
Sentiment Analysis on Product Reviews Using Supervised Learning Techniques
Siddhes Tripathy[a]



 , Ankit Pradhan [a], Dibya DasMohapatra[a], Narayan Sharma[a], Mr. Ramesh Jana[a]
, Ankit Pradhan [a], Dibya DasMohapatra[a], Narayan Sharma[a], Mr. Ramesh Jana[a]

a Department of computer science and engineering, Balasore college of engineering and technology, Odisha, India
*Corresponding Author: Siddhes Tripathy
***
Abstract: This paper represents a comparison between three Machine learning approaches for analysing the sentiment of the Customer’s reviews on various products. Eventually, reviews of a Product help the customers to understand the product quality. It involves computational study of behaviour of an individual in terms of his buying interest and then mining his opinions about company’s Business entity. In this paper, dataset has taken from Amazon.com, Flipkart.com which contains reviews of Alexa’s Mobile Phones. After pre-processing, we applied Machine Learning Algorithms to classify the reviews or opinions that are positive or negative Behaviour.
Keywords: Sentiment Analysis, Natural Language Processing, Product reviews, Machine Learning, Classifiers.
I. INTRODUCTION
Nowadays, people are mostly interested in trading products on e-commerce websites instead of the offline market becauseoftimeefficiencyandconventionalproperty.Inelectroniccommerce,productreviewsareusedonshoppingsites to give customers an opportunity to rate and comment on products they have purchased, right on the product page. A commonsituationistogothroughareviewoftheproductbeforebuying.So,thereviewsoftheproducthaveinclinedthe consumerpositivelyornegatively.Ontheotherhand,readingthousandsofreviewsisaninhumanaccomplishment.Inthis era of growing machine learning-based algorithms, it is rather time-consuming to go through thousands of remarks to discern a product where a review of a specific category can be polarized to know its popularity among consumers worldwide.
Sentimentanalysisisthepartoftextminingthatattemptstodefinetheopinions,felling,andattitudespresentinatextor setoftexts.Onlinereviewsaresoimportanttobusinessesbecausetheyultimatelyincreasesalesbygivingtheconsumers the information, they need to make the decision to purchase the product. One very important factor in elevating the reputation, standard, and evaluation of an e-commerce store is product review. Product review is the most valuable resourceavailableforCustomerFeedback.
This paper aims to categorize customers’ positive and negative feedback on distinct products and create a supervised learningmodeltopolarizeawiderangeofreviews.Lastyear,researchonamazondisclosedmorethan88 percent [1] of internetshopperstrustreviewsasmuchasaprivaterecommendation.However,anyonlineproductwithabig numberof favourable reviews offers the item’s legitimacy with a power remark. On the other hand, without reviews, electronic gadgetsoranyotheritemonlineputsprospectivepotentialinastateofdistrust.
Sentiment analysis helps to analyse these opinioned data and extract some important insights which will help to other usertomakedecision.
In this research paper, pre-processing is performed to reduce the dimensionality of the features applying the MultiDomain Sentiment Dataset [2]. Later, all frequent words beyond threshold value are considered as features. After Complete extraction, three machine learning algorithms have been applied to find the best potential based on statistical analysis.
II.LITERATURE REVIEW
1 Research on Aspect-Level SentimentAnalysis Based on Text Comments
Jing Tian, Wushour Slamu, Miaomiao Xu, Chunbo Xu and XueWang[3]
2022 It is found that, there are affective regions that evoke human sentiment inanimage.
In the problem of comparative level sentences, where it is difficult to judge polarity of the comment.
NLP, combines capsulenetwork and BERT and CapsNet-BERT.
2 SentimentAnalysis Using Product ReviewData
Xing Fang, Justin Zhan[4]
2015 In this paper, experiments for both sentencelevel categorization and review-level categorization for sentiment analysis.
Review-level categorization becomes difficult if we want to classify reviews to their specific star-scaled ratings.
Scikitlearn(software), Models like Naïve Bayesian, Random Forest, and Support VectorMachine.
3 Soft Computing Approaches to Classification Of Email for Sentimental Analysis
4 Random Forest and Support Vector Machine based Hybrid Approach to Sentiment Analysis.
5 A Comparative Study of Support Vector Machine and Naïve Bayes Classifier for Sentimental Analysis on Amazon Product Reviews
Mrs. Pranjal S. Bogawar and K.K.Bhoyar
2016 It’s helpful to clustering and classifying emails into different categories.
Clustering algorithm performing well due to future in identifying negative emails.
Expectation Maximization (EM),K-Means, Agglomerative Algorithm.
Yassine Al Amrani, Mohammed Lazaar, Kamal Eddine El Kadiri [5]
2018 Trackingthemood ofthepublicabout a particular product.
Using a hybrid classification methodology is better than use of the individual classification method.
