International Research Journal of Engineering and Technology (IRJET)

e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072

e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
2,3,4UG Student, Dept. of CSE Engineering, Maharaja Agrasen
Abstract – Entertainment Content recommendation systemsareimportantforseveralreasons.
First, they can help users discover new movies that they may not have otherwise found. With so many movies availabletowatch,itcanbeoverwhelmingforuserstosift through all of the options and find something that they willenjoy. A recommendation system can narrow down the choicesand presentthe user witha curatedselection ofmoviesthataretailoredtotheirpersonalpreferences.
Finally, recommendation systems can improve the efficiencyoffindingmoviestowatch.Insteadofspending alotoftimesearchingthroughvariousmovieplatformsor scrolling through long lists of movies, a recommendation system can present the user with a short list of options thatarelikelytoberelevantandinterestingtothem.
Keywords: content-based approach; sentimental analysis; recommendation system; movie ratings; inductivelearning
In recent years, there has been a proliferation of movie streaming platforms and other online sources of video content. As a result, consumers have access to a vast and ever-growingselectionofmoviesandTVshowstowatch. However, with so much choice, it can be challenging for userstofindmoviesthattheywillenjoyandthatfittheir personalpreferences.
There has been significant research on the development and evaluation of movie recommendation systems in recentyears. Researchers have explored various methods forcollectingandanalyzinguserdata,aswellasdifferent approaches for making recommendations. In this paper, we will review the state of the art in movie recommendation systems and discuss the challenges and opportunitiesthat exist inthis field. Despite the progress that has been made in this field, there are still many challenges and opportunities for future research. For example, one key challenge is to effectively handle the "cold start" problem, where the system must make recommendations for a new user with little or no
previous data. Another challenge is to improve the diversity and novelty of recommendations, while still ensuring that they are relevant and personalized.Finally, researchers are also exploring ways to incorporate additionalsourcesofdata,suchassocialmedia,toenhance theperformanceofmovierecommendationsystems.
There are two main types of recommender systems: collaborative filtering and content-based filtering. Collaborative filtering relies on user-related information, preferences, and interactions to identify similarities between users and recommend movies that similar users have enjoyed. There are two subtypes of collaborative filtering: model-based and memory-based algorithms. Memory-based methods do not have a training phase and use measures like Pearson correlation coefficient and Cosine similarity to identify similar users. Model-based methods,ontheotherhand,trytopredictuserratingsofa movie using estimated models. Collaborative filtering methods can be computationally intensive and may not perform well with sparse data. They also assume that users with similar tastes will rate movies similarly, which may not always be the case. Content-based methods, on the other hand, use information about the content of movies, such as audio and visual features or textual metadata, to find similarities among movies and recommendthosethataresimilartoonesthattheuserhas accessed or searched for. These methods do not incorporate user behavior in their recommendations. In thispaper, wewillbeexploring thelatterapproach.
Nessel stated in the movie oracle that working with examples is an essential part of human interaction and triedtoprovideamovierecommendationenginebasedon this behavior. Which of course requires considerably more computing power, as the compared bodies of text are muchlarger, but the algorithms are essentially the same [3].In a content-based movie recommendation system, theproposed algorithm uses textual metadata of themovieslike plot, cast, genre, release year and other productioninformationto analyze them and recommend
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page279
Assistant Professor: Ms. Karuna Middha1 , Student: Munzir2 , Sarthak Goja3 , Sourabh Choudhary4 Institute of Technology, Delhi, India.International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
the most similar ones [2].The paper also analyzes application similarity measure for recommendations forecasting in recommendations systems. It is shown that used methodfor computing similarity measure in recommendationssystemsare cosine similaritymeasure and Pearson correlation coefficient [1]. As the characteristics of movierecommendation go by, the user watching history is very important, so we add content-based recommendation approach. Typically, people have a tendency to think that positive reviews haveapositiveeffectandnegativereviews have negative impact. Sentiment analysis willassist us to improve the accuracy of recommendation results. Also, as we explained in our experimental results, it is necessary to make use of distributed system to solve the scalability andtimelinessofrecommendersystem[5].
Theproposedsolutionaimstoenhancethescalabilityand effectiveness of the movie recommendation system. To efficiently and quickly compute the similarity between moviesinthedatasetandreducethecomputationtimeof the movie recommendation engine, we employed the cosinesimilaritymeasure.Todeterminewhetherareview is positive or negative, we utilized the Naive Bayes classifierforsentimentanalysis.
