
A GUI BASED GRADING APPROACH FOR QUORA QUERIES AND MESSAGES USING MACHINE LEARNING TECHNIQUES
Dr. M Srinivasa Sesha Sai1, Gopi Bapanapalli2, Vineeth Marri3, Lokesh Vadlamudi41Professor,Department of Information Technology, KKR & KSR Institute of Technology and Sciences, Guntur, India. 2,3,4Undergraduate Students, Department of Information Technology, KKR & KSR Institute of Technology and Sciences, Guntur, India.

***
Abstract - Humans are powerful and smart enough to invent new technologies such as blockchain, cloud computing, web applications like Quora, Stack Overflow and more. Today, people are expected to take advantage of the internet to send messages and ask unknown questions on Quora. Therefore, our team focused on classifying whether a given message is a useful message or useless message and reviews the questions asked on the Quora to ensure that they are genuine and decided that it was a dishonest question. The existing system has poor accuracy in the grading of questions and messages. The proposed system eliminates the shortcomings and improves accuracy by up to 99.87%. The proposed system uses different kinds of machine learning techniques, such as Naive Bayes, Logistic Regression, Support Vector Machine algorithms.
Key Words: Naïve Bayes, Support Vector Machine, spam, Insincere questions, Regression, Flask, Python, web application,Server,ham,Sincere.
1.INTRODUCTION
Withso many newtechnologies emerging today,it ismost widely used to send messages on Android apps such as WhatsApp,Telegram,Instagram,Twitter,andtheMessages app on mobile phones. Today, using the Internet, we can send any number of messages from one place to another, so weneedtoknowifthemessagefromtheother sideisa useful message. With technology, spammers are ready to steal data, money and useful his information by sending spam his messages to his mobile application apps like messagesandemails.Therefore,itisimportanttoevaluate the message in order to save the data. Another important thing is to classify the questions asked on the Quora website as honest or dishonest. Because people are so smart you can ask any kind of question about it. or false. Therearesomanysolutionsforthis,forexample,[1]Abeer Alsadoon propose a solution using a Gain and mining algorithm that gives 100% accuracy but the problem with that implementation is the time taken for classifying the email whether it is spam or not and he is not implementing the Quora query classification using same algorithms but in our proposed using regression algorithms we can classify the SMS messages and Quora queries whether they are useful or not. Let us dive into
another solution for this problem which was proposed by the [3] Aakash Atul Alurkar, the author wants to classify only email messages as spam or not spam but what about userinteractionmodebecausecustomersatisfactionisthe majorpriorityofus,weneedtosatisfythecustomersofor consumer purpose, our proposed system developed a GUI forinteractionwiththecomputersystembybuildingaweb application using trending technology like python frameworkflask.Ourproposedsystemusesdifferenttypes of machine learning technologies and deploys those algorithms into a fully pledged web application for providing a user interface. Infidelity is defined as words andactionsthatpeopledonotreallyfeel,havenomeaning to, or are not based on theirtrue feelings. Fraud is one of the most serious problems in Internet forums, especially Q&A forums. This is because it can affect the quality of Internet forums. Popular content (messages, posts, etc.) typicallydoesnotfollowforum rulesandcanannoyother users. A machine learning model was implemented to detect questions from users in Q&A forums. Therefore, our goal is to develop a GUI based web application for layering queries made in the Quora application and messagesreceivedintheapp.Next,wehavealsoafeature scopefor extending this proposed system to next level for security of consumer or customer or user by using trending technologies in the real world so that we make application which can satisfy the user. Today we have so many technologies been there for sending spam messages andsteal the user’sdata by usingthosespammessages so it is important to know the messages coming to us are spamornotandprotectourselffromthespammers.
[2] Muhana Magboul Ali Muslam, Mansoor RAZA and Nathali Dilshani Jayasinghe proposed system for classifying the mails as spam or ham using K- means Clustering machine learning algorithm, K-nearest Neighbour machine learning algorithm (KNN), Decision treeasresultOutofthetotalemails,morethan55percent isidentifiedasspam.But whenconsiderthetimetakento estimate or classify the message is spam or ham is very high and they can’t classify the Quora queries but out proposedsystemisableclassifybothmessagesandQuora querieswithlesstimeandgoodaccuracy.
