
UTILIZING TWITTER TO PERFORM AUTONOMOUS SENTIMENT ANALYSIS
SrivastavaAbstract - Applications in many domains make Sentiment Analysis an exciting area for study. The use of online polls and surveys to get feedback from the public regarding goods, current events, and societal or political issues are on the rise. The public and the stakeholders benefit from hearing the thoughts and feelings of the general public when important choices must be made. Opinion mining is the practice of gleaning insights from online sources including web search engines, blogs, micro-blogs, Twitter, and social networks to produce meaningful conclusions. Twitter's user base provides a wealth ofmaterial from which to get insight intothepublic's perspective. The massive volume oftweets as theunstructured text makes it challenging to physically delineate the information. Consequently, extracting and condensing the tweets from corpora calls for expert computational methodologies, which in turn necessitates familiarity with terms that convey emotion. Sentiment analysis from the unstructuredtext may be accomplishedusingawidevarietyof computer methodologies, models, and algorithms. The vast majority are based on machine learning methods, namely the Bag-of-Words (BoW) representation. Inthisresearch,weused a lexicon-based strategy to automatically identify sentiment for tweets gathered from the Twitter public domain. To further investigate the efficacy of alternative feature combinations, we have used three distinct machine learning algorithms for the task of tweet sentiment identification: Naive Bayes (NB), Maximum Entropy (ME), and Support Vector Machines (SVM). Our results suggest that bothNBwith Laplace smoothingandSVM are successful incategorizingthe tweets. The feature usedfor NBis unigramandPart-of-Speech (POS), while unigram is utilized for SVM.
Key Words: Bag-of-Words, Lexicon, Machine Learning Algorithms,LaplaceSmoothing,Part-of-Speech.
1. INTRODUCTION
It has been found via two separate polls of over 2000 American adults that 81% of Internet users (or 60% of Americans)havedoneproductresearchonlineatleastonce andthat20%ofInternetusers(15%ofAmericans)preferit onacertainday.Wemayclaimthatpeople'sconsumptionof goods and services is not the only factor for their online information-seekingandopinion-sharingactivities.Theneed foraccesstocurrentpoliticalinformationisanothercritical factor to consider. At the moment, individuals may utilize email for political campaigns by sharing information and discussing candidates and issues online. The user trusts
internetadviceandsuggestionssincetheydealmostlywith an opinion. Despite the generally pleasant experiences of American Internet users during online product research, Horrigan[1]foundthat58%ofusersreportedexperiencing missing, difficult-to-discover, confused, or overwhelming onlineinformation.Therefore,thereisasignificantneedfor improvedinformation-accesstechnologiestoaidshoppers andresearchers.Web2.0siteslikeblogs,messageboards, andotherkindsofsocialmediahavemadeiteasierthanever for customers to voice their thoughts and views on the brandstheyuse.Inrecentyears,businesseshavebegunto acknowledgethepowerthatuserreviewshaveonshaping theperceptionsofothersandthestandingofcertainbrands. Companiesarebeginningtowatchsocialmediatoreactto customer feedback and adjust their marketing, brand positioning, product development, and other strategies appropriately.
1.1. Opinion Mining and Sentiment Analysis

Extractingviewsfromtextiscalled"OpinionMining"(OM). Viewpointmining(OM)isanewfieldattheintersectionof information retrieval, text mining, and computational linguistics that seeks to detect the opinion represented in natural language texts, as described by Pang et al. [3]. Opinion mining is a subfield of KDD that employs Natural LanguageProcessing(NLP)andstatisticalmachinelearning methods to identify and distinguish between opinionated andfactualcontent.Tasksinopinionminingincludelocating opinions, labeling them as favorable, negative, or neutral, determining where those opinions originated, and summarisingthem.Toautomaticallyextractasummaryof anentity'sopinionfromalargebodyoftheunstructuredtext istheprimarygoaloftheOpinionMiningassignment.
