
Loan Default Prediction Using Machine Learning Techniques
Dr. E. Praynlin1 , Madesh S2 , Mohammed Thafeez H3 , Venu K V4, Vinodh Kumar K51Assoc. Professor, Computer Science and Engineering, T. John Institute of Technology, Bengaluru, Karnataka, India

2345 UG Students, Computer Science and Engineering, T. John Institute of Technology, Bengaluru, Karnataka, India
Abstract - Loan business is one of the major incomesources for bank. Loan default problem is a major issue for loan business. Loans, specifically whetherborrowersrepaytheloan or default on it, have a significant impact on a bank's profitability. By anticipating loan defaulters, the bank is able to reduce its non-performing assets. Three primary predictive analytics techniques I Data Collection, II Data Cleaning,and III Performance Assessment are used to research the prediction of loan defaulters Experimental investigations reveal that when it comes to loan forecasting, the KNN model performs better than the Decision tree model
Key Words: Machine learning, Loan prediction, Banking, Decisiontree,KNN.
1.INTRODUCTION
BothapplicantsandbankworkersfindLoanPredictiontobe highly useful. The goal of the article is to present a rapid, easy and instantaneous way of choosing the competent people.AFinanceCompanyhandlesallloans.Theyprovide servicestoallurban,semi-urban,andruralareas.Theclient submits their loan application once the business or bank confirmstheirqualificationforaloan.Thebusinessorbank wantstoautomaticallydetermineifacustomeriseligiblefor a loan based on the information, they provide on the applicationform(inrealtime).Therecontainsinformation about the borrower's gender, marital status, educational background,numberofdependents,income,loanamount, and credit history. Data from former clients of multiple banks, whose loans were approved in line with a set of norms,wereusedinthisprogramme.Themachinelearning models is trained on the data to provide accurate results. Predictingloansafetyistheprimarygoalofthisstudy.With theSVMtechnique,loansafetymaybepredicted.Thedatais first cleaned to remove any missing values from the data collection. Thegoal ofthisprojectistocreatea ML model that,giventheloanandpersonaldataprovided,canpredictif aborrowerwouldfailontheloan.Thetechniqueofthemodel is intended to be used by the client and his financial institution as a reference tool to help with loan issuing choicesinordertoreduceriskandoptimizeprofit
1.1 Motivation
There are several reasons why predicting loan default is important for lenders, investors, and borrowers. Here are some of the key motivations: Risk Management, Cost
***
Reduction, Investment Decisions, Regulatory Compliance, SocialImpact
For financial companies, the loan approval procedure is crucial.Theloanapplicationswereacceptedorrejectedby thesystem.Loanrecoveryisamajordeterminantofabank's financialperformance.Predictingwhetheraconsumerwill paybackadebtisexceedinglytough.
2. LITERATURE SURVEY
Loandefaultpredictionisacrucialtaskinthebankingand finance industry, and it has received significant attention fromresearchersandpractitionersinrecentyears.Hereare someoftherelevantstudiesandliteratureonloandefault prediction:
1."PredictingCreditCardDefaultsUsingMachineLearning Techniques" by Wei et al. (2009): This study compared differenttypesofMLalgorithms,likeneuralnetworksand decisiontree,forpredictingcreditcarddefaults.Theauthors foundthatensemblemethods,suchasrandomforests,were themosteffectiveforthistask.
2."A Comparative Study of Machine Learning Methods for Loan-DefaultPrediction"byBrown&Thomas(2011):This studycompareddifferenttypesofMLalgorithms,including support vector machines, decision trees and neural networks, for predicting loan defaults. The authors found that gradient boosting and random forests performed the best.
3."CreditScoringandLoanDefault"byThomasetal.(2016): Thisbookprovidesanoverviewofcreditscoringandloan default prediction. It covers the traditional statistical methods, such as logistic regression and discriminant analysis, as well as more recent machine learning techniques.
4."Loan Default Prediction Using Bayesian Networks: A Comparative Study" by Azevedo et al. (2019): This study comparedBayesiannetworkswithotherMLtechniques,like SVM and decision-tree, for predicting loan defaults. The authors found that Bayesian networks outperformed the othermethods.
"Predicting Loan Default: An Analysis of Variables and Techniques" by Adeyemo and Adeleke (2021): This study
investigatedthefactorsthatcontributetoloandefaultand compared various machine learning algorithms for predictingdefaults.Theauthorsfoundthatgradientboosting andrandomforestsperformedthebest,andthatvariables suchasincome,loanamount,andloantermweresignificant predictorsofdefault.
