
Three Feature Based Ensemble Deep Learning Model for Pulmonary Disease Classification
1Student, Dept of Computer Engineering, Pimpri Chinchwad College of Engineering, Pune, Maharashtra, India
2Student, Dept of Computer Engineering, Pimpri Chinchwad College of Engineering, Pune, Maharashtra, India
3Student, Dept of Computer Engineering, Pimpri Chinchwad College of Engineering, Pune, Maharashtra, India
4Student, Dept of Computer Engineering, Pimpri Chinchwad College of Engineering, Pune, Maharashtra, India
5Professor, Dept of Computer Engineering, Pimpri Chinchwad College of Engineering, Pune, Maharashtra, India
Abstract – In recent years there has been a rise in the number of patients suffering from acute and chronic pulmonary diseases because of varying reasons like pollution, lung damage, or infections. The following research is regarding a Neural Network basedsolutionfortherecognition of the abnormality and possible disease based on lung auscultation. The following paper depictsthatRNN-LSTMand CNN were the best-performing techniques. Although a higher percentage of noise while capturing the auscultation audio and limited data leads to a saturation point for the models to improve. The dataset had over 5000 breathing cycles for COPD, whereas only about 100 breathing cycles for LRTI and URTI. This unbalanced data made it difficult for the models to perform well on test audio clips because of the biasintroduced by the large count of COPD samples. We adopted afilter-based audio augmentation to rebalance the dataset. To get themost out of the data we had, we utilized multiple features like MFCC, Chromagram, and Spectrogram extracted from the same audio clip. Since these extracted features are not fathomable tohumans,weusedconvolutionalneuralnetworks to perform primary feature extraction. Likewise, dedicated CNN models acted as feature extractors whereas the dense neural network served as the actual classifier. We developed multiple versions of the models with fine-tuned parameters. The ML models based on a single feature were considered the benchmark for evaluating more complex, multi-feature DL models.
Key Words: Pulmonary Diseases, CNN, MFCC, Chromagram, Spectrogram.
1. INTRODUCTION
Ahugenumberofdeathsarecausedeverysingleyeardueto various pulmonary diseases such as asthma, bronchitis, pneumonia,etc.Asperresearch,COPDisoneoftheleading ones causing the death of approximately 3.23 million. Affected people suffering from such pulmonary disorders have different breathing sounds as compared to healthy people.Thisincludesrhonchus,crackles,wheezes,stridor, and plural friction rubs which are present in breathing sounds.Inordertodistinguishbetweenhealthyandinfected breathing sound various parameter checks are used. For
example, frequency, pitch, energy, etc. For in-depth diagnosis,doctorstakethehelpofseveralmedicaltestslike lung (pulmonary) function tests, lung volume tests, Pulse Oximetry,Spirometry,chestx-ray,CTscan,arterialbloodgas analysis,etcwhicharetime-consumingandcostly.Inorder to reduce this process a lot of researchers have proposed variousmethodsusingcomputersciencetechnologieslike MLandDLclassificationalgorithmswhichhelpusmakean earlydiagnosis.
A lot of the research is based on the findings in speech analysis.Forinstance,thefeatureMFCCisheavilyusedfor speechandsoundrecognition.Theresearchin[34]and[26] isusingMFCCforspeakerrecognition.While[33],[31],and [27]usesimilartechniquesforbirdsoundandenvironment soundclassification.MFCC,Spectrogram,andChromagram are2Dfeaturesoraudiorepresentations. Thereisresearch basedontheusageoftraditionalMLmodels[2].Herethe2D imageistobeconvertedtoaflat1Dfeaturevectorasinput to the models like KNN, SVM, Decision Tree, etc. Other researchersusedDLalgorithmslikeCNNandRNN[9],[10], and[11].Whilefewhaveproposedthatacombinationoftwo or more such algorithms has shown better results. For example, RNN with LSTM, CNN BiLSTM,[17] and [18]. A survey for comparison of various these techniques can be foundin[1].Inthefollowingpaper,weproposeamethod where wedeveloped a Tri-feature based 2 step classifiers basedonConvolutionalNeuralNetworkandDenseNeural Network
2. DATASET
Aconsiderableamountoftheexistingresearchisbasedon theICBHI2017[14]dataset.Themajorfocusofresearchers has been on the adventitious sound classification. Less attentionisgiventodiseaseclassification.Whilethereareno controversiesregardingtheauthenticityandcorrectnessof theICBHIdataset,onefundamentalnotethatneededtobe considered was the disease classes recognized by the medicalcommunity.