OpinionMiningandSentimentAnalysis(SA)aretwonames for the same thing: the study of how people feel about something. An individual's thoughts, feelings, and impressionsaboutamatter,asexpressedintheformofan opinion,aredeeplypersonal andconfidential.Individuals, groups, and societies may benefit greatly from the advice and counsel of others throughout the decision-making process, as concluded by the work of Liu et al. [2]. To act swiftlyandwisely,humansdemandinformationthatisboth preciseandbrief.Whilemakingachoice,peopleoftenseek advicefromfriends,family,andexpertsforwhomtheyhave developedanopinionorpointofviewbasedontheirown
experiences,observations,conceptions,andbeliefs(which mayormaynotbegoodornegative).
2. SENTIMENT TARGET IDENTIFICATION
Identifyingsentiment(opinion)targetsisacrucialpartofSA work.Theaimheremightbeanythingfromthesubjectof the statement to the object of that statement. Everyone involved in making and selling a product has to do a thorough evaluation of it in light of public and buyer feedback.Automaticallyidentifyingandextractingaspects mentionedinreviewsisakeystepinconductingareview comparison.Opinionminingandsummarization,thus,rely heavilyonproductfeaturemining[10].Sentimentanalysisis adifficultfieldofstudy.Thisisbecauseasystemhastobe able to discern evaluative expressions and some qualities thatarenotovertlypresentandneedtobeidentifiedfrom thetermsemantictocorrectlyidentifyopiniontargetsina phrase or document. Previous studies on the topic of sentiment target identification have shown that several Natural Language Processing (NLP) methods, including processing,Part-of-Speechtagging,noisereduction,feature selection,andclassification,areallnecessarystagesinthe extractionprocess.
3. METHODOLOGY
Researchdatacollectingismorecomplexthanitmayseem sinceitrequiresdrawingimportantandrelevantinferences. Testdata,subjectivetrainingdata,andobjective(neutral) training data are the three types of data that have been gathered.TheTwitterAPIwillbecoveredbeforehand.
3.1. Twitter API
Developers may access Tweets, DMs, media, and other Twitter data using the Twitter API, which provides a collection of programming interfaces. Through the API, programmersmaycreateproductsthatcommunicatewith the Twitter service and carry out actions like publishing Tweets, getting user information, and viewing trending topics, among other things. Different endpoints, authenticationmechanisms,anduseconstraintsapplytothe API'sseveralflavors,whichincludeREST(Representational State Transfer), streaming, and advertising. A Twitter developer account and API keys (also known as access tokens)areprerequisitesforinteractingwiththeAPI.
3.2. Twython
TwythonisaPythonlibraryforaccessingtheTwitterAPI.It providesasimpleandconvenientwayforPythondevelopers tointeractwiththeTwitterplatformandperformtaskssuch aspostingTweets,retrievinguserinformation,andaccessing timelines.Twythonabstractsmanyofthecomplexitiesofthe Twitter API and provides a simple, Pythonic interface for accessingtheAPI'sresources.TouseTwython,youwillneed toobtainAPIkeysoraccesstokensfromaTwitterdeveloper account, and then use these credentials to initialize a
Twython client object, which you can use to make API requests. The library supports both REST and Streaming APIsandincludesfunctionalityforOAuth1.0aandOAuth2.0 authentication.
3.3. Data Preprocessing in Twitter
Data preprocessing in Twitter involves cleaning and transformingTwitterdataintoaformatthatissuitablefor furtheranalysisormodeling.Thismayincludetaskssuchas:
1. DataCollection:CollectrawdatafromtheTwitter API,suchastweets,userprofiles,andtrends.
2. Data Cleaning: Removing irrelevant information, correcting errors, handling missing values, and removingduplicatesfromthecollecteddata.
3. Text Processing: Processing textual data from tweets, such as removing stop words, stemming, andconvertingtexttolowercase.
4. SentimentAnalysis:Classifyingtweetsintopositive, negative,orneutralsentimentcategories.
5. Data Transformation: Converting the data into a format that is suitable for analysis, such as converting textual data into numerical representations.