Fig -1:ArchitectureoftheMovieRecommendationSystem
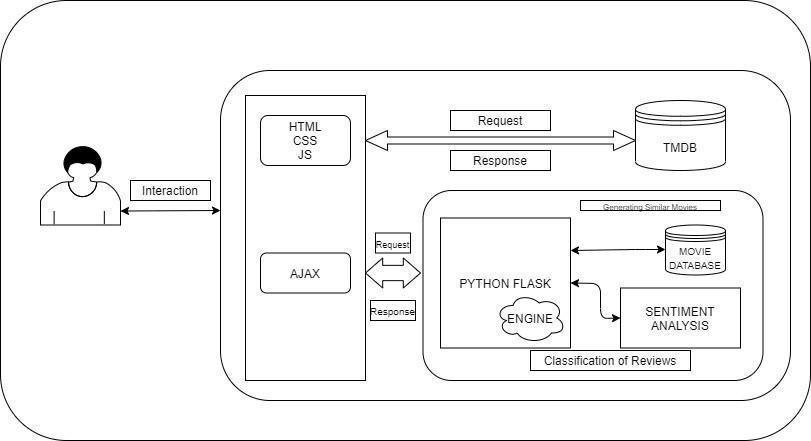
A content-based movie recommendation system utilizes user-provided data, such as ratings, feedback, and reviews,to generate a user profile, which is then used to make recommendations. As the user interacts more with the recommendation system, the engine becomes more precise and reliable. The Term Frequency (TF) and Inverse Document Frequency (IDF) techniques are utilized to retrieve and analyze information, such as movie and article titles. These techniques are used to assesstherelativeimportance of different terms.
•
• TermsAllocation
•
•
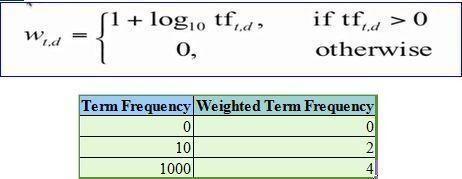
TF, or term frequency, refers to the number of times a specific word appears in a document. IDF, or inverse document frequency, is the reciprocal of the document frequencyinacollectionofdocuments.Together,TF-IDF,or termfrequency-inversedocumentfrequency,isastatistical measure that assesses the relevance of a word to a documentwithinalargercollectionofdocuments.Itisoften used in natural language processing (NLP) and machine learningalgorithmsfortextanalysisandtoscorewords.In otherwords,theweightofawordinadocumentcannotbe accurately determined by simply counting its raw frequency,andthusthefollowingequationisused: Equation:
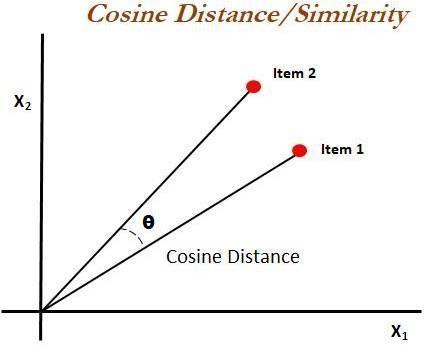
The similarity score is a numeric value that ranges from zerotooneandisusedtodeterminehowsimilartwoitems aretoeachotheronascalefromzerotoone.Thisscoreis obtainedbycomparingthetextsofthetwodocumentsand measuring their similarity. The similarity score can thereforebedefinedasameasureofthesimilaritybetween thetextualdetailsoftwogivenitems.Thiscanbecalculated usingthecosinesimilaritymeasure,whichdeterminesthe similarityoftextsregardlessoftheirsize.Cosinesimilarity is a measure used to calculate the cosine of the angle between two vectors projected in a multi-dimensional space. It is commonly used to determine the similarity
To implement a content- based filtering system, the following steps are typicallyfollowed: betweentexts.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
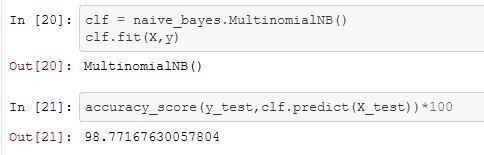
Sentiment analysis is a field within natural language processing that involves the evaluation of subjective opinions,views,orfeelingsaboutaparticularsubjectthat have been collected from various sources. In more practical business terms, sentiment analysis can be described as a setof tools used to identify and extract opinions and utilize them for the benefit of business operations.Suchalgorithmsdelve into the text to identify the underlying attitude towards a subject or its specific elements. An example of a commonly used algorithm in sentiment analysis is the multinomial naive Bayes classifier. This algorithm assumesthat the features being analyzed are produced from a simple multinomial distribution. The multinomial distribution defines the probability of observing counts within a number of categories, making it well-suited for features that represent counts or count rates. The basic idea is the same as before, except that instead of modeling the data distribution with a best-fit Gaussian curve, we model it withabest-fitmultinomialdistribution.