The ICBHI dataset consists of 8 classes namely, Asthma, Pneumonia, Healthy, COPD, URTI, LRTI, Bronchiectasis,

Bronchiolitis.Inreality,COPD,URTIandLRTIaresuperset for other pulmonary diseases. COPD consists of Asthma, Pneumonia, Bronchitis, while LRTI consists of chronic Bronchitis, Bronchiolitis, Bronchiectasis and acute exacerbations of COPD. Hence a sample can be classified underPneumonia,COPD,andLRTIatthesametimeandit shouldbeconsideredcorrectclassificationbylogic.Butthis willnotonlyreducetheaccuracyofthemodelstatistically, anditisoflessuseinrealdiagnosis.
A solution to this issue is, making separate classifiers for absolute disorder classes and the umbrella (Superset) classes.Useofsucha classificationisthat,whenthesame sampleistestedonamodeltrainedontheSupersetclasses, itwilltellusabouttheseverityofthedisorder.Ex:asample classifiedaspneumoniainthedisorderclassifierandLRTIin theumbrellaclassifierwilltellusthatthepatientissuffering fromacutePneumonia,whileasampleclassifiedasCOPDin umbrella classifier will tell us that the patient is suffering fromchronicPneumonia.Thissegregationhelpsusingiving the severity of the disorder without use of other medical tests.URTIsconsistofthroatrelatedinfectionswhicharenot clinicallyproventobealeadingcauseofadventitioussounds in the lung auscultation, and URTI sounds have more correlationwiththeHealthysounds.Hence,wecanexclude theURTIclassfromconsideration.
Thisclasslabelingrequiresexpertknowledgeandpatience. This approach can be used when a suitable dataset is available,wearefocusingoncreatingtheabsolutedisease classifier.Forthispurpose,weareusingsamplesbelongingto the classes: Asthma, Pneumonia, Bronchiectasis, Bronchiolitis,HealthyandLungFibrosis.Thesamplesused forLungFibrosisbelongtotheMendeleyDataset[13].
3. DATASET AUGMENTATION
Theskewednatureofthedataset,madeitessentialforusto rebalance it. Traditionally audio augmentation means artificially creating more audio data samples from the existingones.Thiswasachievedinvariouswaysaslistedin next subsection. Although these methods could work for otheraudioclassificationusecases.Thesetechniqueswould distortourdatatosuchanextentthatthetrainedmodelwill notbegeneralizedoverreal-lifedata.
3.1 Limitations of Traditional Audio Augmentation
Following is a list of traditional audio augmentation techniqueswidelyused,buttheyarenotsuitableonourdata setforvariousreasons.
3.1.1 Time Shift:
Therespiratorycyclesareextractedfromtheaudiofiles.A normal respiratory cycle lasts for 2-4 seconds. It was observed that it may span up to 6 seconds in some cases hence a 6 seconds duration was selected for the samples.
Smallersampleswerecenterpaddedby0togettherequired duration.Becauseofthecenterpadding,thetimeshiftwill onlycausethedata to move towardsleft or rightand add morezerostooneoftheends.Thiswillnotbeeffectivein reallifescenarioswherethesamplesfedtothesystemwill alwaysbecenterpadded.
3.1.2 Pitch shift
Crackles,Wheezes,Rhonchi,Stridor,etcadventitioussounds have a certain pitch and the model will learn this information.Employingpitchshiftwillleadtohamperingof theoriginaldataandthemodelwillnotgeneralizeforreal lifescenarios.
3.1.3 Changing speed
Therespiratorysoundscannotbemadefasterasastandard respiratory cycle should last 2-4 seconds minimum. Speeding down will cause stretching of the data and any ambientnoisemaysoundsimilartoawheezebecauseofthe timestretch.
3.1.4 Noise injection
The audio samples are already noisy hence using various methodstoreducethenoiseinthesampleneedstobeused. Addingmorenoisetothesamplemakesnosenseasafterthe filteringprocessthesamplewillberestoredtotheoriginal audioandcauseredundancyinthedataset.
3.1.5 Spectrogram masking
Spectrogramsarebasicallyvisualizationsoftheaudiodata. Spectrogram masking suggests that we mask a certain portion of the spectrogram along the time axis, frequency axisorbothrandomly.Thiswillnotbeveryhelpfulasinreal lifescenarios,theaudiosampleswillretainallthefeatures. This will lead to overfitting the model with partially redundantinformation.Whichwillleadtohighervalidation lossandpoorgeneralization.
