International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072
Department of Computer Science and Engineering (PSG College Of Technology , Coimbatore) Avinashi Road , Coimbatore , Tamil Nadu - 641004 ***
Abstract - This research aims to lower the barrier of day-today communication for disabled people by developing a userfriendly, cost-effective system by which we can determine the most appropriate character from the sign that the user is showing to the system. About nine million people in the world are deaf and mute. Communication between differently-abled people and general people has always been a challengingtask but sign language helps them to communicate with other people. But not everyone understands sign language and here is where our system will come into the picture. Various machine-learning algorithms have been investigated to facilitate pattern identification and processing. Advanced Python is used to train the model usingtheimage featuresthat were obtained. In response to the sign presented to the model, the trained model accurately predicts the words thataremost appropriate using the datasets that are fed into the system. Words that are predicted are generated into a voice output. Sign language provides a way for speech-impaired and hearing-impaired people to communicate with other people. Instead of a voice, sign language uses gestures to communicate. Sign language is a standardized way of communication in which every word and alphabet is assigned to a distinct gesture The solution aims to assist those in need, ensuring social relevance by offering an interface that can help facilitate simple and unrestricted communication between a wide range of people Computer vision and machine learning researchers are now conductingintensiveresearchin the area of image-basedhand gestureidentification. Intending to make human-computer interaction (HCI)simplerandmore natural without the use of additional devices, it is an area where many researchers are researching. Therefore, themain objective of research on gesture recognition is to develop systems that can recognize certain human gestures and use them, for instance, to convey information.
Key Words: Mediapipe,OpenCV,SLR,gTTs,HCI
Acrucialapplicationofgesturerecognitionissignlanguage detection.Currenttechnologiesforgesturerecognitioncan bedividedintotwotypes:sensor-basedandvision-basedIn sensor-based methods, data gloves or motion sensors are incorporated from which the data of gestures can be
extracted.Evenminutedetailsofthegesturecanbecaptured bythedatacapturingglovewhichultimatelyenhancesthe performanceofthesystem.However,thismethodrequires wearingadata-capturinghandglovewithembeddedsensors whichmakesitabulkydevicetocarry.Thismethodaffects the signer’s usual signing ability and it also reduces user amenities.Vision-basedmethodsincludeimageprocessing. This approach provides a comfortable experience to the user. The image is captured with the help of cameras. No extradevicesareneededinthevision-basedapproach.This methoddealswiththeattributesoftheimagesuchascolour andtexturethatareobligatoryforintegratingthegesture. Although the vision-based approach is straightforward, it hasmanychallengessuchasthecomplexityandconvolution ofthe background,variationsinilluminationand tracking other postures along with the hand object, etc. arise. Sign languageprovidesawayforspeech-impairedandhearingimpairedpeopletocommunicatewithotherpeople.Instead ofavoice,signlanguageusesgesturestocommunicate.Sign languageisastandardizedwayofcommunicationinwhich everywordandalphabetisassignedtoadistinctgesture.It would be a win-win situation for both differently-abled peopleandthegeneralpublicifsuchasystemisdeveloped where sign language could be converted into text/speech. Technology is advancing day after day but no significant improvements are undertaken for the betterment of specially-abledcommunities.Ninemillionpeopleworldwide are both deaf and silent. Differently abled persons and regularpeoplehavelongfounditdifficulttocommunicate, but sign language makes it easier for them to do so. However,noteveryoneisfluentinsignlanguage,whichis whereourapproachwillbeuseful.
Almostalloftheworld'smainoperatingsystemshave somesortofsoftwarethatcanassistinturningthetext onyourscreenintoaudiomessages.Unfortunately,the majority of these accessible solutions lack advanced technology. In other words, despite all the amazing thingstechnologycanachieve,ifyouareunabletoseea
© 2023, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page159
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072
webpage,youmighthavetolistentoitsfullcontentsin linearorder.
Theworryingtrendofbrailleilliteracyisaproblemin theblindworld.Brailleisclunky,challengingtomaster, and sluggish to process, according to some blind readers. A braille book is much longer than the same bookinprintbecausebrailletakesupmuchmorespace onapage.
