
Risk Of Heart Disease Prediction Using Machine Learning
Nikitha V P1 , Abhishek2 , Monika R3, Monisha K4 , Vinodh Kumar S52345Students, Computer Science and Engineering, T. John Institute of Technology, Bengaluru, Karnataka, India
1Assoc. Professor, Computer Science and Engineering, T. John Institute of Technology, Bengaluru, Karnataka, India ***

Abstract – Today,theearthisrevolvingatsameratebut people are evolving rapidly. And changing lifestyle of people is main cause for all impacts on human beings. Today, the death rate is 7.6 according to the survey and the main cause of most death is due to heart disease. The changing lifestyle of people have increased the effect on thenormalfunctioningofheart.
This is caused in both men and women but it's more effectiveinmen.Inthisgenerationpeopleofallagegroup have been the predicted to have heart disease from newborn to old aged. The diagnosis isn't easy because death is occurring at first attack on heart. Predicting the risk ofheartdisease will havea bestimpactoncuringthe disease easily. This model helps in predicting of risk of heart disease in human at early stage and immediate precautions can be taken. This machine uses Logistic Regression, Naive Bayes, Support Vector Machine, KNearest Neighbors, Decision Tree, Random Forest, XGBoostandArtificial neural network. The randomforest algorithm plays a vital role in prediction accuracy. The prediction of risk of heart disease can be done for all age groupstoreducethedeathrate.
Key Words: Machinelearning,LogisticRegression,Naive Bayes, Support Vector Machine, K-Nearest Neighbors, Decision Tree, Random Forest, XGBoost and Artificial neuralnetwork
1. INTRODUCTION
The World Health Organization estimates that heart disease accounts for 15 million deaths worldwide each year. Since a few years ago, the prevalence of cardiovasculardiseasehasbeenrisingquicklythroughout the world. Numerous studies have been carried out in an efforttoidentifythemostimportantrisk factorsforheart diseaseandtopreciselyestimatetheoverallrisk.Eventhe silent killer of heart disease, which causes death without outward signs of illness, is addressed. In order to avoid complications in high-risk patients and make decisions about lifestyle changes, early detection of heart disease is crucial. Through the numerous cardiac characteristics of thepatient,wehavebuiltandinvestigatedmodelsfor risk ofheartdiseasepredictioninthisproject.
Thismodelusesrandomforestalgorithmsbycomparing8 algorithm to predict the risk of heart disease. High
accuracy is achieved in this model using Random Forest Algorithm. This Model takes various inputs and predicts the risk of heart disease. The output of the model is a targetvariableisbinaryvalueneither0or1.
1.1 Motivation
Astheheartdiseasebeingmaincauseforthedeathsinthe world and it's been realised that people from all age groups have been predicted to have heart disease. It's importanttopredicttheriskofheartdiseaseatearlystage which helps in diagnosis. This model is developed to predict the risk which as a main strategy to reduce the deathrate.
Also,thismodelcanhelpinsavingalifeandalertpeoplein taking care of themselves if they are at risk ofheartdisease.
1.2 Programming Language
Python is utilised for these projects. Because of its extensive libraries and ease of use for data analysis, manipulation, and artificial intelligence projects, applicationofAIandmachinelearningmodels,etc.Inthis study, Python frameworks are mentioned for the application of various methods for predicting riskofdisease.
2 LITERATURE REVIEW
Numerous studies have been conducted on the diagnosis of heart disease using a variety of variables. In this study, we will compare various classification and regression algorithms. The results showed that RF had the highest accuracy among the algorithms, with a higher accuracy than the other algorithms. By combining PCA and Cluster methods, authors had suggested a Random Forest Classification for Heart Disease Prediction. This study made a substantial addition to the calculating of strength scores with convincing predictions in the prognosis of heart disease. Support Vector Machine, Decision Trees, Random Forest, AdaBoost Classifier, and Logistic Regression are five machine learning methods that have been compared to predict heart disease. When compared to other algorithms, Random Forest provides the highest accuracy, at 85.22%. The system uses the training and testingtechniquetoevaluatealltheparameters.
Python code is used to evaluate the dataset. A Jupyter notebook is used to process the coding language in more detail and evaluate the procedure step-by-step. Phases of testingandtrainingofvariouskindswereused.Intheend, themost accuratetestingandtrainingcombinations were chosenandappliedtotheprocedure.