P (positive | overall liked the movie) = P (overall likedthemovie|positive)* P(positive)/P(overall liked themovie)
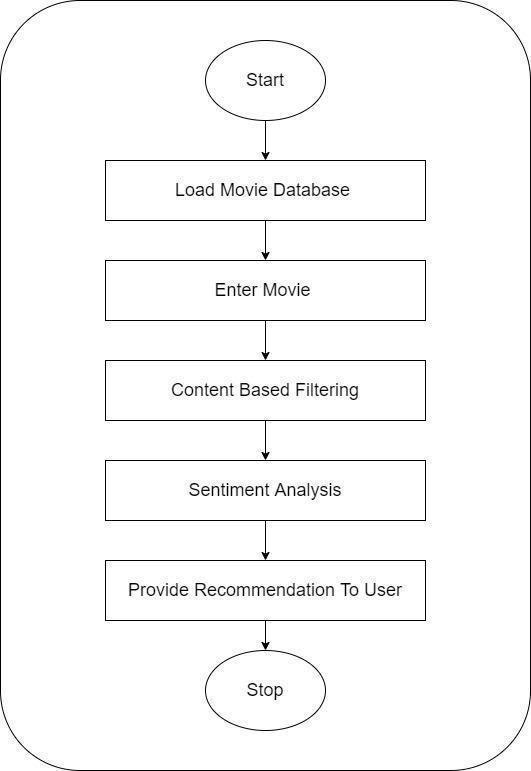
Fig -2:FlowchartoftheMovierecommendationsystem

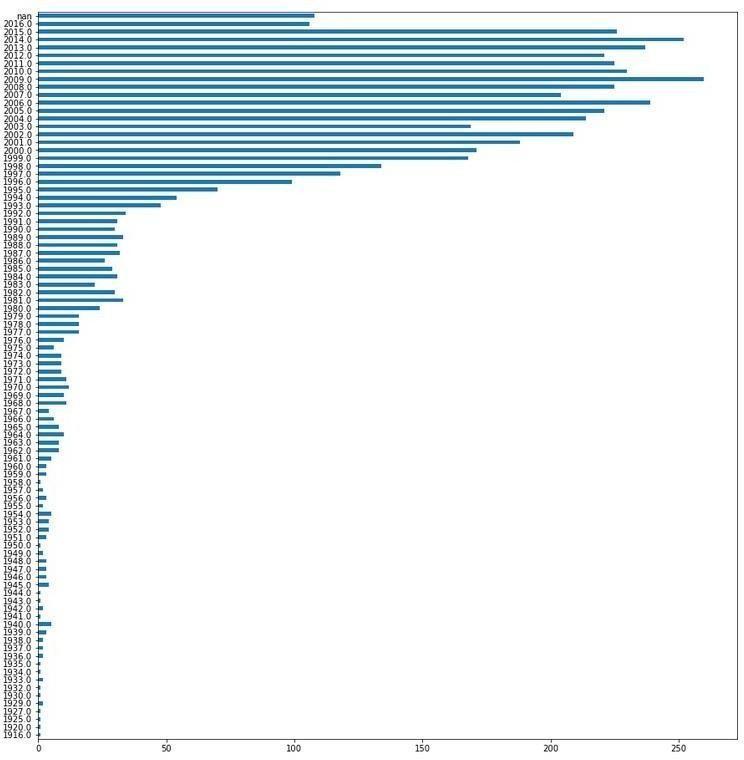
Forourresearch,weutilizedthreedifferentdatasetsfrom MovieLens, a collection of datasets generated by the GroupLens Research team for the purpose of evaluating recommendersystems.Thesedatasetsarecommonlyused by developers to test their recommendation systems. Theseare: 1. IMDB5000MovieDataset 2. TheMoviesDataset 3. Listofmoviesin20184.Listofmoviesin2019 5. Listofmoviesin2020
The Movies dataset includes metadata for all 45,000 films listedintheFullMovieLensdataset,whichincludesmovies releasedupuntilJuly 2017.Thedataincludesinformation about the cast, crew, plot keywords, budget, revenue, posters, release dates, languages, production companies, countries, TMDB vote counts and vote averages. This dataset also includes files with 26 million ratings from 270,000usersfor45,000movies,withratingsrangingfrom 1 to 5, obtained from the official GroupLens website. The datasets for movies released from 2018 to 2020 were obtainedbywebscrapingtheirrespectiveWikipediapages.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
The multinomial Naive Bayes algorithm is well-suited for classifying items with discrete features (e.g. word frequenciesfortextclassification).