Supervised learning: Random forest, SVM,RFSVM.
Sanjay Dey, Sarhan Wasif, Dhinman Skider Tommoy, Subrina Sultana [6]
2020 Mutiple review factors, including product quality, content, time of the reviews will helpful for the customer.
Does not work with multiplewordphrases.
NLP, SVM and Naïve Bayes classifier.
To sum up, no research work has provided a comparison between the support vector machine, the Naïve Bayes, and the Logistic Regression classifier. Later, in this work a comparison between three machine learning approaches has been presentedforanalyzingthesentimentofthecustomers’reviewsonproduct.



III. METHODOLOGY
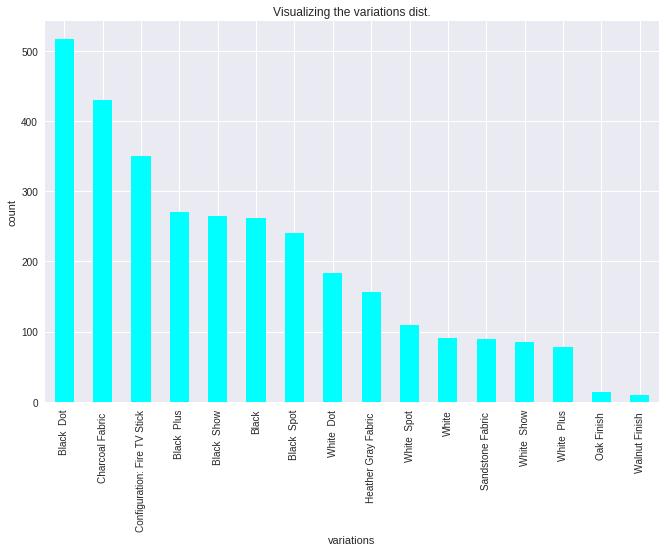
Amazon, Flipkart are the largest e-commerce sites as it is possible to see countless reviews. The dataset was unlabelled anditmustbelabelledinordertouseitinsupervisedlearning model.Eventually,thisresearchhasonlyworkedwiththe feedbacks of e-commerce product like Alexa and Mobile Phone. Almost 1946 reviews of the 1918 reviews of the Mobile Phonesand3106reviewsoftheAlexa havebeen processes fortheanalyzingthepolarization.Meanwhile,Fig.1hasbeen illustratedtheoverviewofthesystemmethodology.
A:DataAcquisition
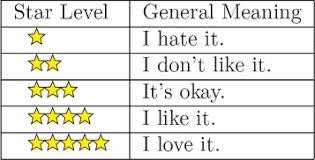
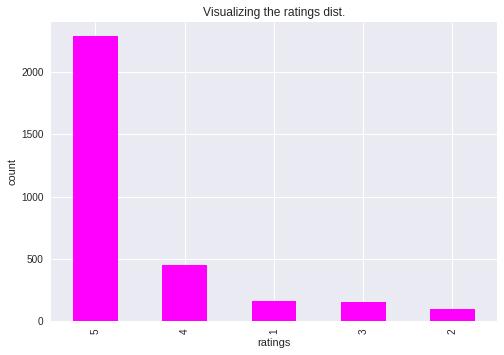
Data Acquisition has been proceeded in the very first step for labelling the data. As the dataset consist of many reviews, manual labelling is quite impossible for a human being. Therefore, after the completion of pre-processing dataset, the active learner has been implemented to label the datasets. As product feedbacks come in 5-star ratings,3-star rating is usuallyregardedasneutralreviewsmeaningneithernegativenorpositive.So,thesystemhasbeendiscardedanyreview whichcontainsa3-starratingfromdatasetandhasbeentakentheotherreviewsforproceedingtothenextstepleadingto pre-processingstep.
B:DataPre-processing
Pre-processingdatacomprisesofthreestepscalledtokenization,removingstopwordsandPOStagging
1) Tokenization: It is the method of separating a string sequence into individuals such as keywords, symbols, phrases, and other elements called tokens. Eventually, tokens can be phrases, words, or even entire sentences. However,somecharacterssuchaspunctuationmarksareremovedinthetokenization phase.Thetokensarethe inputforvariousproceduressuchasparsingandtextmining.
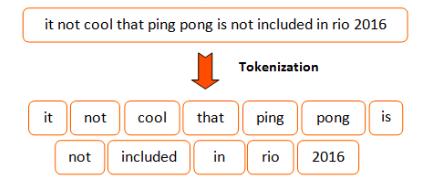
2) Removing stop words:Stopwordsareitemsinaphrasethatarenotessentialintextminingforanydivision.In ordertoimprovetheprecisionoftheassessment,thesewordsareusuallyignored.Therearedistinctstopwords invariousformatsdependingontherealm,language,andsoon.However,thereareseveralstopwordsinEnglish format.
