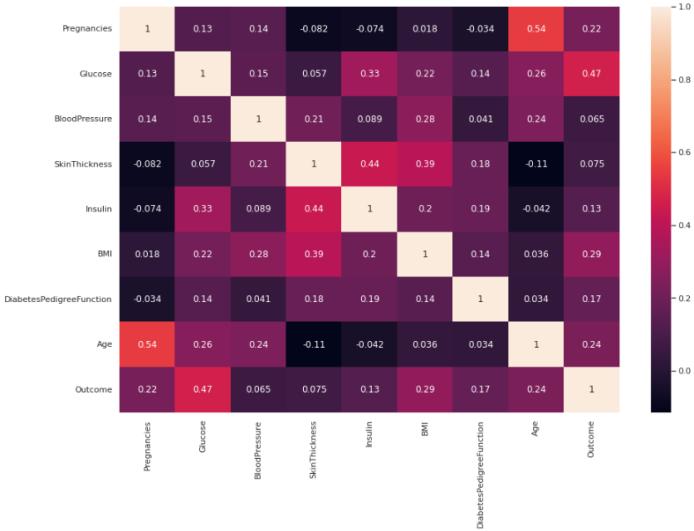
After ensuring that there is no null value present in our datasetandtheentiredataisnormalizedintherangeof0 to 1, we performed feature selection by examining the correlation matrix of the dataset to find the most significant attributes. The correlation matrix helps us to calculatethecorrelationcoefficientoftheindependentand dependentattributestofindtheinterdependenceofallthe attributes. The values above 0.5 and below −0.5 generally showshighercorrelationbetweenthetwoattributeswhile the values closer to 0 shows little or no correlation in between them. In our study, by analysing the correlation coefficient values in Fig. 1 for the attributes in respect to the ‘Outcome’ attribute and by taking the 0.1 as a cut-off value, we conclude that the attributes like Pregnancies, Glucose,Insulin,BMI,DiabetesPedigreeFunction,andAge are significant to us as they have higher than 0.1 correlation coefficient value with the ‘Outcome’ attribute, thus showing high dependencies in between all of them and the ‘Outcome’ attribute, while the attributes Blood Pressure and Skin Thickness are removed as they have lower than 0.1 correlation coefficient value with the ‘Outcome’attribute.
After the data cleaning and data pre-processing methods, we split the dataset into 80%/20% training/testing datasetstocomparetheresultsofthedifferentMLmodels.
3.3 Apply Machine Learning Techniques
We use five machine learning classification approaches after the data is prepared for modeling inorder topredict diabetes. Therefore, we provide an overview of various methods.
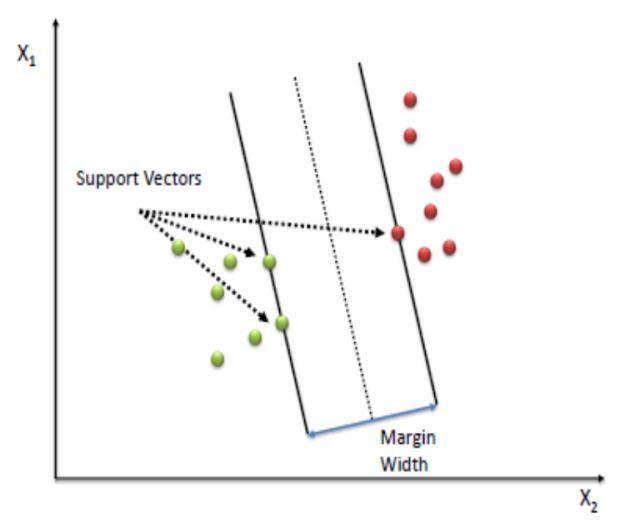
3.3.1 Support Vector Classifier
It is a classifier that utilizes the Support Vector Machine (SVM) algorithm. This is one of the most widely used algorithms.TheSupportVectorMachine(SVM)classifieris a classifier that explicitly classifies the data by distinguishing a hyper-plane. SVM separates elements
within a given class. Instances that are not supported by data can also be recognized and categorized by this. The executionofregressionmodeltogeneratealinearfunction isoneoftheapplicationsofthistechniqueandlearningto evaluate the attributes to produce categorization of differentelementsisanotherapplication[17}
3.3.2 Gaussian Naive Bayes
BasedontheBayes'Theorem,theNaiveBayesalgorithmis areliableclassifier.Assumingthatalloftheparametersare independent,letclass(i)bethediabetesvulnerablegroupi andVbetheinputparametersutilizedinthemodel[18].