3.1.6 Generation of Permutations
Somestudiessuggestedcreatingnewsamples bycreating permutations of the sequence of respiratory cycles. This causedthemodeltooverfitbypoorgeneralization.
3.2 Filter Based Audio Augmentation
Since traditional audio augmentation methods cannot be employed to our dataset for various reasons, we came up withasolutionofapplyingfilterstogeneratesampleswith slightvariations.Thissolves3majorissues.
1. LessRedundancy:
We are using filters which will modify the data uniformly and generate spectrograms with nuanced differences. But
the filter process will not lead to loss of information in random regions of the spectrograms contrasting to the Spectrogram masking technique. Hence reducing the redundancywithminimumlossofdata.
2. Noadditionalnoise:
Sinceafilterreducesnoiseinthesignal,ithelpsustrainthe modelstoperformwellonbothcleansignalaswellaswith ambientnoisesimilartoreallifescenarioshenceimproving generalization.
3. NomissclassificationbecauseofPitchshift:
The filters will only remove unwanted frequencies and abnormalities, this will not affect the crackles or healthy sounds to miss classify as high-pitched wheezes and viceversa
Filtersusedforaugmentationare
1.ButterworthBandpassfilter
2.Harmonic-Percussivesourceseparator
3. 3-layerfilterPipeline
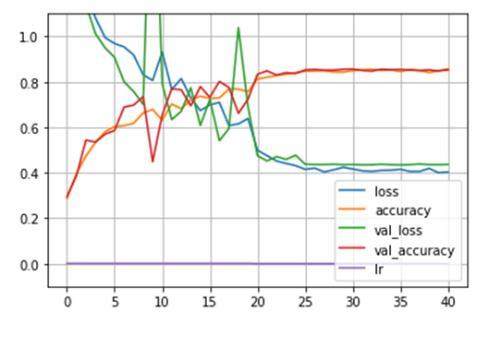
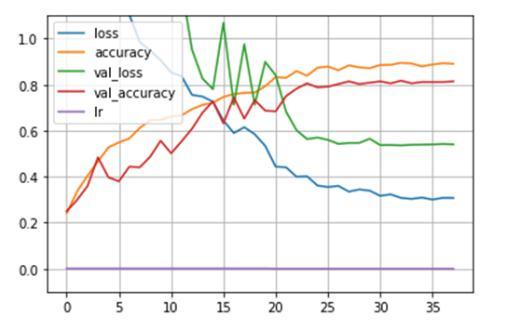
Followingarethegeneralizationresultsforthepreliminary iterations of the proposed models. We used the dataset directlywithoutaugmentationonapreliminaryversionof ourMLmodel.Theresultsshowedahighdifferenceinthe validationaccuracyandthe trainingaccuracy,same isthe casewiththevalidationlossandthetrainingloss.Thiscan beobservedinFig-1.Thishugedifferenceinthevalidation andtrainingaccuracyisreminiscentofpoorgeneralization meaninghighvariance.
UponperformingtheFilterBasedAudioAugmentation,the resultswereclearlystatingthatthevariancehasreducedto agreatextentinFig-2.Thisreducedvariancesignifiesthat themodelhasgeneralizedwell.
4. SOLUTION
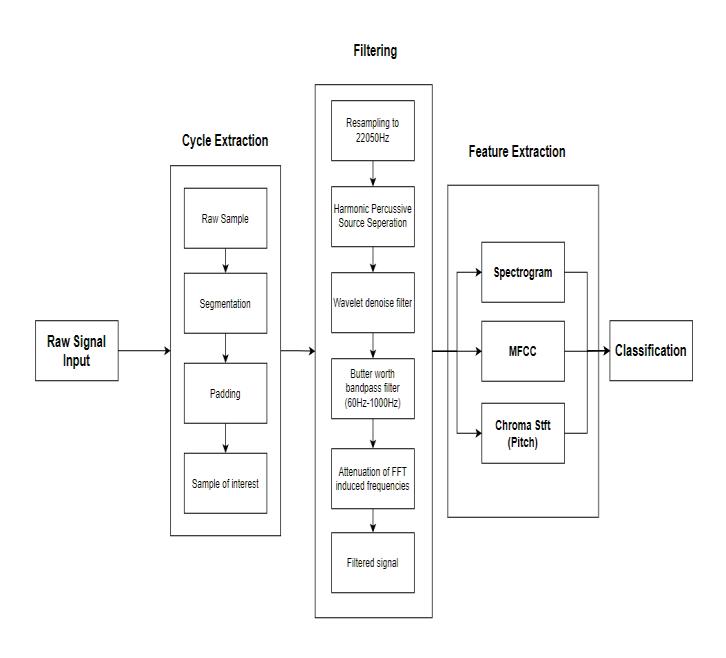
Themaincontributionofourworkisimplementationof an ensemble CNN model. The raw input sample i.e., the lung auscultation sounds from the dataset is split into trainingdatasetandvalidationdataset.Thesesamplesare standardized by resampling, clipping and padding then passed through a Filter bank and the filtered output is passed on to the level one feature extractor which generates 2D images from the audio. These images are then passed to the level 2 feature extractor which is a fine-tuned CNN model For feature extraction, the best suitedmethodsforourdataset,hasbeenidentifiedtobe Spectrogram,MFCC,andChromaSTFT.