5."Credit Risk Assessment Using Machine Learning
Techniques:AReview"by Sathyadevan etal.(2021): This reviewarticlecoversvariousmachinelearningtechniques forcreditriskassessment,includingloandefaultprediction. The authors discuss the strengths and weaknesses of differentmethodsandproviderecommendationsforfuture research.
Overall, this research indicates that ensemble approaches like gradient boosting technique and random forest approach,aswellasmachinelearningtechniques,areuseful for predicting loan failure. Moreover, key indicators of defaultincludethingslikeincome,loansize,andloanlength
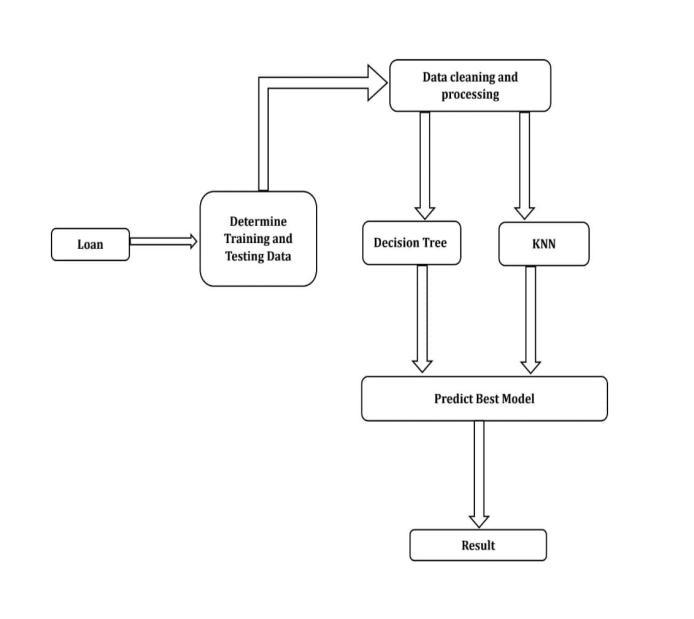
3. IMPLEMENTATION
Data Collection and Preparation: Collect relevant datafromvarioussourcessuchascreditbureaus, bank statements, loan applications, etc. The data should include both demographic and financial information about the borrower, such as age, income, credit history, employment status, loan amount, interest rate, loan term, etc. Clean and preprocess the data to remove missing values, outliers, and other errors that may affect the accuracyofthemodel.
Feature engineering: The practice of adding new featurestothedatathatcurrentlyexistinorderto improvethemodel'saccuracyisknownasfeature engineering. For instance, given the borrower's financial data, one may calculate metrics like the loan-to-value,debt-to-income,paymenthistory,and credit utilization ratio. With feature selection, the most important features for the prediction model mayalsobediscovered.
ModelSelection:Basedontheavailabledataandthe issue at hand, select a suitable machine learning algorithm.Manytechniques,includingasdecisiontree,gradientboostingtechnique,random-forest, neural networks & bayesian networks, are frequently used to predict loan failure. Both categoricalandcontinuousfeaturesshouldbeable tobehandledbythealgorithm.
ModelValidation:Toassesstheeffectivenessofthe ML-model,thedatasetswillbedividedintotraining datasetsandtestingdatasets Whenthemodelhas
beencreatedusingthetrainingset,itsperformance is assessed using the testing set. To evaluate the model'seffectiveness,utilizeappropriatemethods suchasaccuracy,precision,F1score,ROC-AUCand recall
ModelDeployment:Themodelmaybeputintouse inaproductionsettingafterithasbeentrainedand verified. This entails making sure the model is scalableandstableaswellasincorporatingitinto thebank'sloanprocessingsystem.
ModelMonitoringandMaintenance:It'scrucialto keep track of the model's performance over time and update it as required. Updating can entail updatingthemodel'sdataorchangingitsfeatures ormethods.
4. SYSTEM ARCHITECTURE
5. EXISTING MODEL
Apopularmachinelearningapproachforclassificationand also for regression applications is the decision-tree. The method divides the data recursively into subgroups depending on the most useful attributes until a halting requirementissatisfied.Onebenefitofdecisiontreesisthat theycanhandlebothcategoryandnumericaldata.Another benefit is that they are simple to understand and display. Nevertheless, if the tree is too complicated or the data is noisy, they may potentially experience overfitting and instability.
Indecision-treeanalysis,thevaluesofcompetingchoiceare estimated like visual, analytical decision assistance tool using a decision-tree approach and the corresponding relatedimpactdiagram.
Operationsresearchandmanagementregularlyusedecision trees. when choices must be made online with little to no understandingbeforehand,theoptimaldecision-treemodel is to use a probability model. or online selection model. Moreover,conditionalprobabilitiesmaybecalculatedusing decisiontreesinadescriptiveway
6. PROPOSED MODEL
Bothclassificationandregressionarecarriedoutusingthe supervisedlearningmethodknownasK-nearestneighbours. KNNmodelpredictstheclassforthetestdatabycalculating the separation of the test datasets & the training points Thenthe‘K’pointsthatmostcloselyreflectthetestdatasets should be chosen When the K-NN algorithm splits the datasets of test into one of the "K" training data class, the highestprobabilityclasswillbechosen.Thetrainingpoints' average with the stated value of "K" is the value in a regressionscenario.
TheK-NNoperatesaccordingtothefollowingalgorithm:
ChoosewhichoftheKneighboursyouwantinstep one.
The second step is to calculate the Euclidean distancebetweenKneighbours.
In third step, on the basis of Euclidean distance determined,selecttheK-neighboursthatareclose
Infourthstep,amongthek-neighbours,countthe no.ofdatapointsineachcategory
In fifth step, the category with the closest neighbours should receive the additional data points.

Atlaststep,themodelcompletestheoperation.
7. CONCLUSION
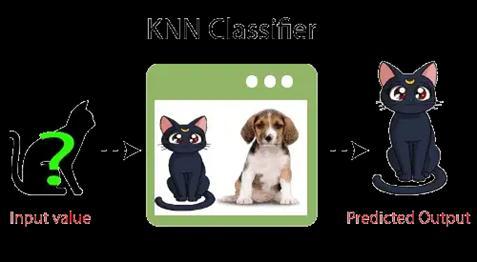
Considerthecasewhenwehaveaphotoofacreaturethat resemblesbothcatsanddogsbutweareunsureofwhichit is.However,sincetheKnearestneighbourmethodisbased onasimilaritymeasure,wemayuseitforthisidentification Bycomparingthenewdataset'scharacteristicswiththose showninpicturesofcatsanddogs,ourKnearestneighbour modelwillidentifywhetherthenewdatasetisacatordog.
Toenhanceourloanapplicationevaluationprocess,weplan toimplementbothdecisiontreeandK-NNmodelstopredict potential loan defaulters. Our objective is to compare and evaluate the performance of both models and determine whichoneyieldsmoreaccurate results.Byusing multiple models, we aim to improve our prediction accuracy and minimize the risk of potential loan defaults. We will thoroughlyanalyzetheresultsofbothmodelstochoosethe mostsuitableone.Itcorrectlypredictswhetherornotaloan application or customer will be approved. This study will claim that the dataset's prediction accuracy is excellent. Whenacustomerexperiencesacalamity,forexample,the algorithmmaynotbeabletoforecasttherightoutcome.This studycandetermineifapotentialconsumerwouldreturna loan,anditsaccuracyisgood.Age,income,loanlength,and loan amount are the most crucial variables when determining(whethertheclientwouldhavebeen).Zipcode and credit history are the two most crucial variables in determiningtheloanapplicant'scategory.
REFERENCES
[1] ShraddhaR.NikamandAshwiniS.Kadam,“Prediction for Loan Approval using ML Algorithm,” International ResearchJournalofEngineeringandTechnology,April 2021.
[2] T.M.Luong,HaraldScheule&NityaWanzare,-“Impact ofmortgagesoftinformationinloanpricingondefault prediction using machine learning,” International ReviewofFinance,September2022.
[3] Baodong Li,“Online Loan Default Prediction Model Based on Deep Learning Neural Network,” Hindawi Computational Intelligence and Neuroscience, August 2022.
[4] Weidong Chen & Yiheng Li, - “Entropy method of constructing a combined model for improving loan defaultprediction:AcasestudyinChina,”Journalofthe OperationalResearchSociety,December2019.
[5] T. Aditya Sai Srinivas, Somula Ramasubbareddy, and K.Govinda, - “Loan Default Prediction Using ML Techniques,” Innovations in Computer Science and Engineering,March2022.
[6] LiliLai,-“LoanDefaultPredictionwithMLTechniques,” InternationalConferenceonComputerCommunication andNetworkSecurity(CCNS),August2020.
[7] Vishal Singh, Ayushman Yadav & N. Partheeban,“PredictionofModernizedLoanApprovalSystemBased on ML Approach,” International Conference on IntelligentTechnologies(CONIT),June2021.
[8] Dr.CKGomathy,Ms.Charulatha&Ms.Sowjanya,-“The Loan Prediction using ML,” International Research JournalofEngineeringandTechnology,October2021.