6. DataReduction:Reducingthedimensionalityofthe data,suchasaggregatingdatabyuserorperiod.
Thesestepsensurethatthedataisinaclean,consistent,and usableformat,andhelpimprovetheaccuracyandreliability ofanysubsequentanalysisormodeling.
3.4. Lexicon-Based Approach
Thelexicon-basedapproachisamethodusedinsentiment analysis and opinion mining to classify the sentiment of a piece of text, such as a tweet, into positive, negative, or neutralcategories.Theapproachinvolvesusingapredefined lexicon,oralistofwords,thatareassociatedwithspecific sentiments.
Inalexicon-basedapproach,thesentimentofapieceoftext isdeterminedbycountingthenumberofwordsinthetext that match words in the lexicon and then aggregating the sentimentscoresassociatedwiththesewords.Theresulting sentimentscoreisthenusedtoclassifythetextaspositive, negative,orneutral.
There are many different lexicons available for use in sentimentanalysis,eachwithitsstrengthsandweaknesses. SomepopularlexiconsincludeSentiWordNet,theHarvardIV dictionary,andtheAFINNlexicon.
Thelexicon-basedapproachissimpletoimplementandhas been widely used in sentiment analysis. However, it has somelimitations,suchasbeinglimitedtothewordsinthe lexicon and not taking into account the context in which words are used. To overcome these limitations, other
approaches such as machine learning and deep learning modelshavebeendeveloped.
3.5. SentiWordNet
SentiWordNetisalexiconforsentimentanalysisandopinion mining.Itisamanuallyconstructed,multi-wordexpression resourcefortheEnglishlanguagethatprovidessentiment scoresforwordsandphrases.
SentiWordNetassignssentimentscorestowordsbasedon threedimensions:positivity,negativity,andobjectivity.Each word in the lexicon is associated with three sentiment scores,representingitspositivity,negativity,andobjectivity. Thescoresarebasedonthecollectivesentimentofwords thataresemanticallysimilartothewordbeingscored.
SentiWordNet can be used as a resource in sentiment analysis and opinion mining to classify the sentiment of a pieceoftextintopositive,negative,orneutralcategories.To do this, the sentiment scores of the words in the text are aggregatedtodeterminetheoverallsentimentofthetext.
SentiWordNethasbeenwidelyusedinsentimentanalysis andhasbeenshowntoperformwellincomparisontoother lexicons and machine learning models. It is a valuable resource for researchers and practitioners in the field of sentimentanalysis.
4. RESULTS AND ANALYSIS
4.1. Naive Bayes
Naive Bayes is a simple probabilistic classifier based on Bayes' Theorem. It is a popular algorithm in the field of machinelearningandiswidelyusedfortaskssuchastext classification,sentimentanalysis,andspamfiltering.
ThebasicideabehindNaiveBayesistouseBayes'Theorem tocalculatetheprobabilityofaclass(e.g.,positive,negative, orneutralsentiment)givenasetoffeatures(e.g.,wordsina text). The algorithm assumes that the features are conditionallyindependent,meaningthatthepresenceofone featuredoesnotaffectthepresenceofanotherfeature.This isthe"naive"partofthealgorithm,henceitsname.
There are several variants of the Naive Bayes algorithm, including the Multinomial Naive Bayes, Bernoulli Naive Bayes,andGaussianNaiveBayes.Eachvariantissuitedfor differenttypesofdataanddifferentclassificationtasks.
Naive Bayes is a fast and effective algorithm for text classification and sentiment analysis. It is simple to implementandrequireslittledatapreparation.However,its performance can be limited by the "naive" assumption of independence between features, which is not always accurate in practice. Despite this, Naive Bayes remains a popular and widely used algorithm in the field of text classificationandsentimentanalysis.