4.1 Data Preprocessing
The process of preprocessing and feature extraction is divided into 3 parts i.e Cycle Extraction, Filtering and Feature Extraction. We standardized the audio clips coming from different sources by resampling them to 22050Hz.therawsamplethenundergoessegmentation to capture a single breathing cycle per clip and zero paddingtomakeeachclip 6secondslong. Ifoursample consists of noise, it will lead us to inaccurate results. The audioispassedthroughtheHarmonic-PercussiveSource Separation Filter to reduce the ambient noise, Wavelet denoise filter, Butterworth band pass filter [60Hz to 1000Hz]toremoveunwantedfrequencieswhichmaybe caused by the heart beats. The Butterworth bandpass signalinducesverysmallnoiseintheformofvaluesclose tozeroforthezeropaddedsegmentoftheaudioclip.This istheresultofthe FFTalgorithmonZero values,hence thisnoiseisattenuated.Afterthesestepsoffilteringthe audiosamplesarereadyforclassification.
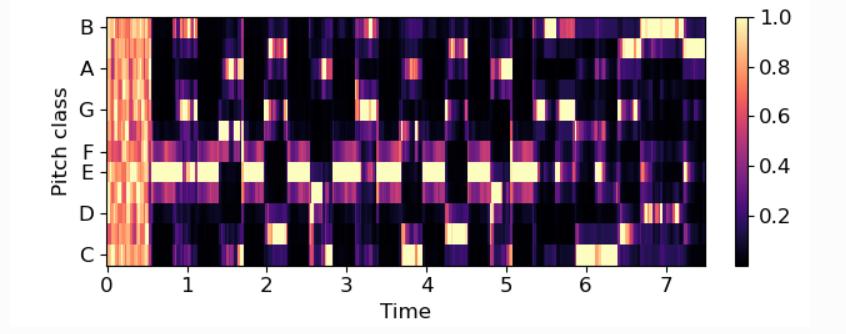
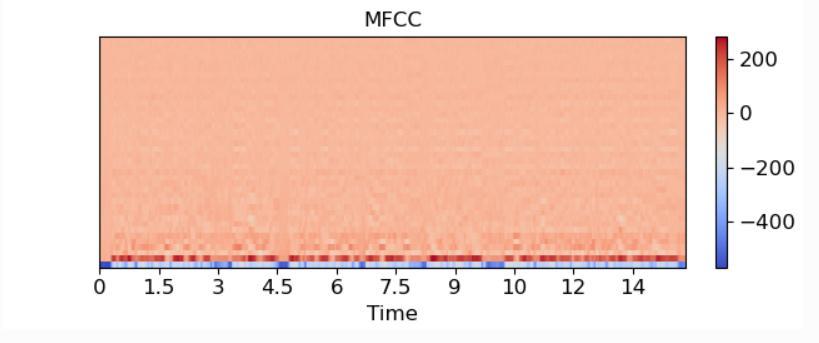
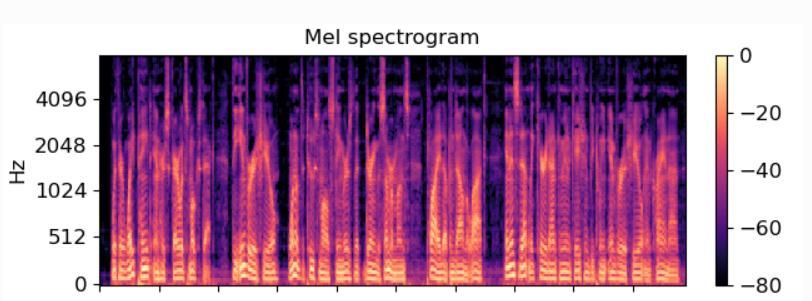
We selected Spectrogram, MFCC and Chromagram as the features.Eachonehasasignificantuseintheclassification process. Spectrogram is a visual representation of the loudness of the audio at particular frame [32]. This is the simplest way to represent audio. Chromagram is visualizationofthepitchclassoftheaudioframe[22].Pitch allows us to classify among wheezes and crackles. MFCC representsoundtothemachineinsamewayasthehuman perceive the audio, which means higher sensitivity to low frequency sound and less sensitivity to higher frequency sound[28].Henchinanutshell,MFCCcanbeinterpretedas akindofspectrogramthatrepresentsoundsonnonlinear (logarithmic)scaleknowsasMel-Scale.