Althoughtheabilitytouseheadphonestohearprompts isbecomingmoreprevalent,itisstilluncommon.Braille on the buttons doesn't assist if you can't see the matchingmessagesandnumbersonthescreen,making an ATM inaccessible to the blind if it doesn't communicate.
Duetothewidespreadmisperceptionthatbeingblindis adisability,blindpersonsarefrequentlydismissedona systemiclevelbeforetheyhavetheopportunitytoshow theirpotential.Blindpersonsarefrequentlyemployed byfactoriesthatpaythemcentsonthedollarfortheir labouraftertrainingthemtoperformmenialactivities in"shelteredworkshops."
Thispaperrevolvesaroundtheestablishmentofageneral frameworkforcreatinganSLRmodel.SLRdataprocessing involves sign representation, normalization and filtering, data formatting and organization, feature extraction and featureselection.
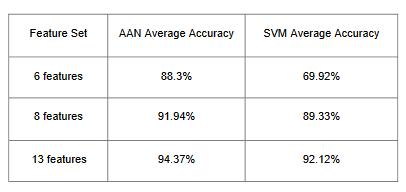
In this research, MATLAB is used to demonstrate the recognitionof26handmotionsinIndiansignlanguage.The suggested system has four modules, including feature extraction,signrecognition,sign-to-text,pre-processingand hand segmentation. The suggested system aids in the reduction of dimensions. It becomes more difficult to visualizethetrainingsetandsubsequentlyworkonitasthe number of features increases. Sometimes, the majority of these traits are redundant since they are connected. Algorithms for dimensionality reduction are useful in this situation. By getting a set of principal variables, dimensionality reduction is the process of reducing the numberofrandomvariablesbeingconsidered.Itcanbesplit intotwocategories:featureextractionandfeatureselection.
BSLusesatwo-handedfingerspellingsysteminthecurrent systems,asopposedtoASL'suseofaone-handedapproach (andFSL).
Gesture recognition has several uses, including the understandingofsignlanguage.
Signlanguagerecognitionhastwodifferentapproaches.
-Glove-basedapproaches
-Vision-basedapproaches.
Glove-basedtechniquesSignersinthiscategorymustputon asensorgloveoracolouredglove.Bywearingglovesduring thesegmentationprocess,thetaskwillbemadesimpler.The disadvantageofthisstrategyisthatthesignermustwearthe sensor hardware and the glove while the device is in operation. LDA is mostly utilised in machine learning, pattern identification, and statistics. It is employed to identifyalinearcombinationofpropertiesthatdistinguishes betweenatleasttwoclassesofobjectsoroccurrences.LDA describeshowtomodelthedistinctionsbetweenthevarious data classes. Continuous measurements are conducted on independentvariablesforeachobservationinLDA.
• DesigningSLRtoolsthatgetcloseto100%accuracyona bigvocabularyisnotyetdone.
• Future emphasisshould be paidmoretotheusability factor.
• generatecriticism
• Techniques that allow for the quick identification of frequentmistakeswhileguaranteeingthatuserinputis respected.
2. DeepLearningforSignLanguageRecognition:Current Techniques,Benchmarks,andOpenIssues-Muhammad Al-Qurishi,,ThariqKhalid,RiadSouissi
The solution's input layer is made up of a hand sign presentationdisplayandaninputdevicebasedonSLRdata collectiontechnique.Thesecondlayeristhepre-processing layer,whichdecodesasignintothenecessarydataformat and filters gesture data. There may also be extra stages, includingsamplenormalizationorintegratingdatafroma video's subsequent frames. Feature extraction is the first operationthesystemtakesafterreceivingsigndata.Visual features, hand movement characteristics, 3D skeleton features, and face features are just a few examples of the manyvariouskindsoffeaturesthatcanbeemployedasthe main source of information. One of the key elements affecting the SLR method's effectiveness is the choice of featurestobeusedinthealgorithmtraining.Beforebeing
2023, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page160
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
supplied to the modelling layer, the data are normally processedandconvertedintoavectorformat.
Modulesinvolved–
Data collection can be divided into 3 - Hardware-based, vision-basedandhybrid
•Hardware-basedmethodsmakeuseoftoolsorwearable sensors. To recognize sign language, wearable technology frequentlyattachessensorstotheuserorusesaglove-based system. These tools, whether they are gloves, rings, or sensors, can translate sign language into text or speech. Becausecumbersomeapparatusmustbeworn,sensor-based techniques are never natural. They instead suggest RealSense,acutting-edgemethodthatcannaturallyidentifyand trackhandplacements.