[3] AakashAtulAlurkar,ShreeyaVijayJoshi,Siddhesh SanjayRanade,PiyushA.Sonewar,SourabhBharatRanade proposedasystemfordetectingthemessageishamornot sointhattheydidusingmachinelearningtechniquesthey concludethatWethenproposetoclassifyemailsintospam and ham using a machine learning approach. This allows the algorithm to detect desirable characteristics more accurately than manually setting desirable characteristics. conduct. The main idea is to classify the user's incoming mail based on various parameters commonly used by spammers. Its main purpose is to group important emails and block spam emails. With a variety of simple Internet domainsopenlyavailable,itisa wasteofeffortforsystem administrators to block potential spammers from predefinedlists.Thisdocumentalsoconsidersemailbodies containingcommonlyusedkeywordsandpunctuation.
[7] Hendri Priyambowo, Mirna Adriani proposed a system forstratificationofQuoraquestionsassincereorinsincere using Nearest Neighbor, Decision Tree, Random Forest. The purpose of this study is to compare machine learning algorithms and find out which algorithm and function can provide the best results in detecting dishonest question task. In this study, we also want to explore how feature selectiontechniquesaffectclassificationresultsonaverage, unigram features were basically the most important features used in classification tasks. Combine Unigram features with other features. It uses deep learning technology.
Additionally, some experiments, such as detecting dishonest questions, suffer from imbalanced data, so data resampling was one of the challenges in this experiment. Therefore, a comparison with other his data resampling algorithmscanbemadeforanotherre-search.
[6] Suresh Babu, C. V. Guru Rao, P. U. Anita proposed system for classifying the mails as spam mails and ham mails using Neighbor Probability based Naïve Bayes Algorithm. This system takes so much of time to classify the message as useful or useless and it can’t classify the Quora questions. But our proposed system can do both classificationsusingregressionalgorithms.
[5]DeRosalIgnatiusMosesSetiadi,ChristyAtikaSari,Eko Hari Rachmawanto, Niken Larasati Octaviani proposed a system for grading the email spams using Multinomial Naive Bayes Classifier, Support Vector Machine, and RecurrentNeuralNetwork.Theaccuracyobtainedbyusing the MNBC algorithm is 93%, while those using the SVM algorithmis96%,andusingtheRNNalgorithmis74%.The method and algorithm that has the highest or best accuracy results is the machinelearning method using the SupportVectorMachinealgorithmwithanaccuracyof0.96 or 96%. But this system also only classifies the mails but not Quora queries. Our proposed system can do both classifications.
[4] D. Karthika Renuka, V. Sri Vinitha proposed system of Performance Analysis of E-Mail Spam Classification using different Machine Learning Techniques. This system uses the following algorithms like K-Nearest Neighbor, Naive Bayes, Artificial Neural Network, Support Vector Machine, andRandomForestsalgorithm.
3. PROPOSED SYSTEM
Therearesomanytechnologiesinthisdynamicworld,and there are pros and cons to using them. Some drawbacks are sending deceptive her messages to users and using spam messages to steal user data. Another point is to ask dishonest questions on the Quora website. Users cannot identify messages sent by hackers or spammers, so our team focuses on that, identifying SMS spam messages and classifyingmessagespostedontheQuora webapplication. develop a system to error. The proposed system uses various types of his machine learning techniques, such as the machine learning-based test classification approach. The downside of the survival system is accuracy and time complexity. The proposed system has excellent accuracy andtimecomplexitycomparedwithexistingsystems.
3.1 STEPS INVOLVED IN PROPOSED SYSTEM
1.Gatheringthedatasetinformation
2.Preprocessing
3.Trainthemodel
4.Deploythemodelintowebpages
3.1.1 Gathering the data set information
The datasetis downloaded from the Kaggle. The data sets considered in this project are SMS Spam Collection and Quorainsinceredataset.Thedatasetshave1featureand1 target.Thetargetisbinarytypelikeeitherclass1orclass2. Allthetargetlabelsareequallydistributedforthetraining and testing data. 75% data is used for training, remaining fortesting.