Thedatasetconsistedofaudioclipsrangingfrom10seconds to 30 seconds. We extracted Spectrogram, MFCC and Chromagram from once such audio clip which was 14 seconds long which can be seen in Fig-1, Fig-2 and Fig-3 respectively.
4.3 Classification
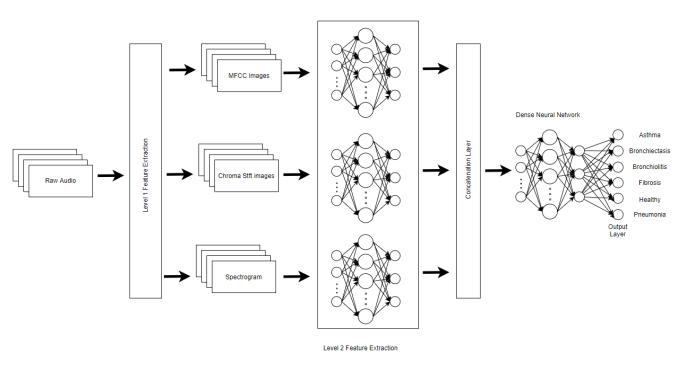
Theproposedsystemuses3featurestoperformtheanalysis. This architecture allows us to gather information from different audio domains and incorporate them into one aggregatedoutput.TheLevel1featureextractionisusedto extractthefeatureimages(visualization)fromtherawaudio. TheseimagesarepassedontotheLevel2featureextractors which are tailored CNN models which learn the essential features from the images. These models are concatenated togetherandpassedonasinputtoaMulti-LayerPerceptron whichgivesfinaloutput.
Preliminarymodelssufferedfromoverfittingissue.Thetrain accuracy reached up to 99% while validation accuracy couldn’t go past 85%. This issue was resolved using callbackslikeEarlyStoppingwithbestweightandLearning Ratereduction.
5. Model Evaluation
For model evaluation, we trained multiple versions for a singlekindofmodelandwithslight variationstotunethe model. We gathered compared the data of the best performing models. We segregated the results in three categories,namelyMFCCbasedMLmodels,MFCCbasedDL modelsandlastlyMultiFeaturebasedDLmodels.
MFCCbasedMLmodelsconsistoftraditionalMLmodelslike DecisionTree,KNN,SVMandRandomForest.Themodels were trained on flattened MFCC (1-Dimensional) vector Thesemodelsarebasedonasinglefeature.FromTable-1it wasobservedthatRandomForestalgorithmwasgivingbest result among others of the same category. This pointed towardsthepossibilityofachievingabetteraccuracywith anensemblemodelinfurtherresearch.
Table -1: MFCCbasedMLModelComparison
MFCC based ML Model Comparison Table
MFCCbasedDLmodelsconsistofSingleLayerPerceptron, Multi-Layer Perceptron, Convolutional Neural Networks, RecurrentNeuralNetworksandLong-ShortTermMemory models.SomeoftheModelswereusedinacombinationlike RNN-LSTM and CNN+RNN-LSTM. From Table-2 it is observedthatRNN-LSTMmodelsareperformingwellalong with the models containing CNNs. This pointed us in the directionthatusingacombinationofmultiplemodelsina kind of sequential pipeline is likely to give better results. BecauseV4ofCNN+RNN-LSTMmodelgavebetteraccuracy ascomparedtopurelyCNNandRNN-LSTMmodels.