4.2. For Twitter Dataset
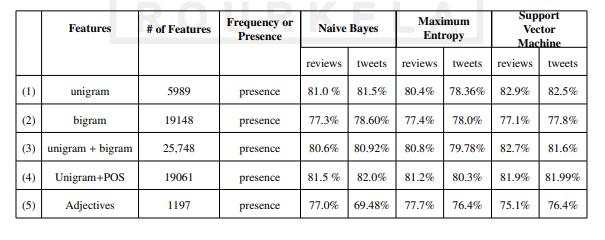
We investigate a wide rangeofcharacteristicsthat havea significantimpactonsentimentanalysis.Wehavemadeuse ofN-gramfeaturessuchasunigrams(n=1)andbigrams(n =2),whichareusedofteninavarietyoftextclassifications includingsentimentanalysis.Inthecourseofourresearch, we played around with boolean features using both unigramsandbigrams.Eachn-gramfeaturehasaboolean valuethatisconnectedwithit.Thisvalueissettotrueifand onlyifthecorrespondingn-gramappearsinthetweet[12]. The many characteristics that we have employed are outlinedinTable1,alongwiththeaccuracyresultsobtained fromeachparticularclassifier.Acomparisonofthisdataset withtheonethatPangLeeetal.utilizedfortheirresearchon moviereviewshasbeencarriedouthere.Accordingtowhat was found in Table 1, the classification accuracies that resultedfromusingunigramsasfeaturesgavebetterresults inthecaseoftweetsthanmoviereviewswhenweusedthe NB classifier with Laplace smoothing; however, when we used the MaxEnt classifier, the accuracy result of movie reviewswasmorethanthetweets.
We investigate a wide rangeofcharacteristicsthat havea significantimpactonsentimentanalysis.Wehavemadeuse ofN-gramfeaturessuchasunigrams(n=1)andbigrams(n =2),whichareusedofteninavarietyoftextclassifications includingsentimentanalysis.Inthecourseofourresearch, we played around with boolean features using both unigramsandbigrams.Eachn-gramfeaturehasaboolean valuethatisconnectedwithit.Thisvalueissettotrueifand onlyifthecorrespondingn-gramappearsinthetweet[12]. The many characteristics that we have employed are outlinedinTable1,alongwiththeaccuracyresultsobtained
fromeachparticularclassifier.Acomparisonofthisdataset withtheonethatPangLeeetal.utilizedfortheirresearchon moviereviewshasbeencarriedouthere.Accordingtowhat was found in Table 1, the classification accuracies that resultedfromusingunigramsasfeaturesgavebetterresults inthecaseoftweetsthanmoviereviewswhenweusedthe NB classifier with Laplace smoothing; however, when we used the MaxEnt classifier, the accuracy result of movie reviewswasmorethanthetweets.
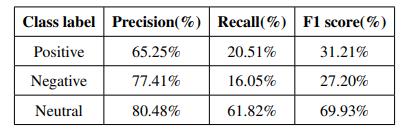
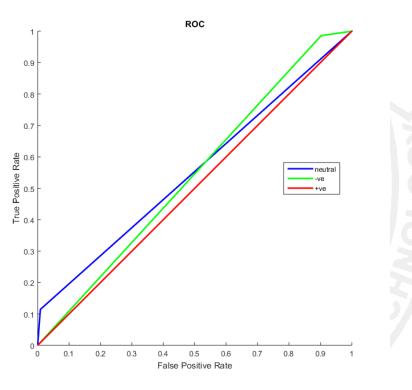
TheeffectivenessofPOSfeatureshasbeenvalidatedusing sentimentanalysis.Asageneralrule,adjectivesareregarded asusefulcomponentsforsentimentanalysissincetheyserve as reliable indicators of a subject's feelings. Taking into account solely adjectives provides results that are comparabletothoseproducedbyemployingunigramsand bigrams,ascanbeseeninLine(5)ofthetabledisplayingthe resultsofourexperiment.Line(4)ofthetabledisplayingthe resultsdemonstratesthatwhenunigramsandPOSareused asa feature,all threeclassifiersgeneratesuperior results. Thefirstlineofthetabledisplayingtheresultsdemonstrates that using SVM with unigram as a feature yields the best result out of all the characteristics that were taken into consideration. The comprehensive findings of the MNB classifier may be seen in Table 2, which displays the F1 score.TheReceiverOperatingCharacteristic(ROC)curveof the MNB classifier is shown in Figure 1. This curve is for tweetsthathavebeenmanuallyannotated.
