International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072
Pranali Dhawas1 , Prajwal Kolhe2 , Faizan Khan3 , Lakshya Chauragade4, Apoorva Dhimole5
1 Assistant Professor, Department Of Artificial Intelligence, G H Raisoni College Of Engineering, Maharashtra, India. 2345B.Tech Artificial Intelligence, G.H. Raisoni College of Engineering, Maharashtra, India ***
Abstract - Many companies and massive organizations have numerous documents in bulk and required to keep them in different clusters. In recent years, this job has becoming time consuming as no of document and article has increased. The Analysis of the document is one of the subjective research technique which is used to review by the analyst estimate the idea. With the help of some visual technique we get the most of the layout and text format in extremely in proper output format. With the help of the model we can sort most of the architecture document in large scale. With the help of Layout model and new strategies to interact with various layout in any format in a single model framework. We used our own data collected through out colleagues in university to train it in specific manner that it identify and then classify marksheets and Certificates. Our model use only some of the modern techniques for the visual language task and also for the text images to find the some similar combination and task which make the simple way to detect the interaction between the different stages.
Intoday’sworldthereisahugeamountoftextdata,documentdigitizationisatechniquewhichisbeingusedinvariousfields anddomainsthatdealswithhugeamountsofarchives.Documentanalyzerfocusesoncategorizingdocumentonbasisoftext, imageandlayoutofdocument,typicallydocumentscanbeclassifiedondifferentlyonnumerouscontext.Whileattemptingthe taskofanalysingtextdocumentsdocumentclassificationistheimportantprocedure tofollow.Butwhiledoingdocument classificationwehavetodealwithsomechallengeslikehighvariabilityamongthesamedocumentorclassandlowvariability between different classes or documents. Previous studies have addressed the structural similarity between classes or documents.Studieshasalsofocusedonextractingcharacteristicstomakeeachclassseparate.Researchershavedeveloped variousdeeplearningapproachestoimprovetheperformanceoftheirdocumentclassifiers.In2014researchertrainedand proposedasimplefourlayerCNNfromstarting.Then,weusetheImagenettoimprovethelearningrateofthenetworktowork ineffectivewayonthemodel.MostrecentresearchhaveshowntheusageofOCRtoextracttheparticularinformationand features to with multiple algorithms to classify, NLP was also used to boost the performance of these architecture. Our architectureusesimagefeatures,textextraction,andlayoutofdocumenttoovercomeperviousdefectsanddrawbackswith significantaccuracy.
InRecenttimetheNlpandCVbecamemorepopulartechniquesinthisareaandalsomakeprogressindifferentfields.
• The devlin et al Explained the new language and rendering the model, which is used to see the the representation of bidirectionalformthevariousdatabythejointlythecondition.
•BarcelonaSupercomputingCenter–Upgradingtheaccuracyandeditclassificationimagedirecttotheparallelsystem.
•Linkbert-TrainingthelanguagemodelbyUsingDocumentlink.
Proposedsolutioninthispaper“DocumentAnalyzer”attemptstopredicttheclassofadocumentbyanalysingthessssimage content.Tosolvethischallengewehaveaddressedthreeways–Imageclassificationproblem,textclassificationproblemand layoutidentification.Weproposeamulti-modalTransformermodeltojointhedocumentinparticulartext,layoutdefinition and visual data inside the pretraining stage, the cross-modal learns the interaction in a single framework. The class of documenthasbeenpredictedaccordingtovariousfeatureslike,thedesignofthedocument,headerandfooterofdocument, bodyorthematterofthedocumentwhichgetsextractedbytheOCRtechniquesandhowdocumentisbeingformatted,allof thesefeatureshelptofindtheexactclassofthegivendocument.Butsometypeofdocumentsalsohavecommonfeaturesfor examplegovernmentcertificatehavesealofthegovt.and/orlogo,whichcanhelpclassifythedocuments.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072
TheLayoutLMarchitectureisdividedinto3sectiontextembeddingvisualembeddingandlayoutembedding.Inthisofthe embeddingthecommonworkisusetotokenizetheocrandthesequenceofthetextandgivingsomesegment.Thesubwordis onealgorithmusedintheNaturallanguageprocessing.thesentencesisusedtocheckthecharacterintheabovementioninput andtoseethemostcommoncombinationofthevariouscharacterinthesentence.
ImageProcessing-Thismoduledealswithbasicimagepreprocessingsteps.Thisintendstodobasicpreprocessinglikeimage rescaling,imageresizingandcompression, morphologicalimagepreprocessinglikeErosionandDilation.Theoutputofthis modulewillbesimilarpre-processedimages.
ScriptRecognitionOROCR-Opticalcharacterrecognitionisatechniquetorecognizetextfromaimage.Aimofthismoduleisto extractthetextthisisalsocalledastextraction.Thismodulewillgivetheoutputastheunlabeledtextdata.
NaturalLanguagePreprocessing-Theoutputfromthelastmodulewhichistextdatawillbepre-processedinthisstep.Aimof this moduleis to clean the text data from previous module, we have used several techniques like removal of stop words, stemming,lemmatization,thiswillfurtherhelpinfeatureextraction.
FeatureExtraction-Featureextractionistheprocessinwhichwetrytogainthefeaturesfromtherawtextdataintonumerical format.
Encoding-Encodingisalsocalledasvectorization.Thisprocessdealswithconvertingthetextdataintonumericalvectors. Convertingtextdataintohighdimensionalvectorformat.Wecannotfeedthetextdatatothemachinelearningmodelsowe convertthetextdataintonumericalformat.
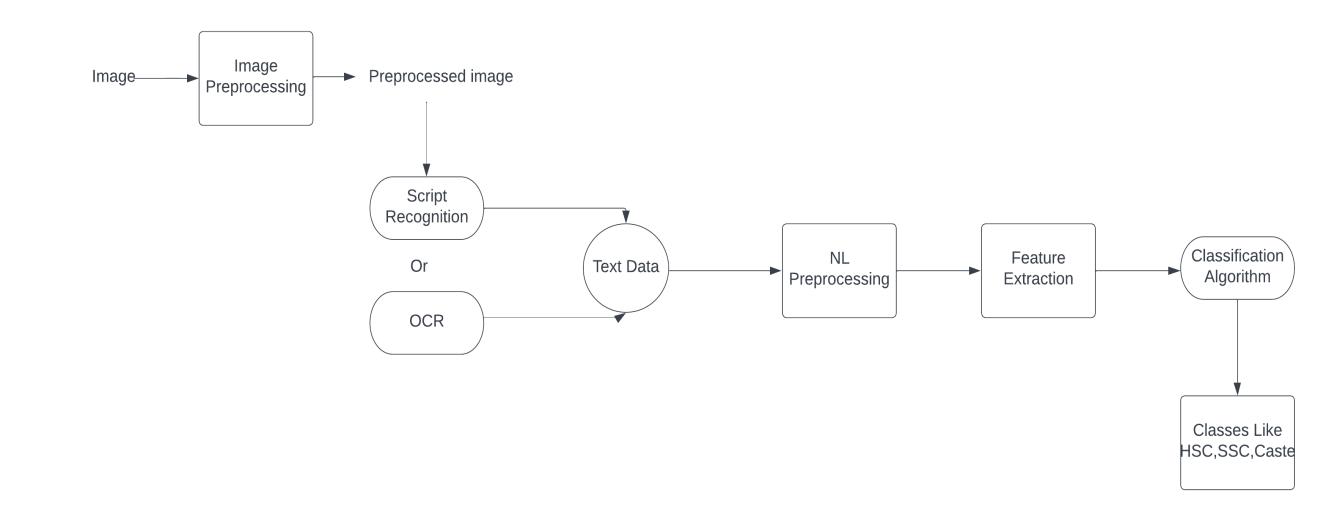
Classification-This modulewill help toclassify the document on the basis ofextracted features. We will use classification algorithmslikeNBclassifier,LogisticRegression,RandomForest,etc.thiswillgivetheoutputclassofthedocumentbyassigning oneoftheclassfromouravailableclasses.
Inordertotrainandevaluatedocumentclassifier,wehavecollectedabovementioneddocumentsfromthestudents from differentbackgroundsanddepartmentsofG.H.RaisoniCollegeofEngineering,Nagpur,Maharashtra.Eachclassofdocuments isusedinintentiontoclassifythecorrectdetailsfromdocumentimagewhileusingOCRtechnique.Documentsarecollected fromdifferentstatestudents.Asthesedocumentsarefromdifferentstates–thelayoutsofthedocumentsaredifferentforeach stateinIndia.FortheDocumentAnalyzerwehaveusedvariousclassestoclassifythedocumentsuchasSSCMarksheet,HSC Marksheet,CastValidityandIncomeCertificate
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072
Fig-1:SampleInputImage.
5. Traning Accuracy
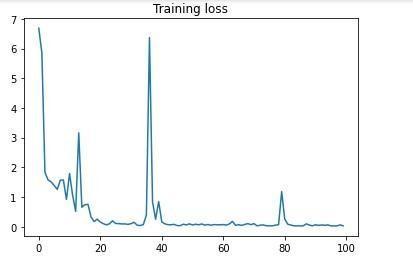
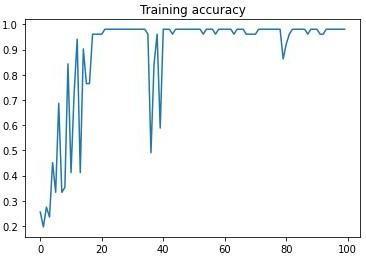
Fig-2:TraningAccuracyAndTraningLossoftheModel.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072
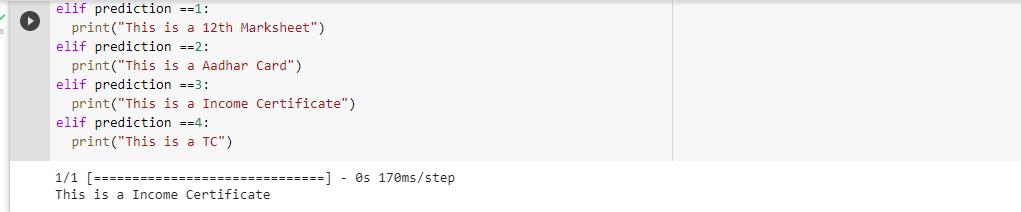
Aswehaveuploadeddocumentasshownintheaboveinputphaseforthepredictionofthedocumenttype.Wegotadesire predictionasshowninbelowsnapshot.
Fig-3:TheOutputoftheModel
WeareabletoAnalyzeDocumentusingPre-DataTrainingtothemodel.ThemodelisabletoprovideaspecificDocumentand informationefficientsummary.Wegaveamulti-modelpretrainingwayforvisualdocumentunderstandingtasks.
TheDocumentanalyzethecategorizingdocumentonbasisofthetext,imageandlayoutofdocument,typicallydocumentcan be classified on different numerous context also. We have compared the different types of document, Original as well as photocopydocumentwhiletrainingperiodanddetecttheoutputaccordingly.
[1] Adam W. Harley, A. U. (2015). Evaluation of Deep Convolutional Nets for Document ImageClassification and Retrieval.Toronto,Ontario:Ryerson
[2] N. Chen and D. Blostein. A survey of document image classification: Problem statement, classifierarchitecture and performanceevaluation.IJDAR,10(1):1–16,2007.
[3] K.Collins-ThompsonandR.Nickolov.A clustering-basedalgorithmfor automaticdocumentseparation.InSIGIR,pages1–8,2002.K.
[4] Image and Text fusion for UPMC Food-101 using BERT and CNNs Ignazio Gallo, Gianmarco Ria,NicolaLandro,and RiccardoLaGrassa
[5] AggregatedResidual Transformations forDeepNeural NetworksSainingXie,Ross Girshick,PiotrDollár,ZhuowenTu, KaimingHe
[6] LinkBERT PretrainingLanguageModelswithDocumentLinksMichihiroYasunagaJureLeskovecPercyLiangStanford University{myasu,jure,pliang}@cs.stanford.edu
[7] C.P.Bean,“Fineparticles,thinfilmsandexchangeanisotropy,”inMagnetism,vol.III,G.T.RadoandH.Suhl,Eds.NewYork: Academic,1963,pp.271–350.
[8] DigitizationofSoiledHistoricalChineseBambooScrolls.InProceedingsof the13thIAPRInternational [9] Workshop on Document Analysis Systems, DAS, Vienna, Austria, 24– 27 April 2018; pp. 55–60.[CrossRef]
[10] Mohammed,H.;Marthot-Santaniello,I.;Margner,V.GRK-Papyri:ADatasetofGreekHandwritingon
[11] PapyrifortheTaskofWriterIdentification.InProceedingsofthe2019InternationalConferenceonDocument
[12] AnalysisandRecognition,ICDAR2019,Sydney,Australia,20–25September2019;pp.726–731.[CrossRef]
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page217