Table -2: MFCCbasedDLModelComparison
MFCC based DL Model Comparison Table
MultiFeaturebasedDLModelsconsistedofDeeplearning modelswhichareusedinaparticularcombination,suchthat the input is taken from multiple features. These features were MFCC, Spectrogram and Chromagram as discussed earlier.ThistimewedevelopedmodelsthatusedCNNsina sequence with different combination of Features. From Table-3weobservedthatwhenthethreefeatureswereused together,theirvalidationaccuracywas92.76%andthatof onlyMFCCandChromagramwasapproximately91.94%.
6. CONCLUSION
We used cycle extraction and filtering methods on our datasettogetbetteraudioqualitywhichwillgivebetter accuracy for our model. This dataset was then used to trainedvarioustraditionalMLmodelslikeSVM,KNN,etc. which gave accuracy of more than 70% with random forestreachingupto85%.OncontraryDLbasedmodels gaveevenbetterresultswithaccuracyofmorethan85%. FewofthesemodelswereSingleLayerperceptron,CNN, RNN, etc. Here RNN LSTM with CNN 1-D convolutional modelgaveusaccuracyof88%.Finally,wedevelopedour modelwhichiscombinationofMFCC,ChromaSTFTand spectrogramasfeatureextractiontechniquewithCNNas classification model which gave us best results of the highestaccuracyreachingupto92%.Thiscanbeinferred as, when multiple features of pulmonary audio with an ensembleCNNmodelareused,theresultsaremuchbetteras comparedtotheresultsofanapproachwithasingleaudio featurewithasingleML/DLmodel.Whichisinagreement withtheworksofD.Pernain[16]and[17].
Further, we plan to develop a diagnosis support system that allows the medical practitioner to perform lung auscultationandseetheresultsinrealtime.Theaccuracy ofthemodelswillbeincreasedasmoredataiscollected overtimewiththeexpertfeedback.Moreadvancementsin the field are possible when the digital stethoscopes become less expensive making it easier for more practitionerstoadoptit
REFERENCES
[1] A.Dawadikar,A.Srivastava,N.Shelar,G.GaikwadandA. Pawar, "Survey of Techniques for Pulmonary Disease Classification using Deep Learning," 2022 IEEE 7th InternationalconferenceforConvergenceinTechnology (I2CT), Mumbai, India, 2022, pp. 1-5, doi: 10.1109/I2CT54291.2022.9824879.
[2] Haider,N.S.,Singh,B.K.,Periyasamy,R etal. Respiratory Sound Based Classification of Chronic Obstructive Pulmonary Disease: a Risk Stratification Approach in MachineLearningParadigm. J Med Syst 43, 255(2019).
[3] G.Altan,Y.KutluandN.Allahverdi,"DeepLearningon Computerized Analysis of Chronic Obstructive PulmonaryDisease,"inIEEEJournalofBiomedicaland HealthInformatics,vol.24, no.5,pp.1344-1350, May 2020,doi:10.1109/JBHI.2019.2931395.
[4] F.Demir,A.M.IsmaelandA.Sengur,"Classificationof Lung Sounds With CNN Model Using Parallel Pooling Structure,"inIEEEAccess,vol.8,pp.105376-105383, 2020,doi:10.1109/ACCESS.2020.3000111.
[5] S.Z.H.Naqvi,M.A.Choudhry,A.Z.KhanandM.Shakeel, "Intelligent System for Classification of Pulmonary Diseases from Lung Sound," 2019 13th International Conference on Mathematics, Actuarial Science, ComputerScienceandStatistics(MACS),2019,pp.1-6, doi:10.1109/MACS48846.2019.9024831.
[6] G. Chambres, P. Hanna and M. Desainte-Catherine, "Automatic Detection of Patient with Respiratory Diseases Using Lung Sound Analysis," 2018 InternationalConferenceonContent-BasedMultimedia Indexing (CBMI), 2018, pp. 1-6, doi: 10.1109/CBMI.2018.8516489.
[7] Naqvi,S.Z.H.;Choudhry,M.A.AnAutomatedSystemfor ClassificationofChronicObstructivePulmonaryDisease and Pneumonia Patients Using Lung Sound Analysis. Sensors 2020, 20, 6512.https://doi.org/10.3390/s20226512
[8] S.Z.Y.Zaidi,M.U.Akram,A.JameelandN.S.Alghamdi, "Lung Segmentation-Based Pulmonary Disease Classification Using Deep Neural Networks," in IEEE Access, vol. 9, pp. 125202-125214, 2021, doi: 10.1109/ACCESS.2021.3110904.