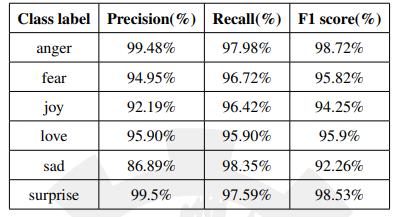
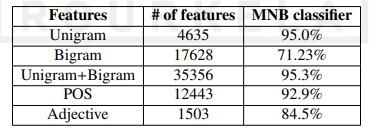
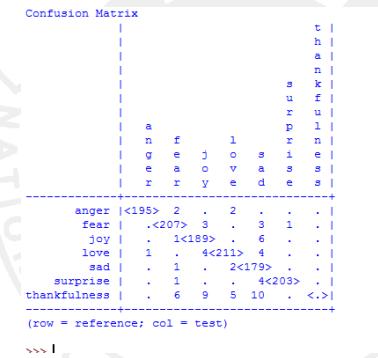
beenincludedinourmachine-learningalgorithmtoprovide it with more data. Figure 2 depicts a snapshot of the confusionmatrixforouremotiondataset'sunigramfeatures. Additionally, the F1 score of each class for the unigram featureisshowninthisfigure.Figure3showstheROCcurve thatwasgeneratedbyourclassifier.
4.3.
Hashtags are often used as a means for people to communicate their thoughts and feelings. Therefore, a satisfactory amount of feelings and sentiments may be gleanedfromthesehashtaggedphrases.Thesehashtagshave
Figure 3: ROC curve of MNB classifier for an emotion data set
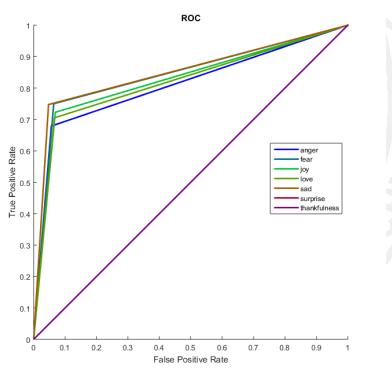
When compared to the data set that is generated by manuallyannotatingtweets,weobservedthatconstructinga dataset by automatically collecting tweets via the use of hashtagsdemonstratesa clearadvantage.Thiswasoneof thefindingsofourexperiment.Thisisbecauseauthorsare accurateabouttheirfeelings,buttheconventionalmethodof annotatingmaterialrequiresannotatorstoinferthewriters' feelingsfromthetext,whichisnotpossibletodoaccurately.
5. CONCLUSION
As part of our study, we looked at the difficulties of Sentiment Analysis and the many approaches used in this area. Identification of sentiment in social media data is notoriously challenging due to the data's richness and subtlety.Todeterminewhichcharacteristicsaremostuseful for Sentiment Analysis, we experimented using tweets collected from the public domain. We have used Machine Learningandlexicon-based algorithmsfor SA.Thegoal of our project was to make the most efficient use of the SentiWordNet vocabulary to develop a Twitter Sentiment Analysis platform. Using the SentiWordNet lexicon, we obtained an accuracy of 75.20 percent for our dataset, althoughweobservedthatthisnumbervariedsignificantly fromoneareatothenext.Becausethecurrentlexiconhasa hugenumberoftermswiththeiremotionscore,itislacking specific words that are common in a certain domain, it is preferable toconstructa lexiconfromthetestcorpusand use it for classification. Our model, which uses the Google searchenginetodetermineaterm'sscoreutilizingpointwise mutualinformation,outperformstheSentiWordNetlexicon on our dataset and can deal with one of the difficulties of SentimentAnalysis theunexpectedshiftfrompositiveto negativesentiments.
REFERENCES
[1]C.Alm,D.Roth,andR.Sproat,“Emotionsfromthetext: machine learning for text-based emotion prediction,” in ProceedingsofHLTandEMNLP.ACL,2005,pp.579–586.