3) POS tagging: The process of assigning one of the parts of speech to the given word is called part of speech tagging. It is generally referred to as POS tagging. Parts of speech generally contains nouns, verbs, adverbs, adjectives,pronoun,conjunction,andtheirsub-categories.PartsofspeechtaggerorPOStaggerisaprogramthat doesthisjob.
C.FeatureExtraction
Feature of the dataset has been extracted by the three method steps named term Bag of Words, Frequency-inverse documentfrequency(TF-IDF),Relevantnounremoval.
1) Bag Of Words: Bag of words is a process of extracting features by representing simplified text or data, used in natural language processing and information retrieval. In this model, a text or a document is represented as the bag(multipleset)ofitswords.So,simplybagwordsinsentimentanalysisiscreatingalistofusefulwords.
2) TF-IDF: TF-IDF isatechniqueforretrievinginformationthatweighsthefrequencyofateam(TF)andtheinverse frequency of document (IDF), Every word or phrase has its score TF and IDF. Meanwhile, A term’s TF and IDF productresultsrefertothatterm’sTF-IDFweight.
3) Relevant noun removal:Thelistofmostfrequentnounsdoesnothavealwayscoverallimportantfeaturesbeing commented on. There have been still some features mentioned in a smaller number of opinions that have been also important to be extracted by the system. Henceforth, refinement of the relevant noun, which has been selectedasinfrequentnounsdenotedbycandidatefeaturesbasedonopinionwords.
Algorithm for the System






1) TakingInput
2) Pre-processingthedata
a) Removingblankrows
b) Changingalltexttolowercase
c) Tokenizationwillbreakdataintowords
d) Removingstopword
3) Splittingthedatasetintotrain-setandtest-set
4) VectorizationthewordsbyusingTF-IDFvectorizer
5) Runningdifferentclassifierstoclassifythedataset
6) Labellingtheencodedtargetvalue
IV: SPLITTING DATA
In this phase, we are splitting the dataset for two different purposes: training and testing. The training subset is for building the model and testing subset is to evaluate the performance of the model in this model. In this paper, we are splittingthedatasetinto90%fortrainingand10%fortesting.
V: APPLIED ALGORITHM/CLASSIFICATION
Inthiswork,wewillapplytreesupervisedlearningalgorithms
Machine Learning Approach
Fig4-Classificationofsentimentanalysis
Recently, sentiment analysis has attracted an increasing interest. It is a hard challenge for language technologies, and achievinggoodresultsismuchmoredifficultthansomepeoplethink.Thetaskofautomaticallyclassifyingatextwrittenin a natural language into positive or negative feeling, opinion, or subjectivity is sometimes so complicated that even different human annotators disagree on the classification to be assigned to given text[7]. Personal interpretation by an individual is different from others, and this is also affected by cultural factors and each person’s experience. And the shorterthetext,andtheworsewritten,themoredifficultthetaskbecomes,asinthecaseofmessages onsocialnetworks [8].
Afterpre-processingandfeatureextraction,westarttoclassifythereviews.Inthispaper,afterwearesplittingthedataset inbothtrainingandtestingset,wecaninputtheminthefollowingclassifier’s:
A) Naïve Bayes: The main idea of the idea of this classifier is hypothesis that predictor variables are autonomous whichsubstantiallyminimizesthecomputationofprobabilities.Itgivesexcellentresults,anditwasusedinmost research [9].
B) Support Vector Machine: It is potential classification technique, and is a supervised learning model with associatedlearningalgorithmsthatanalyzedataforclassification.
C) Logistic Regression: It is a supervised machine learning technique for classification problems. The goal of the model is to learn and approximate a mapping function f(Xi)=Y from input variable {x1, x2, xn} to output variable(Y).It iscalledsupervised becausethe model predictionsareiteratively evaluatedandcorrectedagainst theoutputvalues,utilanacceptableperformanceisachieved.
VI: EXPERIMENT RESULT
This section intends to evaluate the performance of these three machine learning models through several experiments Evaluating metrics play a significant role in measuring the efficiency of classification where measuring accuracy of classification where measuring accuracy is the most convenient for this purpose. Eventually, a classifier’s precision on a given test dataset is the percentage of those datasets that the classifier properly categorizes. The system is evaluated by threecommonlyusedstatisticalmeasurenamedrecall,precision,andF-measurefromwiththehelpofconfusionmatrix.
The data from the confusion matrix are classified into four categories named as True Positive (TP), True Negative (TN), False Positive(FP) and False Negative(FN). True positive present an outcome where the system perfectly predicts the positive class. On the hand FP identifies an outcome where the positive class is incorrectly predicted by the scheme. Meanwhile,TNistheresultwherethesystemdivinestheadverseclassexactly.Onthecontrary,FNisanoutcomewhere thenegativeclassisincorrectlypredictedbythesystem.