[9] M. Anthimopoulos, S. Christodoulidis, L. Ebner, A. ChristeandS.Mougiakakou,"LungPatternClassification for Interstitial Lung Diseases Using a Deep ConvolutionalNeuralNetwork,"inIEEETransactionson Medical Imaging, vol. 35, no. 5, pp. 1207-1216, May 2016,doi:10.1109/TMI.2016.2535865.
[10] S.B.Shuvo,S.N.Ali,S.I.Swapnil,T.HasanandM.I.H. Bhuiyan, "A Lightweight CNN Model for Detecting Respiratory Diseases From Lung Auscultation Sounds Using EMD-CWT-Based Hybrid Scalogram," in IEEE JournalofBiomedicalandHealthInformatics,vol.25,no. 7, pp. 2595-2603, July 2021, doi: 10.1109/JBHI.2020.3048006.
[11] S. Kido, Y. Hirano and N. Hashimoto, "Detection and classification of lung abnormalities by use of convolutionalneuralnetwork(CNN)andregionswith CNNfeatures(R-CNN),"2018InternationalWorkshop onAdvancedImageTechnology(IWAIT),2018,pp.1-4, doi:10.1109/IWAIT.2018.8369798.
[12] L. Pham, H. Phan, R. Palaniappan, A. Mertins and I. McLoughlin, "CNN-MoE Based Framework for Classification of Respiratory Anomalies and Lung Disease Detection," in IEEE Journal of Biomedical and HealthInformatics,vol.25,no.8,pp.2938-2947,Aug. 2021,doi:10.1109/JBHI.2021.3064237.
[13] Z. Tariq, S. K. Shah and Y. Lee, "Lung Disease Classification using Deep Convolutional Neural Network," 2019 IEEE International Conference on BioinformaticsandBiomedicine(BIBM),2019,pp.732735,doi:10.1109/BIBM47256.2019.8983071
[14] Fraiwan, Mohammad; Fraiwan, Luay; Khassawneh, Basheer; Ibnian, Ali(2021), “Adataset of lungsounds recorded from the chest wall using an electronic stethoscope”, Mendeley Data, V3, doi: 10.17632/jwyy9np4gv.3
[15] RochaBMetal.(2019)"Anopenaccessdatabaseforthe evaluation of respiratory sound classification algorithms"PhysiologicalMeasurement40035001
[16] Rocha, Bruno & Filos, D. & Mendes, L. & Vogiatzis, Ioannis&Perantoni,Eleni&Kaimakamis,Evangelos& Natsiavas,Pantelis&Oliveira,Ana&Jácome,Cristina& Marques,Alda&Paiva,RuiPedro&Chouvarda,Ioanna &Carvalho,P.&Maglaveras,N..(2017).ΑRespiratory Sound Database for the Development of Automated Classification.33-37.10.1007/978-981-10-7419-6_6.
[17] D. Perna, "Convolutional Neural Networks Learning from Respiratory data," 2018 IEEE International ConferenceonBioinformaticsandBiomedicine(BIBM), 2018, pp. 2109-2113, doi: 10.1109/BIBM.2018.8621273.
[18] D.PernaandA.Tagarelli,"DeepAuscultation:Predicting Respiratory Anomalies and Diseases via Recurrent Neural Networks," 2019 IEEE 32nd International Symposium on Computer-Based Medical Systems (CBMS), 2019, pp. 50-55, doi: 10.1109/CBMS.2019.00020.
[19] L.Cai,T.Long,Y.DaiandY.Huang,"MaskR-CNN-Based DetectionandSegmentationforPulmonaryNodule3D Visualization Diagnosis," in IEEE Access, vol. 8, pp. 44400-44409, 2020, doi: 10.1109/ACCESS.2020.2976432.
[20] Porieva,H.S.,Ivanko,K.O.,Semkiv,C.I.andVaityshyn, V.I.(2021)“InvestigationofLungSoundsFeaturesfor Detection of Bronchitis and COPD Using Machine Learning Methods”, Visnyk NTUU KPI SeriiaRadiotekhnika Radioaparatobuduvannia,(84), pp. 7887.doi:10.20535/RADAP.2021.84.78-87
[21] M.A.Islam,I.Bandyopadhyaya,P.BhattacharyyaandG. Saha, "Classification of Normal, Asthma and COPD SubjectsUsingMultichannelLungSoundSignals,"2018 InternationalConferenceonCommunicationandSignal Processing (ICCSP), 2018, pp. 0290-0294, doi: 10.1109/ICCSP.2018.8524439.