[2]S.AmanandS.Szpakowicz,“UsingRoget’sthesaurusfor fine-grainedemotionrecognition,”inProceedingsofIJCNLP, 2008,pp.296
302.
[3] P. Chesley, B. Vincent, L. Xu, and R. K. Srihari, “Using verbs and adjectives to automatically classify blog sentiment,” in AAAI Spring Symposium: Computational ApproachestoAnalyzingWeblogs,2006,pp.27–29.
[4] M. D. Choudhury, S. Counts, and M. Gamon, “Not all moodsarecreatedequal!exploringhumanemotionalstates insocialmedia,”inProceedingsofICWSM,2012.
[5]R.Fan,K.Chang,C.Hsieh,X.Wang,andC.Lin,“Liblinear: A library for large linear classification,” The Journal of MachineLearningResearch,vol.9,pp.1871–1874,2008.
[6]K.Gimpel,N.Schneider,B.O’Connor,D.Das,D.Mills,J. Eisenstein, M.Heilman, D. Yogatama,J.Flanigan,and N. A. Smith, “Part-of-speech tagging for Twitter: annotation, features, and experiments,” in Proceedings of HLT: short papers,ser.HLT’11.Stroudsburg,PA,USA:ACL,2011,pp. 42–47.
[7]M.Hall,E.Frank,G.Holmes,B.Pfahringer,P.Reutemann, andI.Witten,“Thewekadataminingsoftware:anupdate,” ACMSIGKDDExplorationsNewsletter,vol.11,no.1,pp.10–18,2009.
[8]G.Mishne,“Experimentswithmoodclassificationinblog posts,” in Proceedings of ACM SIGIR 2005 Workshop on StylisticAnalysisofTextforInformationAccess.
[9]S.Mohammad,“#emotionaltweets,”inProceedingsofthe SixthInternationalWorkshoponSemanticEvaluation.ACL, 7-8June2012,pp.246–255.
[10] A. Neviarouskaya, H. Prendinger, and M. Ishizuka, “Affectanalysismodel:Anovelrule-basedapproachtoaffect sensingfromtext,”Natural LanguageEngineering,vol. 17, no.1,pp.95–135,2011.
[11] B. Pang, L. Lee, and S. Vaithyanathan, “Thumbs up?: sentimentclassificationusingmachinelearningtechniques,” inProceedingsofEMNLP.ACL,2002,pp.79–86.
[12] P. Shaver, J. Schwartz, D. Kirson, and C. O’Connor, “Emotion knowledge: Further exploration of a prototype approach.”Journalofpersonalityandsocialpsychology,vol. 52,no.6,pp.1061
1086,1987.
[13] C. Strapparava and R. Mihalcea, “Learning to identify emotions in text,” in Proceedings of the 2008 ACM
symposium on Applied computing. ACM, 2008, pp. 1556–1560.
[14] C. Strapparava and A. Valitutti, “Wordnet-affect: an affectiveextensionofwordnet,”inProceedingsofLREC,vol. 4.Citeseer,2004,pp.1083
1086.
[15]C.StrapparavaandR.Mihalcea,“Semeval-2007task14: affective text,” in Proceedings of the 4th International WorkshoponSemanticEvaluations,ser.SemEval’07,2007, pp.70–74.
[16] R. Tokuhisa, K. Inui, and Y. Matsumoto, “Emotion classification using massive examples extracted from the web,”inProceedingsofCOLING.ACL,2008,pp.881–888.
[17] T. Wilson, J. Wiebe, and P. Hoffmann, “Recognizing contextual polarity in phrase-level sentiment analysis,” in ProceedingsofHLTandEMNLP.ACL,2005,pp.347–354.
[18]I.Witten,E.Frank,andM.Hall,DataMining:Practical machinelearningtoolsandtechniques.MorganKaufmann, 2011.
[19] C. Yang, K. Lin, and H. Chen, “Emotion classification using web blog corpora,” in IEEE/WIC/ACM International ConferenceonWebIntelligence.IEEE,2007,pp.275
278.