3.1.2 preprocessing
Preprocessing is one of the most important steps for any kind of text model. Required preprocessing includes lowercase conversion, punctuation removal, stop word removal, and lemmatization/de-emphasis. Feature extraction applied to data. Convert the data into vector formsothatitcanbeunderstoodbymachines.
3.1.3 Train the model
After performing feature extraction, the data will be going to train the model to predict the results. How the training is performed and implemented using Machine Learning algorithms.
3.1.4 deploy the model into web pages
Flask is a micro web framework written in Python. It is classifiedasamicroframeworkbecauseitdoesnotrequire particulartoolsorlibraries. Ithasnodatabaseabstraction layer, form validation, or any other components where preexisting third-party libraries provide common functions.
Finallytorunthemodelhavetouseapp.run()method.
3.2ProposedSystemArchitecture
the messagesand queries intotwo groupsusing proposed system.Thearchitectureinvolvesthedeployingamachine learning algorithm into a well good web application using theflaskframework.
3.3 Classifying the messages

We can classify or grade the SMS messages into two types typically they are useful messages and not use full messages or junk messages and ham messages. By using somesetwordsorparameterswecanclassifythemastwo groups.Thoseparametersareshownbelow.

Fig
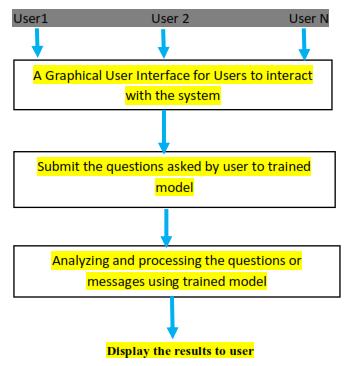
2.1 Architecture of proposed system.
The above diagram shows the architecture of proposed system. It is three tier architecture and it contains input taking and processing the input then give the processing inputtotrainedmodel forgettingtheaccurate results. We can develop the trained model using data set called SMS Spam Collection and machine learning algorithms like Naïve Bayes classifier, Non-Probabilistic algorithm and regressionalgorithmslikelogisticregression.Aftergetting the results we need to deploy those results into a web page. In order to display the results, we used scripting languages like html, cascading style sheets, Python framework flask. Using Flask, we can develop a web application which runs on the local server or non-local server for providing the interface for the user. This architecture accepts multiple users and give accurate resultstotheuser.Inordertodisplaytheresultsourteam uses the cascading style sheets for styling the website or web page. Finally, by doing the all steps we can get the correctresults.Wecanalsogetthelesstimeforclassifying
4. IMPLEMENTATION
Implementationofproposedsysteminvolvesthelearning different types of machine learning algorithms like logistic regression, support vector machine and Naïve Bayesclassifier.
Logistic Regression
Logistic regressionisone of themost popularsupervised machine learning algorithms used for classification and solvingtheregressionproblems.Algorithmforclassifying theQuoraqueriesandSMSmessages:
Step1:Readthedatafromcsvfile(typicallyadataset).
Step2:Vectorizingthedata.
Step3:Splitthedatausinginputdata.
Step4:Choosethelogisticregressionclassifier.
Step5:Fitthetraineddatausingclassifier.
Step7:Predictthedatausingclassifier.
Step8:Calculatingtheaccuracyandtime.
Step9:Plottheconfusionmatrix.

Step10:Visualizethedata.
Similarly, we can implement the algorithms of support vector machineand naïve bayes classifier for grading the Quora queries and SMS messages. The difference is to a choose a classifier with respect the algorithm which we want to develop. After doing the all-algorithms implementation we need to analyze the results of 3 algorithmsforbetteraccuracyandbettertimecomplexity or better throughput. Naive Bayes is a simple learning algorithm that uses Bayes' law with the strong assumption that the attributes of a given class are
conditionally independent. This independence assumption is often violated in practice, yet Naive Bayes often provides competitive classification accuracy.A support vector machine (SVM) is a supervised machine learningmodelthatusesaclassificationalgorithmforthe two-group classification problem. After giving the SVM model a set of categorically labelled training data, new textcanbeclassified.