[22] X. Yu, J. Zhang, J. Liu, W. Wan and W. Yang, "An audio retrieval method based on chromagram and distance metrics," 2010 International Conference on Audio, LanguageandImageProcessing,Shanghai,China,2010, pp.425-428,doi:10.1109/ICALIP.2010.5684543.
[23] S.Yuanetal.,"ImprovedSingingVoiceSeparationwith Chromagram-Based Pitch-Aware Remixing," ICASSP 2022-2022IEEEInternationalConferenceonAcoustics, Speech and Signal Processing (ICASSP), Singapore, Singapore, 2022, pp. 111-115, doi: 10.1109/ICASSP43922.2022.9747612.
[24] R. Hidayat, A. Bejo, S. Sumaryono and A. Winursito, "DenoisingSpeechforMFCC FeatureExtractionUsing WaveletTransformationinSpeechRecognitionSystem," 2018 10th International Conference on Information Technology and Electrical Engineering (ICITEE), Bali, Indonesia, 2018, pp. 280-284, doi: 10.1109/ICITEED.2018.8534807.
[25] A.Winursito,R.HidayatandA.Bejo,"Improvementof MFCC feature extraction accuracy using PCA in Indonesian speech recognition," 2018 International Conference on Information and Communications Technology(ICOIACT),Yogyakarta,Indonesia,2018,pp. 379-383,doi:10.1109/ICOIACT.2018.8350748.
[26] P.Bansal,S.A.ImamandR.Bharti,"Speakerrecognition usingMFCC,shiftedMFCCwithvectorquantizationand fuzzy," 2015 International Conference on Soft ComputingTechniquesandImplementations(ICSCTI), Faridabad, India, 2015, pp. 41-44, doi: 10.1109/ICSCTI.2015.7489535.
[27] X.Shan-shan,X.Hai-feng,L.Jiang,Z.YanandL.Dan-jv, "ResearchonBirdSongsRecognitionBasedonMFCCHMM," 2021 International Conference on Computer,
ControlandRobotics(ICCCR),Shanghai,China,2021,pp. 262-266,doi:10.1109/ICCCR49711.2021.9349284.
[28] M. A. Hossan, S. Memon and M. A. Gregory, "A novel approach for MFCC feature extraction," 2010 4th International Conference on Signal Processing and Communication Systems, Gold Coast, QLD, Australia, 2010,pp.1-5,doi:10.1109/ICSPCS.2010.5709752.
[29] A. Winursito, R. Hidayat, A. Bejo and M. N. Y. Utomo, "FeatureDataReductionofMFCCUsingPCAandSVDin Speech Recognition System," 2018 International Conference on Smart Computing and Electronic Enterprise(ICSCEE),ShahAlam,Malaysia,2018,pp.1-6, doi:10.1109/ICSCEE.2018.8538414.
[30] P.MaheshaandD.S.Vinod,"LP-Hillberttransformbased MFCC for effective discrimination of stuttering dysfluencies," 2017 International Conference on Wireless Communications, Signal Processing and Networking(WiSPNET),Chennai,India,2017,pp.25612565,doi:10.1109/WiSPNET.2017.8300225.
[31] Z. Chi, Y. Li and C. Chen, "Deep Convolutional Neural NetworkCombinedwithConcatenatedSpectrogramfor Environmental Sound Classification," 2019 IEEE 7th International Conference on Computer Science and NetworkTechnology(ICCSNT),Dalian,China,2019,pp. 251-254,doi:10.1109/ICCSNT47585.2019.8962462.
[32] R.Decorsière,P.L.Søndergaard,E.N.MacDonaldandT. Dau,"InversionofAuditorySpectrograms,Traditional Spectrograms,andOtherEnvelopeRepresentations,"in IEEE/ACMTransactionsonAudio,Speech,andLanguage Processing, vol. 23, no. 1, pp. 46-56, Jan. 2015, doi: 10.1109/TASLP.2014.2367821.
[33] M. S. Towhid and M. M. Rahman, "Spectrogram segmentation for bird species classification based on temporal continuity," 2017 20th International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 2017, pp. 1-4, doi: 10.1109/ICCITECHN.2017.8281775.
[34] J.-G.Leu,L.-t.Geeng,C.E.PuandJ.-B.Shiau,"Speaker verification based on comparing normalized spectrograms,"2011CarnahanConferenceonSecurity Technology, Barcelona, Spain, 2011, pp. 1-5, doi: 10.1109/CCST.2011.6095878.