TABLEI
CONFUSIONMATRIXFORSUPPORTVECTORMACHINEOFALEXADATASET
PrecisionisthepredictiveratioamongthetotalPositiveinstancedenotedbytheequation(1).
Precision=TP/TP+FP (1)
TABLEII
CONFUSIONMATRIXFORNAÏVEBAYESCLASSIFIERSOFALEXADATASET
TABLEIII
CONFUSIONMATRIXFORLOGISTICREGRESSIONOFALEXADATASET
TABLEIV
CONFUSIONMATRIXFORSUPPORTVECTORMACHINEOFMOBILEDATASET
TABLEVI
CONSFUSIONMATRIXFORNAÏVEBAYESCLASSIFIERSOFMOBILEDATASET
TABLEVII CONFUSIONMATRIXFORLOGISTICREGRESSIONOFMOBILEDATASET
Theequation(2)whichintroducestheschemeproperlyclassifiesthebeneficialclassesoutofallclassesdenotesrecall.
Recall=TP/TP+FN (2)
F1 score analyses accuracyand recall at the same time using harmonic mean instead of the arithmetic mean denoted by equation(3).
F1score=2xRecallxPrecision/Recall+Precision (3)
Accuracyistheproportionofallspecimensoftheclassandthecumulativenumberofsamplesdenotedbyequation(4).
Accuracy=TP+TN/TP+TN+FP+FN (4)
VII: CONCLUSION AND FUTURE WORK
Thisresearchwasabletopresentacomparisonstudyamongthreealgorithms SVM,NaïveBayesandLogisticRegression to analyse the polarization of the sentiment of product reviews. In this work, the models were trained by almost 2500 featureswithalmost6000datasetsafter the pre-processing procedure. In the meantime, almost4000 testsethavebeen passedthroughthemodelsforthestatistical measurement. Experimentalresultshaveconfirmedthatthesupportvector machinecanpolarizethefeedbackoftheproductreviewswithahighaccuracyrate.
Somefutureworkswhichcanbeincludedtoimprovethemodelandtomakeitmoreeffectiveinpracticalcases.Ourfuture works include applying PCA (Principal Component Analysis) [10] in active learning process to fully automate data labellingprocesswithlessassistancefromtheoracle. Andlastly,wewilltrytocontinuethisresearchuntilwegeneralize thismodeltoallkindsoftext-basedreviewsandcomments.
VIII: REFERENCES
[1] T.U Haque, N.N. Saber and F.M. Shah, “Sentiment analysis on large scale amazon product reviews,” in 2018 IEEE InternationalConferenceonInnovativeResearchandDevelopment(ICIRD).
[2] J.H.W.S.o.E. Department of CSE. Multi-domain sentiment dataset, Available: http://www.cs.jhu.edu/mdredze/datasets/sentiment/
[3] Jing Tian, Wushour Slamu and Miaomiao Xu, “Research on Aspect-Level Sentiment Analysis Based on Text Comments”,in2022,Available:https//www.mdpi.com/journal/symmetry.
[4] Xing Fang and Justin Zhan, “Sentiment analysis of Product Review”, in 2018 International Journal of Innovations in EngineeringandScience.
[5] YassineAlAmrani,MohammedLazaarandKamalEddineElKadiri,”RandomForestandVectorMachinebasedHybrid ApproachtoSentimentAnalysis”,in2018,Availableatwww.sciencedirect.com.
[6] SamjayDey,SarhanWasifandDhimanSikderTonmoy,”AComparativeStudyOfSupportVectorMachine andNaïve Bayes Classfier for Sentiment Analysis on Amazon Product Reviews”, in 2020 IEEE International Conference on ContemporyComputingandApplication(IC3A).
[7] Xia, Rui, Chengquing Zong, and Shoushan Li. “Ensemble of feature sets and classification algorithms for sentiment classification,”InformationSciencevol.181,issue6,15Mar.2011.
[8] Melville,Prem,WojeiechGryeandRichardD.Lawrence.“Sentimentanalysisofblogsbycombininglexicalknowledge with lexical knowledge with text classification,” Proceedings of the 15th ACM SIGKDD International conference on knowledgediscoveryanddatamining,2009.
[9] Huma Parveen and Prof. Shikha Pandey,” Sentimental analysis on twitter data-set using naïve bayes algorithm”, Publishedin2016Internationalconferenceonappliedandtheoreticalcomputingandcommunicationtechnology.
[10] G. Vinodhini, RM. Chandrasekaran,” Sentiment classification using principal component analysis based neural networkmodel”,Internationalconferenceoninformationcommunicationandembeddedsystemin2014.