5. RESULTS

6. CONCLUSIONS
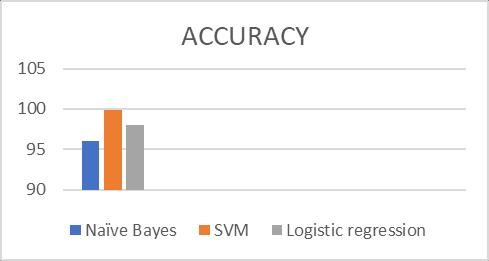
We have used different types of machine learning algorithmslikenon-probabilistic,regressionandSupport vector machine for classifyingthe junk messagesas well as Insincere questions asked on the Quora web application.Wegetgoodaccuracywithinthelessspanof time.Weachievedalesserrorrateforallthealgorithms. Now our proposed system able classify the both junk messages and Quora queries at a time with good accuracyof99.87%.
InFuture wetry to Integratea decentralizedapplication for classifying the messages and Quora queries using BlockChaintechnology.
7. REFERENCES
1. K.Chae, A.Alsadoon, P.W.C.Prasad and S.Sreedharan, "Spamfilteringemailclassification(SFECM)usinggain and graph mining algorithm," 2017 2nd International Conference on AntiCyber Crimes (ICACC), 2017, pp. 217-222,doi:10.1109/AntiCybercrime.2017.7905294.
2. M.RAZA,D.Jayasinghe and M.M.A Muslam “A Comprehensive Review on Email Spam Classification using Machine Learning Algorithms,” 2021 International Conference on Informaton Networking (ICOIN), 2021,pp-327-332, doi: 10.1109/ICOIN50884.2021.9334020.
3. A.A.Alurkar et al., "A proposed data science approach for email spam classification using machine learning techniques,"2017 Internet of Things Business Models, Users, and Networks, 2017,pp.15, doi:10.1109/CTTE.2017.8260935.
4. V.S.Vinitha and D.K.Renuka, "Performance Analysis of EMail Spam Classification using different Machine Learning Techniques," 2019 International Conference on Advances in Computing and Communication Engineering (ICACCE), 2019, pp.15,doi: 10.1109/ICACCE46606.2019.9080000.
5. N.L.Octaviani, E.Hari Rachmawanto, C.A.Sari and I.M.S. De Rosal, “Comparison of Multinomial Naïve Bayes Classifier, Support Vector Machine, and Recurrent Neural Network toClassifyEmail Spams,” 2020 International Seminar on Application for Technology of Information and Communication(iSemantic), 2020, pp. 17-21, doi: 10.1109/iSemantic50169.2020.9234296.
6. P.U.Anitha, C.V.G.Rao and S.Babu, “Email spam classificationusingneighborprobabilitybasedNaïve Bayes algorithm,” 2017 7th International Conference
on Communication Systems and Network Technologies (CSNT), 2017, p.350-355, doi: 0.1109/CSNT.2017.8418565.
7. H. Priyambowo and M. Adriani, "Insincere Question Classification on Question Answering Forum," 2019 International Conference on Electrical Engineering andInformatics (ICEEI),2019, pp. 390394,doi:10.1109/ICEEI47359.2019.8988798.
8. A.S.NagdeveandM.M.Ambekar,"SpamDetection by designing Machine Learning approach in Twitter Stream," 2020 International Conference on Smart Innovations in Design, Environment, Management, Planning and Computing (ICSIDEMPC), 2020, pp. 126130,doi:10.1109/ICSIDEMPC49020.2020.9299607.
9. N.JatanaandK.Sharma,"Bayesianspamclassification: Time efficient radix encoded fragmented database approach," 2014 International Conference on Computing for Sustainable Global Development (INDIACom), 2014, pp. 939-942, doi: 10.1109/IndiaCom.2014.6828102.