A Naive Bayes model used to predict the risk category for diabetesbedescribedby-
P(class(i)|V)=
3.3.3 Random Forest
The Random Forest algorithm is a popular supervised classification technique used for a variety of classification problems. The RF algorithm is the derived from the Decision Tree classifier [9]. In the RF algorithm, the split thatischosenintheRandomForestalgorithmwhenanode is split throughout the tree-building process is no longer the optimal split across all features. Instead, the best split from a randomly selected subset of the characteristics is theonethatischosen.Thisunpredictabilitycausesthebias of the forest to somewhat rise in any scenario, but due to averaging,thisinstabilityisreducedaswell,typicallymore than compensating for the increase in susceptibility, leadingtoanoverallbettermodel[19]
3.3.4 XGBoost (Extreme Gradient Boosting)
The Extreme Gradient Boosting (XGBoost) algorithm is an efficientandexpandablevariationoftheGradientBoosting Machine (GBM) algorithm. Ituses decision tree ensembles to enhance goodness-of-fit and optimize performance. Multiple decision trees which are also known as the weak learners, they work simultaneously in the XGBoost algorithm to resolve the classification and regression issues[20]
3.3.5 Ensemble Model of Random Forest and SVC
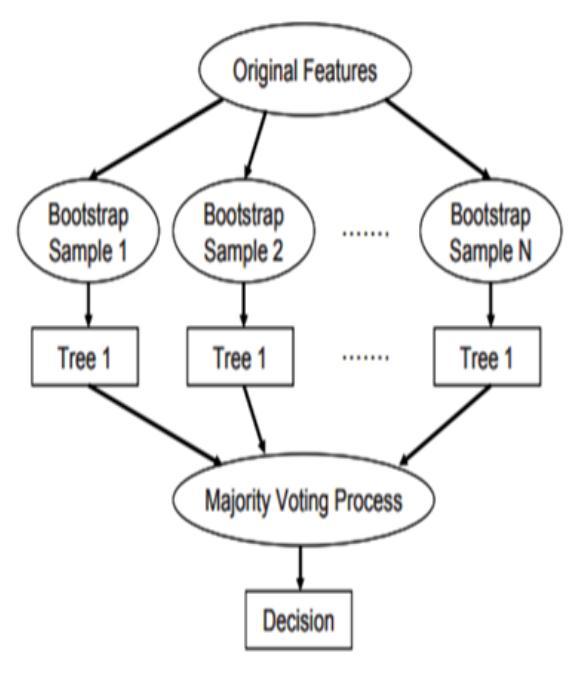
The Ensemble machine learning model is a well-known method to improve the overall performance of the model by combining many classifiers. After ensembling, the outputfrommanymodelsiscombined,whichcanincrease the performance of the model for better prediction accuracy. Each model's output adds confidence values to the unrevealed testing data, improving the overall accuracyofthemodel[1]
4. EVALUATION METRIC
In this section, all of the statistics such as confusion matrix, accuracy, precision, recall, and f1- score that will be used by our model to assess the prediction outcomes aredefined.
4.1 Confusion Matrix
It generates a matrix which expresses the proposed model'soverallperformance[21].
where, TP: TruePositive FP: FalsePositive
FN: FalseNegative TN: TrueNegative
4.2 Classification Accuracy
It evaluates the ratio of correct predictions to the total numberofinputsamples[21].Itisstatedas-
Accuracy=
Accuracy can be calculated with the help of the confusion matrix by taking the average of the True Positive and the True Negative values lying across its main diagonal. It is givenas-
Accuracy=
where, N: Totalnumberofsamples
4.3 Precision
It is the total amount of true positives divided by the total amount of false positives and the total amount of true positives[22].Itisstatedas-

Precision=
where, FP: FalsePositives
TP: TruePositives
4.4 Recall
It is the total amount of true positives divided by the total amount of false negatives and the total amount of true positives[22].Itisstatedas-
Recall= where, FN: FalseNegatives
TP: TruePositives
4.5 F1-Score
It is the Harmonic Mean of Recall and Precision. F1-Score has a range of [0, 1]. It informs you the robustness and precision of the classifier. It aims to achieve a proper balance between the Recall and Precision [21]. It is stated as-
F1-Score= ( ) ( )
5. RESULTS AND DISCUSSION
In this section, comparative analysis of results of all the machine learning models is performed, which are obtained after dividing the dataset into 80% training datasetand20%testingdataset.