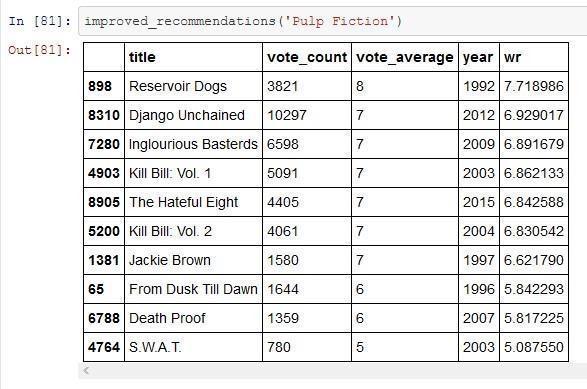
Accuracyof98.77%isobservedforthedatasetprovided.
Fig -3:PlottedgraphofTheMoviesDataset
WehaveusedtheTMDBRatingstocomeupwithourTop MoviesChart.AndalsoIMDB'sweightedratingformulato constructthechart. Mathematically,itisrepresentedasfollows: Where,
Fig -5: Observedaccuracyofsentimentalanalysis. v representsthenumberofvotesforthemovie mrepresentstheminimumvotesrequiredtobelistedinthe chart Rrepresentstheaverageratingofthemovie Crepresentsthemeanvoteacrossthewholerepot
To determine the weighted rating of each film, we will select the 25 most similar movies according to their similarity scores. We will then calculate the vote of the movie that falls at the 60th percentile of this group. Finally, we will applyIMDB's formula to compute the weighted ratingofeachmovieusing thisvalue.

Fig -4: Calculatedweightedratingforthedataset.
Ourproposedalgorithmutilizestextualmetadata,suchas the plot, cast, genre, release year, and other production details of movies, to analyze and recommend the most similar films. The user only needs to input a movie of interest, and the system will generate appropriate recommendations.Wetestedouralgorithmonasubsetof the movies available on IMDb and found that the cosine similarity measure was effective for forecasting recommendations in recommendation systems. Additionally, we implemented a feature that allows for
e-ISSN:2395-0056
p-ISSN:2395-0072
retraining of the system by rating results as "good" or "bad," resulting in more accurate predictions than simply selecting one movie or providing a single pieceoftext.
In the future, we plan to track movies searched by users in nearby locations to recommend popular films. We can also consider incorporating the watch history of geographically contextual users (those living in close proximity) with the watch history of the user to provide more"location-relevant"recommendations.Additionally, byusinguserratingsofmoviesfromwebsiteslikeRotten Tomatoes, Metacritic, and IMDb, we can explore the possibilityofcombiningcollaborativefilteringtechniques with ourmethod to create a hybrid model that combines theadvantagesofbothapproaches.
[1] Mykhaylo Schwarz, Mykhaylo Lobur, Yuriy Stekh, Analysis of the Effectiveness of Similarity Measures for
Recommender Systems, 978-1-50905045- 1/17/$31.00 ©2017 IEEE M. Young, The Technical Writer’s Handbook. Mill Valley, CA: UniversityScience,1989.
[2] RujhanSingla,SaamarthGupta,AnirudhGupta,Dinesh KumarVishwakarma,FLEX:AContentBasedMovie Recommender, 978-1-7281-6221-8/20/$31.00 ©2020IEEE.
[3] Jochen Nessel, Barbara Cimpa, The MovieOracleContent Based Movie Recommendations, 978-076954513-4/11$26.00©2011IEEE.
[4] ShreyaAgrawal,PoojaJain,AnImprovedApproachfor Movie Recommendation System, 978-1-509032433/17/$31.00©2017IEEE
[5] Yibo Wang, Mingming Wang, and Wei Xu, A SentimentEnhancedHybrid RecommenderSystemfor Movie Recommendation: A Big Data Analytics Framework, Hindawi Wireless Communications and MobileComputingVolume2018,ArticleID8263704
[6] F. Furtado, A, Singh, Movie Recommendation System UsingMachineLearning,Int.J.Res.Ind.Eng.Vol.9,No. 1(2020)84–98
[7] Robin Burke. Hybrid recommender systems: Survey and experiments. Usermodeling and user- adapted interaction,12(4):331–370,2002.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
[8] Erik Cambria. Affective computing and sentiment analysis. IEEE Intelligent Systems, 31(2):102–107, 2016.
[9] IvanCantador,AlejandroBellog´´ın,andDavidVallet. Content-based recommendation in social tagging systems. In Proceedings of the Fourth Conference on Recommendersystems,pages237–240.ACM,2010.
[10] Paolo Cremonesi, Yehuda Koren, and RobertoTurrin. Performance of recommender algorithms on top-n recommendation tasks. In Proceedings of the Fourth Conference on Recommender Systems, pages 39–46. ACM,2010.ISBN978-1-60558-906-0
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal