
Sentiment Analysis for Sarcasm Detection using Deep Learning
Vialli L. K. Gonsalves1, Sherica L. Menezes21Student, Dept. of Computer Engineering, Goa College of Engineering, Farmagudi, Ponda, Goa, India
2Project Guide, Assistant Professor, Dept. of Computer Engineering, Goa College of Engineering, Farmagudi, Ponda, Goa, India ***

Abstract - Detection of sarcasm in texts is useful to understand the thorough meaning of the message as to whether the message is positive or negative and hence classify it accordingly. It is normally a tough procedure as a negative message is portrayed as a seemingly positive one and hence due to this, there is an error in the classification of such messages. Unlike sentiment analysis, the borders of sarcasm are not well defined. This paper aims to address the difficult task of sarcasm detection by using some Deep learning techniques like LSTM, GRU, and Bi-LSTM. The aim is to use these techniques on the same dataset and compare their performance. The one with the best-observed performance is chosen as the main model and the final classification task is done using this model
Key Words: Sarcasm,Detection,Classification,LSTM,BiLSTM,GRU
1. INTRODUCTION
The technique to analyze and determine the sentiment behindapieceoftextiscalledSentimentanalysis.Itusesa combination of machine learning principles and natural language processing (NLP) to achieve this. Using sentiment analysis, we can recognize whether the sentiment behind a block of text is positive, negative, or neutral. It is a powerful technique in Artificial intelligence(AI) that has an important application in business.
Forexample,youcanuseittoanalyzecustomerfeedback. After acquiring that feedback or reviews through various mediums, you can run sentiment analysis algorithms on those text pieces to calculate the sentiment score and based on that understand your customers' attitude towardstheproduct.
Sentimentanalysisis useful when there isa large amount of unstructured data, and to then classify that data by automatically tagging it. Net Promoter Score (NPS) surveys are a technique that is used extensively to gain knowledge and understanding of how a customer perceives a service or product. In human social interaction, sarcasm which can be both constructively humorous and negatively offensive plays a significant role.
Insocial media,sarcasmis frequentlyutilized toconvey a negative opinion using positive or amplified positive language. Because of this, sentiment analysis models can be readily tricked by sarcasm unless they are specially createdtoconsider this possibility. Sarcasmidentification is a crucial component of sentiment analysis because of this deliberate ambiguity. It is claimed that sarcasm detectionisabinaryclassificationissue.
Without a thorough understanding of the situation's context,thetargetedtopic,andthesurroundings,sarcasm identification in sentiment analysis is exceedingly challenging. Both a human and a machine may find it challenging to comprehend. It might be challenging to adequately train sentiment analysis algorithms since sarcasticphrasesfrequentlyuseawiderangeofterms.
2. RELATED WORK
Itisbeneficialfortheusertounderstandthesentimentof the message that is received to have a proper understandingofit.
Avinash kumar[1] aims to identify sarcastic remarks in a given corpus; they introduce the multi-head attentionbased bidirectional long-short memory (MHA-BiLSTM) network. The experiment's findings show that BiLSTM performs better than feature-rich SVM models and benefitsfromamulti-headattentionmechanism.
Liyuan Liu[2], in their work, to improve classification performance, a new deep neural network called A2TextNet created to emulate face-to-face speech. This network incorporates auxiliary variables like punctuation, part of speech (POS), numerals, emoji, etc. The outcomes of the experiment show that our A2Text-Net technique outperforms traditional machine learning and deep learningalgorithmsintermsofclassificationperformance.
Md shaifullah razali[3] identifies sarcasm in tweets by combining hand-crafted contextual data with deep learningextractedfeatures.ConvolutionalNeuralNetwork (CNN)featuresetsareretrievedfromthearchitectureand thenmixedwithmeticulouslydesignedfeaturesets.These individuallydesignedfeaturesetsaredevelopedbased on theircorrespondingcontextual justifications.Eachfeature sethasbeencreatedexpresslytodetectsarcasminmind.
IbrahimAbu-Farha[4]nowproposesArSarcasm,adataset for detecting sarcasm in Arabic that was produced by reannotating existing datasets for sentiment analysis in Arabic. 10,547 tweets total in the sample, with 16% of them being ironic.Thedata wastagged forsentimentand dialects in addition to sarcasm. The shift in sentiment labelingbasedonannotators'biasesservesasevidencein our examination of the extremely subjective character of thesetasks.
Deepak Jain[5] in this study suggests utilizing deep learning to identify sarcasm in tweets that move between English and Hindi, the native language of India. The suggested model combines a softmax attention layer with a convolution neural network for real-time sarcasm detection, together with a bidirectional long short-term memory component. Real-time mash-up tweets are taken from popular trending political (#government) and entertainment (#cricket, #bollywood) posts on Twitter to assess the performance of the suggested approach. 3000 sarcasticand3000 non-sarcasticbilingual Hinglish (Hindi English)tweetsmakeuptherandomlyselecteddataset.
Rolandos Alexandros Potamias[6]. In their paper “A transformer-based approach to irony and sarcasm detection” To solve the identification of the aforementioned FL forms' problems, we use cutting-edge deep learning approaches. We offer a neural network methodology that significantly expands on our earlier work. It is based on a recently proposed pre-trained transformer-based network architecture and is further improved by the use of a recurrent convolutional neural network. Data preparation is minimized in this configuration. Results show that the suggested methodologyoutperformsallpreviousmethodologiesand published research, even by a significant margin, and achieves state-of-the-art performance under all benchmarkdatasets.
Himani Srivastava[7] in their paper “A Novel Hierarchical BERT Architecture for Sarcasm Detection” offer a novel deep learning-based method that hierarchically uses the supplied contexts to determine if a statement is sarcastic ornot.
Forourinvestigations,weuseddatasetsfromTwitterand Reddit1, two online discussion forums. Experimental and error analysis demonstrate that the hierarchical models outperformtheirsequentialcounterpartsbyfullyutilizing historytoachieveabetterrepresentationofcontexts.
Lu Ren et al.[8] in their paper “Sarcasm Detection with Sentiment Semantics Enhanced Multi-level Memory Network” Using emotion semantics, we suggest a multilevel memory network to capture the characteristics of
sarcastic statements. The first-level memory network in our model is used to represent the sentiment semantics, and the second-level memory network is used to represent the contrast between the sentiment semantics andthecontextofeachsentence.Additionally,weenhance the memory network in the absence of local information using an upgraded convolutional neural network. The experimental outcomes on the Twitter dataset and InternetArgumentCorpus(IAC-V1andIAC-V2)showhow wellourmodelperforms.
Le Hoang son et al.[9] in their paper “Sarcasm Detection UsingSoftAttention-BasedBidirectionalLongShort-Term Memory Model With Convolution Network” sAtt-BLSTM convNet, a deep learning model that uses global vectors forword representation(GLoVe)tocreatesemanticword embeddings, is based on a hybrid of soft attention-based bidirectional long short-term memory (sAtt-BLSTM) and convolutionneuralnetwork(convNet).Punctuation-based auxiliaryfeaturesarecombinedwiththeconvNettogether withthefeaturemapsproducedbythesAtt-BLSTM.Using balanced(tweetsfrombenchmarkSemEval2015Task11) and unbalanced (about 40000 random tweets using the Sarcasm Detector tool with 15000 sarcastic and 25000 non-sarcastic words) datasets, the robustness of the proposed model is examined. The proposed deep neural model with convNet, LSTM, and bidirectional LSTM with/without attention is compared using training- and test-set accuracy metrics, and it is found that the novel sAtt-BLSTM convNet model outperforms others with a highersarcasm-classificationaccuracyof97.87percentfor the Twitter dataset and 93.71 percent for the randomtweetdataset.
3. METHODOLOGY
1) Data extraction
Forthisresearch,atextdatasetprovidedbyKagglenamed “News Headlines Dataset For Sarcasm Detection“ was used. Two news websites provided the content for this News Headlines dataset for sarcasm detection. TheOnion triestoproducesatiricalinterpretationsofcurrentevents, thus we gathered all the headlines from the categories News in Brief and News in Photos (which are sarcastic). From HuffPost, we pull actual (and unsarcastic) news headlines.