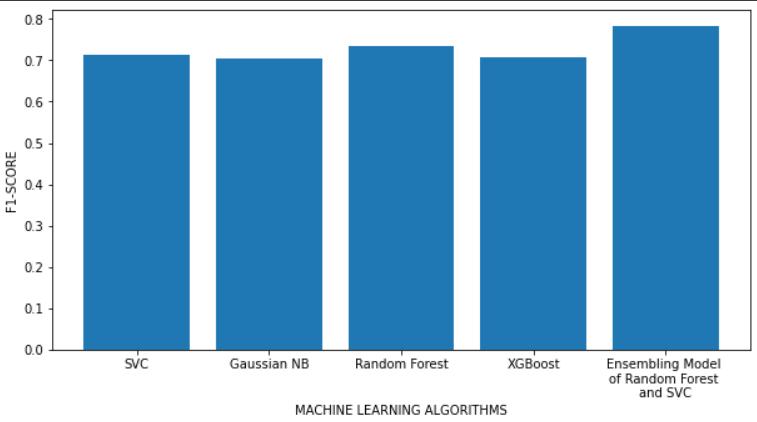
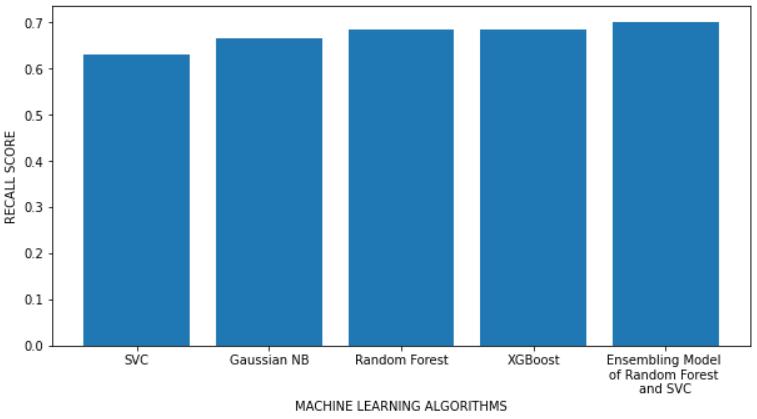
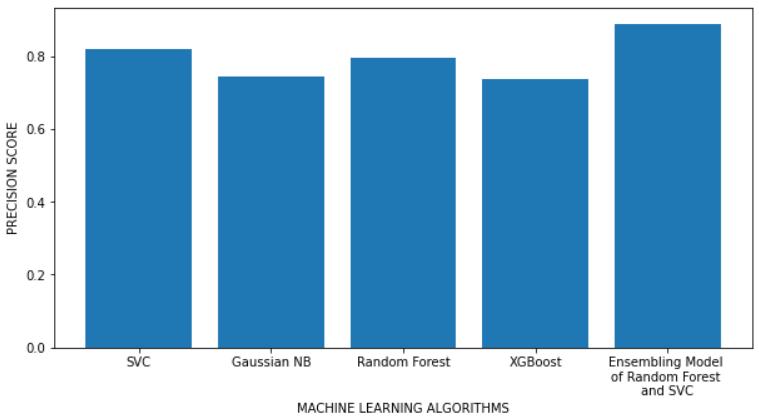
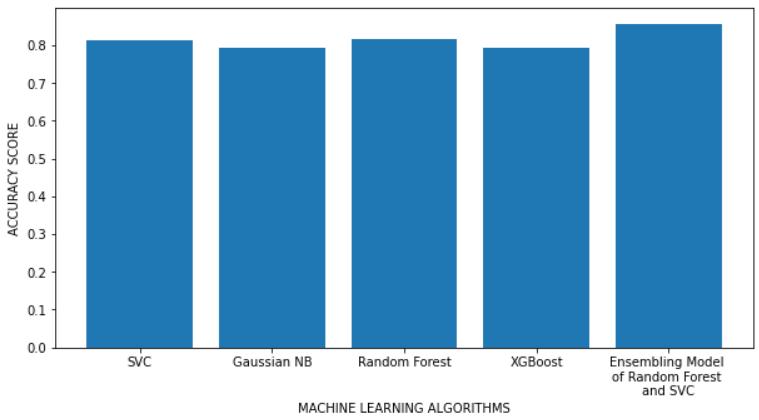
Table 1 illustrates that the Ensemble Model of Random Forest and SVC algorithms is the best classifier outperformed all of the other machine learning models in this study by achieving the accuracy of 85.714% and the precision of 88.889%. The performance of this model was even better than the results achieved in [8] where the Decision Tree classifier achieved 71.4% accuracy, the Logistic Regression algorithm achieved 77% accuracy and the best algorithm among them was the KNN algorithm withthehighestaccuracyof78%inthatstudy.