3. DATASET INFORMATION
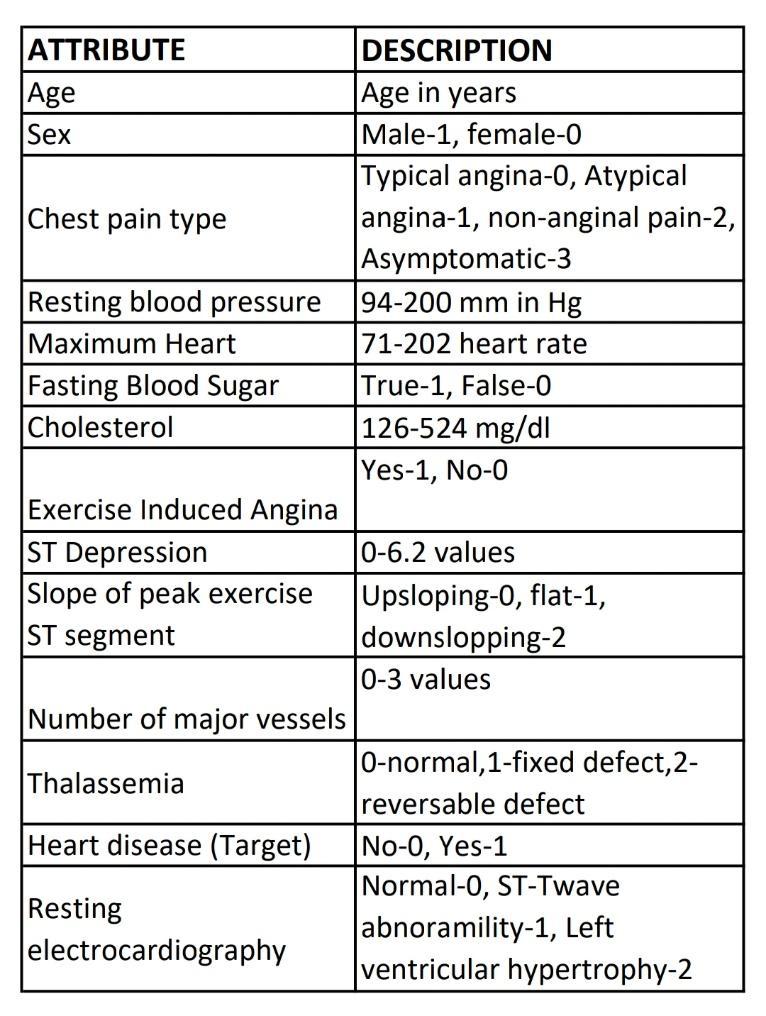
The dataset was compiled using a web-based tool called the UCI repository. These days, data is readily available everyday,thusitisbesttouseadatasetthatisobtainable fromatrustworthysourcewhileimplementingthemodel. Age,gender,fastingbloodsugar,serumcholesterol,typeof chestpain,resultsofrestingelectrocardiograms,exerciseinduced angina, ST depression, slope of peak exercise, resting blood pressure, number of major vessels, thalassemia,andtargetarejustafewoftheattributesand features included in the dataset. There are 270 instances in the collection with 14 attributes. Table 1 provides an overviewofthedataset'suseofnumericalvalues.Figure1 givesusabroadoverviewofthedatabyshowingthat44% ofpatientsdonothaveaheartdiseasediagnosisand56% ofpatientssufferfromthisdisease.
Fig-1:Percentageofheartdisease
3.1 DATASET PREPROCESSING

The pre-processing of the dataset includes procedures such as data correlation, null value verification, loading pythonmodules,andsplittingthedatasetintotrainingand test halves. Pre-processing reveals how the traits are of the data are having an impact on the data. various components of the following testing, training, and correlation data are directly heart disease sickness prognostic. The main element influencing heart disease has been discovered to be the greatest heart rate ever. Qualities that aid in locating the root causes of cardiac disease.
This comprehension stands out because it makes a distinction between factors, both large and little, with relation to the goal value and is extremely helpful even whenthereisalinkbetweenthem.
4. SPLITTING DATA INTO TESTING AND TRAINING
Data correlation, null value verification, loading python libraries, and partitioning the dataset into training and test portions are all steps in the pre-processing of the dataset. Pre-processing provides insight into how the characteristics of the data are influencing the data. Individual elements in the below correlation, testing, and training data are directly predictive of heart disease illness. The primary factor impacting heart disease has been found as the highest heart rate attained. Finally, connection of all features, which helps us identify the causesofheartdisease.
Thisunderstandingisexceptionalbecauseitdistinguishes betweenbigandsmallelementsinregardtothegoalvalue andisextremelyhelpfulevenwhenthereisalinkbetween them.
5. METHODOLOGY
The model uses Random Forest algorithms that performs various process different from one another and while some are similar. All this algorithms are compared to choosethebestalgorithmtoattainimprovedpredictivity.
5.1 LOGISTIC REGRESSION
One of the most often used Machine Learning algorithms, within the category of Supervised Learning, is logistic regression. Using a predetermined set of independent factors, it is used to predict the categorical dependent variable. Inacategoricaldependentvariable,theoutputis predicted via logistic regression. As a result, the result must be a discrete or categorical value. Rather than providing the exact values of 0 and 1, it provides the probabilistic values that fall between 0 and 1. It can be eitherYesorNo,0or1,trueorfalse,etc.
With the exception of how they are applied, logistic regression and linear regression are very similar. While logistic regression is used to solve classification difficulties, linear regression is used to solve regression problems.
5.2 NAÏVE BAYES
The words Naive and Bayes, which make up the Nave Bayesalgorithm,areasfollows:
Because it presumes that the occurrence of one trait is unrelatedtotheoccurrenceofotherfeatures,itisreferred to as naive. A red, spherical, sweet fruit, for instance, is recognisedasanappleifthefruitisidentifiedbasedonits colour, form, and flavour. So, without relying on one another, each characteristic helps to recognise it as an apple. Because it relies on the Bayes' Theorem concept, it isknownastheBayesprinciple.
5.3 SUPPORT VECTOR MACHINE
Oneofthemostwell-likedsupervisedlearningalgorithms, Support Vector Machine, or SVM, is used to solve Classification and Regression problems. However, it is largely employed in Machine Learning Classification issues.
The SVMalgorithm'sobjectiveistoestablish the bestline ordecision boundarythatcandividen-dimensional space into classes, allowing us to quickly classify fresh data pointsinthefuture.Ahyperplaneisthenamegiventothis optimaldecisionboundary.
SVMselectstheextremevectorsandpointsthataidinthe creation of the hyperplane. Support vectors, which are usedto represent these extremeinstances, form the basis for the SVM method. Take a look at the diagram below,
wheretwodistinctcategoriesareidentifiedusingsupport vectorAdvantagesofMisuseAttackDetection.
5.4 K-NEAREST NEIGHBORS
K-Nearest Neighbour is one of the simplest Machine Learning algorithms based on Supervised Learning technique. K-NN algorithm assumes the similarity between the new case/data and available cases and put the new case into the category that is most similar to the available categories. K-NN algorithm stores all the availabledataandclassifiesanewdatapointbasedonthe similarity.This means when newdata appearsthenitcan be easily classified into a well suite category by using KNNalgorithm.
K-NN algorithm can be used for Regression as well as for Classification but mostly it is used for the Classification problems. K-NN is a non-parametric algorithm, which means it does not make any assumption on underlying data.
Itisalsocalledalazylearneralgorithmbecauseitdoesnot learn from the training set immediately instead it stores thedatasetandatthetimeofclassification,itperformsan actiononthedataset.
5.5 DECISION TREE
Adecisiontreeisatypeoftreestructurethatresemblesa flowchart, where each internal node represents a test on an attribute, each branch a test result, and each leaf node (terminalnode)aclasslabel.
By dividing the source set into subgroups based on an attributevaluetest,a treecanbe"trained".Itisknownas recursive partitioning to repeat this operation on each derived subset. When the split no longer improves the predictions or when the subset at a node has the same valueforthetargetvariable,therecursionisfinished.
5.6 RANDOM FOREST
Every decision tree has a significant variance, but when we mix them all in parallel, the variance is reduced since each decision tree is perfectly trained using that specific sampleofdata,andasaresult,theoutputisdependenton numerous decision trees rather than just one. The majority voting classifier is used to determine the final output in a classification challenge. The final output in a regressionproblemisthemeanofeveryoutput.Thispart isAggression.
This method's fundamental principle is to integrate several decision trees to get the final result rather than dependingsolelyononedecisiontree.
Multiple decision trees serve as the fundamental learning models in Random Forest. We carry out random row sampling and further sampling will form datasets for model.Thisiscalledasbootstrap.
5.7 XGBOOST
XgBoost stands for Extreme Gradient Boosting. Gradient Boosted decision trees are implemented using XGBoost technology. Many Kaggle Competitions are dominated by XGBoostmodels.
Decisiontreesaregeneratedsequentiallyinthisapproach. Weights are significant in XGBoost. Each independent variable is given a weight before being fed into the decision tree that forecasts outcomes. Variables that the tree incorrectly predicted are given more weight before being placed into the second decision tree. These distinct classifiers/predictors are then combined to produce a robust and accurate model. It can be used to solve problemsincludingregression,classification,ranking,and customprediction.
5.8 ARTIFICIAL NEURAL NETWORK
Artificial Neural Networks (ANN) are brain-inspired algorithms that are used to foresee problems and model complex patterns. The idea of biological neural networks in the human brain gave rise to the Artificial Neural Network (ANN), a deep learning technique. An effort to simulate how the human brain functions led to the creation of ANN. Although they are not exactly the same, theoperationsofANN and biological neural networks are very similar. Only structured and numeric data are acceptedbytheANNalgorithm.
Unstructured and non-numeric data formats like image, text, and speech are accepted by convolutional neural networks (CNN) and recursive neural networks (RNN). Theonlysubjectofthisarticleisartificialneuralnetworks.