Compared to the current Twitter datasets, this new datasethasthefollowingadvantages:
● There are no spelling errors or colloquial language because news headlines are prepared by professionalsinapropermanner.Thislessensthesparsity
and raises the likelihood of discovering pre-trained embeddings.
● Furthermore, compared to Twitter datasets, we receive high-quality labels with significantly less noise because TheOnion's main objective is to provide satirical news.
● The news headlines we gathered are standalone, unlike tweets that are replies to other tweets. This would make it easier for us to identify the true sarcastic components.
Eachrecordconsistsofthreeattributes:
● is_sarcastic:isa booleanvaluewith1assarcastic and0asnot
● headline:theheadlineofthenewsarticle
● article_link: link to the original news article. Usefulincollectingsupplementarydata
2) Pre-processing
Today,everyindustryhasaccesstoasignificantamountof unstructured data in the form of text, audio, videos, etc. This information can be utilized to assess a variety of variables, which can then be applied to further make decisions or predictions. But in order to achieve better results,therawdatamustbeorganizedorsummarized.
This is where natural language processing (NLP), a subfield of data science, comes into play. NLP helps analyze, organize, or summarize text data so that meaningful information may be extracted from it and applied to business choices. Text preprocessing refers to thetechniqueofpreparingtextualdatabycleansingitand formattingitappropriatelyforinputtingintoamodel..The followingisdone:
● Removeemojis,symbols,andpictures
● Removeunnecessarycharacters
● Removeflags(IOS)andmapsymbols
● Removeabbreviations
● Convertalltexttolowercase
● Removeduplicates
3) Visualization
Using the word cloud, we can visualize the frequency of words occurring in the chosen dataset. The larger the wordis,thegreateritsfrequency.

The technique of Word Cloud is employed to visualize textual data, where the size of each word indicates its frequency or significance. This technique can be used to emphasizenoteworthytextualelementsinthedata.Word clouds are widely used for analyzing data from social networkwebsites.
Fig1:DatasetVisualization
As we can see in the image, the words such as “new”, “man”, “report”, “area” are the largest in size and hence through this we can say that they are frequently occuring inthedataset.
Where words such as “friends”, “mom”, “mother”, “another”are thesmallestinsizeso wecanconcludethat thesewordsarerarelypresentinthedataset.
4)
Train-test split
When your model is deployed in production, you don't want it to overlearn from the training data and perform poorly. You require a method to judge how well your model generalizes. To avoid overfitting and to conduct an effective model evaluation, you must divide your input dataintotraining,validation,andtestingsubsets.
To train a CNN network we need training and validation data,thedatasetinKagglehasonlyatrainingdataset.SoI havechosensomepartoftrainingdata asvalidationdata, and the remaining images as the training data. I have chosen a split size of 20% to separate the validation imagesfromthetrainingimages.
5)
Loading GloVe model
GloVestandsforglobalvectorsforwordrepresentation.It is an unsupervised learning algorithm developed by Stanford for generating word embeddings by aggregating global word-word co-occurrence matrices from a corpus. The resulting embeddings show interesting linear substructuresofthewordinvectorspace.
6) Building the model
The model used for this project is the Bi-LSTM model. Bidirectional long-short-term memory(Bidirectional LSTM) is the process of making any neural network have the sequence information in both directions backward (future to past) or forward(past to future). After studies andcomparisonwithothermodelssuchasLSTMandGRU, it was found that Bi-LSTM performed the best on textbaseddatasetsandhencethismodelwasusedforsarcasm detection.
Variousparameterswerechangedandtestedtoseewhich combination performs the best. Parameters such as epochs, activation function, dropout and optimizer were taken into consideration and changed so as to find the idealsetuporcombinationforthechosenmodel.
a)Epoch : In machine learning, one entire transit of the trainingdatathroughthealgorithmisknownasanepoch. The epoch number is a critical hyperparameter for the algorithm.Itspecifiesthenumberof epochsorfull passes of the entire training dataset through the algorithm’s trainingorlearningprocess.
b)Activation function : The activation function of a node defines the output of that node given an input or set of inputs. A standard integrated circuit can be seen as a digitalnetworkofactivationfunctionsthatcanbe"ON"(1) or "OFF" (0), depending on input. This is similar to the linearperceptroninneuralnetworks.
c)Dropout : Dropout refers to data, or noise, that's intentionally dropped from a neural network to improve processingandtimetoresults.