6. CONCLUSION AND FUTURE WORKS
Oneofthemajorhealthproblemsthatactually killalotof people worldwide each year is diabetes. If a precise early prediction is achievable, the severity and risk factors associatedwithdiabetescanbeconsiderablyreduced.We provide a model that can predict if a patient has diabetes or not. Utilizing a variety of evaluation metrics, five different machine learning classification models are compared. The Diabetes dataset is used as the basis for experiments. According to the conclusions drawn, the Ensemble Model of Random Forest and SVC algorithms outperformed all the other classifiers for the task of predicting diabetes. Therefore, the Ensemble Model of RandomForestandSVCalgorithmsisconsideredthebest machine learning model for this study because of the highest Accuracy Score (85.714%), Precision Score (88.889%)andtheF1-Score(78.431%)itachievedamong all the other classification algorithms. Further this work can be extended by introducing various other machine learning and deep learning techniques to this study with the intent to make an even better predictive model. The probability of non-diabetic people developing diabetes in futurecouldalsobefound.
CONFLICT OF INTEREST
Authorshavenoconflictofinterestwithanyone.
ACKNOWLEDGEMENT
WewouldliketoexpressourgratitudetoMs.ShalluJuneja for sharing her wisdom with us, giving us the knowledge that we needed for this research, and for her skills and insights,allofwhichwerequitehelpful.
REFERENCES
[1] M. K. Hasan, M. A. Alam, D. Das, E. Hossain and M. Hasan, "Diabetes Prediction Using Ensembling of Different Machine Learning Classifiers", in IEEE Access, vol. 8, pp. 76516-76531, 2020, doi: 10.1109/ACCESS.2020.2989857
[2] Z. Tafa, N. Pervetica and B. Karahoda, "An intelligent system for diabetes prediction", 2015 4th Mediterranean Conference on Embedded Computing (MECO), 2015, pp. 378-382, doi: 10.1109/MECO.2015.7181948.
[3] El_Jerjawi, Nesreen Samer & Abu-Naser, Samy S. (2018). “Diabetes Prediction Using Artificial Neural Network”. International Journal of Advanced Science andTechnology121:54-64.
[4] Zhou, H., Myrzashova, R. & Zheng, R., “Diabetes prediction model based on an enhanced deep neural network”. J Wireless Com Network 2020, 148 (2020). https://doi.org/10.1186/s13638-020-01765-7
[5] Jayanthi, N., Babu, B.V. & Rao, N.S., “Survey on clinical prediction models for diabetes prediction”. J Big Data 4, 26 (2017). https://doi.org/10.1186/s40537-0170082-7
[6] Larabi-Marie-Sainte, S.; Aburahmah, L.; Almohaini, R.; Saba,T., “Current TechniquesforDiabetes Prediction: Review and Case Study”. Appl. Sci. 2019, 9, 4604. https://doi.org/10.3390/app9214604
[7] Harleen Kaur and Vinita Kumari. “Predictive modelling and analytics for diabetes using a machine learning approach”. Applied Computing and Informatics.DOI:10.1016/j.aci.2018.12.004
[8] Chintan Rana, Sneha Unnarkar, Krishna Patel, Prof. Sudha Patel. "Diabetes prediction using Various Machine Learning Algorithms", International Journal of Emerging Technologies and Innovative Research (www.jetir.org), ISSN:2349-5162, Vol.9, Issue 2, page no.c943-c949, February-2022, Available: http://www.jetir.org/papers/JETIR2202212.pdf
[9] A. Yahyaoui, A. Jamil, J. Rasheed and M. Yesiltepe, "A Decision Support System for Diabetes Prediction Using Machine Learning and Deep Learning Techniques", 2019 1st International Informatics and Software EngineeringConference(UBMYK),2019, pp. 1-4,doi:10.1109/UBMYK48245.2019.8965556.
[10] Deepti Sisodia, Dilip Singh Sisodia, “Prediction of Diabetes using Classification Algorithms”, Procedia Computer Science, Volume 132, 2018, Pages 1578-
1585, ISSN 1877-0509, https://doi.org/10.1016/j.procs.2018.05.122.