There are three layers in the artificial neural network architecture: the input layer, the hidden layer and the outputlayer.
6 SYSTEM DESIGN
The model is designed using random forest algorithms as mentioned above. All the algorithms are used for various processes like classification, structuring, analysis, prediction, decision making etc. The model takes 14 variables like age, sex, chest pain type, etc to predict the risk of heart disease as input to the algorithm. The algorithm classifies and makes a decision based on the classification.
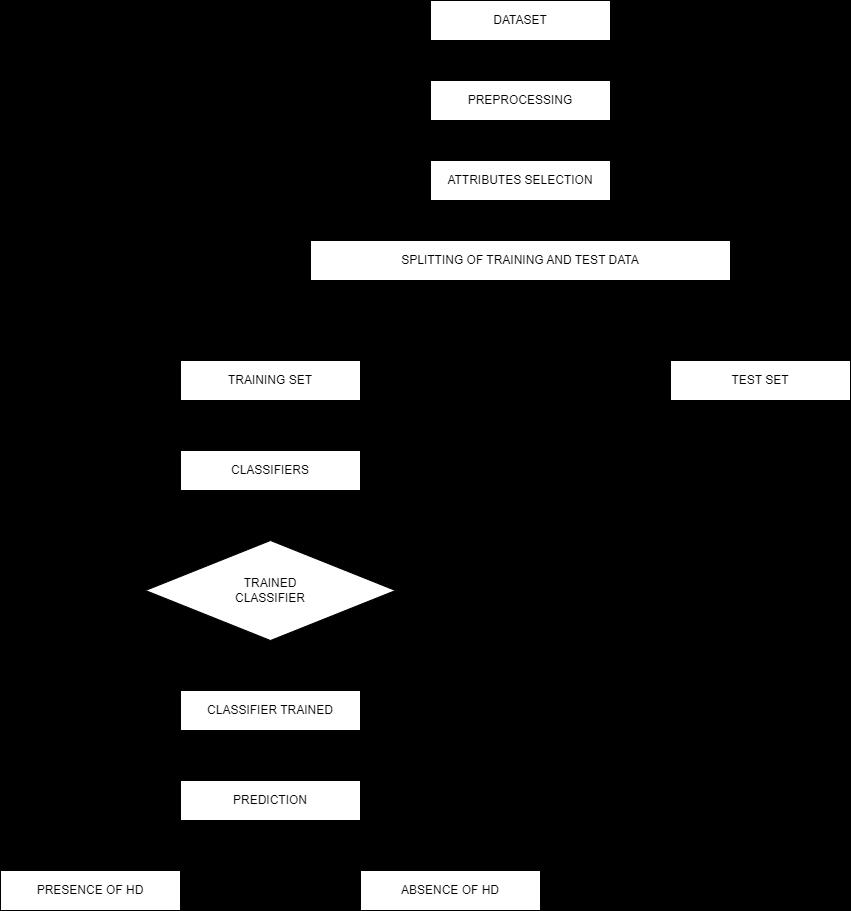
The model gives an output as target value which contains binaryvalueeither0or1.Thepredictionriskmayindicate
the presence of any heart disease related to vessels, structuralproblemsandbloodclots.
Thebelowflowchartindicatestheworkingofmodel:
7 CONCLUSION
The model predicts the risk of heart disease in humans which has become the main cause for the huge deaths occurring in the world. The system uses random forest algorithm to obtain a accuracy of 95%. The algorithm gives output as target value which is either 1 or 0 which indicatesthepresenceifit's1.
The model takes various attribute value to predict the output and each attribute forms a cause for the final output. Datasets are used as input which contains all the attributesvalues.
REFERENCES
[1] Preliminary Design of Estimation Heart disease by using machine learning ANN within one year DOI: 10.1109/rICT-ICeVT.2013.6741541
[2] Prediction of Heart Disease Using Learning Vector Quantization Algorithm DOI: 10.1109/CSIBIG.2014.7056973
[3] UsingtheExtremeLearningMachine(ELM)technique for heart disease diagnosis DOI: 10.1109/IHTC.2015.7238043
[4] Study of Machine Learning Algorithms for Special Disease Prediction using Principal of component analysisDOI:10.1109/ICGTSPICC.2016.7955260
[5] CouplingiffastFouriertransformationusingmachine learning ensemble model Support recommendation forHeartdiseasepatientsinatelehealthenvironment DOI:10.1109/ACCESS.2017.2706318
[6] Prediction of Heart Disease Using Machine Learning DOI:10.1109/ICECA.2018.8474922
[7] Prediction of Heart Disease Using Machine Learning AlgorithmsDOI:10.1109/ICIICT1.2019.8741465
[8] Heart Disease Identification Method Using Machine Learning Classification in E-Healthcare DOI: 10.1109/ACCESS.2020.3001149