The challenge for software-based neural networks is they must find ways to reduce the noise of billions of neuron nodes communicating with each other, so the networks' processing capabilities aren't overrun. To do this, a network eliminates all communications that are transmittedbyitsneuronnodesnotdirectlyrelatedtothe problemortrainingthatit'sworkingon.Thetermforthis neuronnodeeliminationisdropout.
d)Optimizer : Optimizersareusedtoupdateweightsand biasesi.e.theinternalparametersofamodeltoreducethe error.
7) Training
After choosing the configurations of the model, the model is trained on the data that was initially chosen for the purposeoftraining(train-testsplit).Thenumberofepochs chosenwas25forthis.
4. CONCLUSION
Fig2.Training
Bi-LSTM was used in this project to detect sarcasm. The model wasconfiguredinsuchawayastoobtaintheideal values in terms of accuracy and loss. For an ideal model, thebestcasewouldbetohaveahighaccuracyvalueanda low loss value. The values obtained using the Bi-LSTM model were 22.1% and 91.68% for loss and accuracy respectivelywhichwascomparativelyhigherascompared totheothermodelssuchasLSTMandGRU.
Fig3:Results
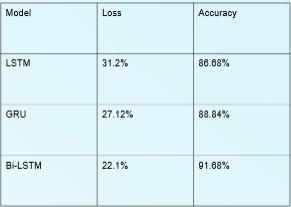
Ascanbeseen,comparedtotheothermodelsusednamely GRU and LSTM. The performance of the chosen model i.e Bi-LSTMisbetterthanthatoftheothers.

5. REFERENCES
[1]AvinashKumar,VishnuTejaNarapareddy,Veerubhotla AdityaSrikanth,ArunaMalapati,andLalitaBhanuMurthy Neti, “Sarcasm Detection Using Multi-Head Attention BasedBidirectionalLSTM”IEEEAccess,Jan-2020
[2] Liyuan Liu, Jennifer Lewis Priestley, Yiyun Zhou, Herman E. Ray, Meng Han, “A2Text-Net: A Novel Deep Neural Network for Sarcasm Detection” 2019 IEEE First International Conference on Cognitive Machine Intelligence(CogMI)
[3] Md Saifullah Razali, Alfiian Abdul Halin, Lei Ye, Shyamala Doraisamy,Norris Mohd Norow, “ Sarcasm
Detection Using DeepLearning WithContextual Features” IEEEAccess,May-2021
[4] Ibrahim Abu-Farha and Walid Magdy, “From Arabic Sentiment Analysis to Sarcasm Detection: The ArSarcasm Dataset” Language Resources and Evaluation Conference (LREC2020)
[5] Deepak Jain, Akshi Kumar, Geetanjali Garg, “Sarcasm detection in mash-up language using soft-attention based bi-directional LSTM and feature-rich CNN” Elseveir Volume-91,June2020
[6] Rolandos Alexandros Potamias, Georgios Siolas, Andreas - Georgios Stafylopatis, “A transformer-based approach to irony and sarcasm detection” Neural ComputingandApplications(2020)
[7] Himani Srivastava, Surabhi Kumari, Saurabh Srivastava,VaibhavVarshney,“ANovelHierarchicalBERT ArchitectureforSarcasmDetection”
[8] Lu Ren, Bo Xu, Hong fei Lin, Xikai Liu, Liang Yang, “ Sarcasm Detection with Sentiment Semantics Enhanced Multi-level Memory Network” Elsevier, Volume 401, August2020
[9] Le Hoang Son, Akshi Kumar, Saurabh Raj Sangwan, Ashika Arora, Anand Nayyar, Mohamed Abdel-Basset, “Sarcasm Detection Using Soft Attention-Based Bidirectional Long Short-Term Memory Model With ConvolutionNetwork”IEEEAccessFeb-2019
[10] News Headlines Dataset For Sarcasm Detection | Kaggle