[11] JobedaJamalKhanam,SimonY.Foo,“Acomparisonof machine learning algorithms for diabetes prediction”, ICT Express, Volume 7, Issue 4, 2021, Pages 432-439, ISSN 2405-9595, https://doi.org/10.1016/j.icte.2021.02.004
[12] Maniruzzaman, Md & Rahman, Md & Ahammed, Benojir & Abedin, Md. (2020). “Classification and predictionof diabetesdiseaseusing machinelearning paradigm”.HealthInformationScienceandSystems.8. 1-14.10.1007/s13755-019-0095-z.
[13] U. Ahmed et al., "Prediction of Diabetes Empowered WithFusedMachineLearning,"inIEEEAccess,vol.10, pp. 8529-8538, 2022, doi: 10.1109/ACCESS.2022.3142097.
[14] Ashima Singh, Arwinder Dhillon, Neeraj Kumar, M. Shamim Hossain, Ghulam Muhammad, and Manoj Kumar. 2021. “EDiaPredict: An Ensemble-based Framework for Diabetes Prediction”. ACM Trans. Multimedia Comput. Commun. Appl. 17, 2s, Article 66 (June 2021), 26 pages. https://doi.org/10.1145/3415155
[15] S. M. Hasan Mahmud, Md Altab Hossin, Md. Razu Ahmed, Sheak Rashed Haider Noori, and Md Nazirul Islam Sarkar. 2018. “Machine Learning Based Unified FrameworkforDiabetesPrediction”.InProceedingsof the 2018 International Conference on Big Data Engineering and Technology (BDET 2018). Association for Computing Machinery, New York, NY, USA, 46–50. https://doi.org/10.1145/3297730.3297737
[16] Ramesh, J., Aburukba, R., Sagahyroon, A.: A remote healthcare monitoring framework for diabetes prediction using machine learning. Healthc. Technol. Lett. 8, 45– 57 (2021). https://doi.org/10.1049/htl2.12010
[17] M. F. Faruque, Asaduzzaman and I. H. Sarker, "Performance Analysis of Machine Learning Techniques to Predict Diabetes Mellitus", 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), 2019, pp. 1-4, doi:10.1109/ECACE.2019.8679365
[18] Nongyao Nai-arun, Rungruttikarn Moungmai, “Comparison of Classifiers for the Risk of Diabetes Prediction”, Procedia Computer Science, Volume 69, 2015, Pages 132-142, ISSN 1877- 0509, https://doi.org/10.1016/j.procs.2015.10.014
[19] D. Dutta, D. Paul and P. Ghosh, "Analysing Feature Importances for Diabetes Prediction using Machine Learning", 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), 2018, pp. 924-928, doi: 10.1109/IEMCON.2018.8614871.
[20] M. Athanasiou, K. Sfrintzeri, K. Zarkogianni, A. C. Thanopoulou and K. S. Nikita, "An explainable XGBoost–based approach towards assessing the risk of cardiovascular disease in patients with Type 2 Diabetes Mellitus", 2020 IEEE 20th International Conference on Bioinformatics and Bioengineering (BIBE), 2020, pp. 859-864, doi: 10.1109/BIBE50027.2020.00146.
[21] Aishwarya Mujumdar,V Vaidehi, “DiabetesPrediction using Machine Learning Algorithms”, Procedia ComputerScience,Volume 165,2019,Pages292-299, ISSN 1877-0509, https://doi.org/10.1016/j.procs.2020.01.047
[22] F. Alaa Khaleel and A.M. Al-Bakry, “Diagnosis of diabetes using machine learning algorithms”, Materials Today: Proceedings, https://doi.org/10.1016/j.matpr.2021.07.196
[23] Changsheng Zhu, Christian Uwa Idemudia, Wenfang Feng, “Improved logistic regression model for diabetes prediction by integrating PCA and K-means techniques”, Informatics in Medicine Unlocked, Volume 17, 2019, 100179, ISSN 2352-9148, https://doi.org/10.1016/j.imu.2019.100179
[24] Naz,H.,Ahuja,S.,“Deeplearningapproachfordiabetes prediction using PIMA Indian dataset”. J Diabetes Metab Disord 19, 391–403 (2020). https://doi.org/10.1007/s40200-020-00520-5
[25] Tejas N. Joshi*. “Diabetes Prediction Using Machine Learning Techniques”, International Journal of Engineering Research and Applications (IJERA), vol. 08,no.01,2018,pp.09–13.
[26] DATASET -
https://www.kaggle.com/saurabh00007/diabetescsv