•Vision-basedtechniquesarelessrestrictiveonusersthan sensor-based ones. Recent SLR studies sometimes rely on input in the form of visual data. They are limited by the subparfunctionalityoftraditionalcameras.Anotherissueis that simple hand features can lead to ambiguity while complexfeaturestakemoretimetoprocess.
•Hybrid-Whencomparedtoothermethods,hybridmethods performaswellasorbetter.Thismethodcallsforhardware andvision-basedmodalitiestobecalibrated,whichcanbe particularly difficult. This approach is quicker because it doesn't need to be retrained. Since it influences how the modelsaretrainedand,consequently,howquicklytheymay become skilled at discerning between distinct signs or words, feature extraction is a crucial stage for all SLR models. Features are always derived from raw data and correspondtothepositionsofbodycomponentscrucialfor sign language communication (certain spots on the hands andface).Featuresaredeterminedusingstatisticalmethods withpredeterminedweightsandexpressedasvectors.
Essentially,featureselectionmeansreducingtheamountof information in the data to a select few relevant statistical characteristics,whicharethenfedintothemachinelearning network.Thegoal isto reducethenumberof calculations requiredtoproduceanaccurateforecastbyonlyincluding those features that significantly improve the algorithm's abilitytodistinguishbetweendistinctclasses.
ConvolutionalNeuralNetworkarchitectureisimplemented forIndianSignLanguagestaticAlphabetrecognitionfrom the binary silhouette of the signer hand region after reviewing several existing methods in sign language recognition. The proposed method was implemented successfullywithanaccuracyof98.64%,whichissuperiorto themajorityofthecurrentlyusedtechniques.Problemswith hand gesture recognition are approached using either a
glove-based method or a vision-based one. Since these particulardevicescapturedatadirectlyfromsigners,gloves offergoodaccuracy.
Basedonfeaturesdeterminedusingvariousimageorvideo processing techniques, vision-based systems perform the taskofobjectrecognitionfromimagesorvideos.
Thesuggestedarchitecturecaneventuallybeexpandedwith new approaches and modules to create a fully automated sign language recognition system. Soon, facial expression andcontextanalysiswillbeincorporatedintosignlanguage recognition.Theresultingrecognitionaccuracyoutperforms themajorityoftheavailabletechniques.
4. Real Time Sign Language Recognition and Speech Generation- Kartik Shenoy, Tejas Dastane,Varun Rao , DevendraVyavaharkar
Becausetheyaremoreaccuratethangadgetmethods,image processing and neural network-based sign language recognition systems are chosen. create a neural networktrainedsignlanguagerecognitionsystemthatisbothuserfriendlyandaccurate,generatingbothtextandspeechfrom theinputgesture.
• Theproposedsolutionwasputtothetestinreal-world scenarios, and it was demonstrated that the classification models that were created could identify everytaughtgesture.
• The system will be improved in the future, and trials usingfulllanguagedatasetswillbeconducted.
5. IndianSignLanguageRecognitionSystem-Yogeshwar IshwarRokade,PrashantJadav
Ingesturerecognition,signlanguagerecognitionformsan important application. It consists of two different approaches.
Thesignerinthiscaseneedstowearasensororacoloured glove.Usingtheglovemakesthesegmentationphase'sduty easier.Thedrawbackofthisstrategyisthatthesignermust carrythesensorhardware,includingtheglove,throughout theentireprocess.
It makes use of the algorithms of image processing for detectingandtrackingthehandsignsincludingthesigner’s facial expressions. This vision-based approach is simple
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072 © 2023, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page161
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
sincethesignersneednotwearadditionalhardware.Inthe proposedsystemvision-basedapproachisused.
Thenumberofsignsmadeuseinthesystemare A,B,D,E,F,G,H,J,K,O,P,Q,S,T,X,Y,Z.
B.HandObjectDetection:
•HandSegmentation
•FilterandNoiseRemoval
•FeatureExtraction Classification Table -1: Accuracychart
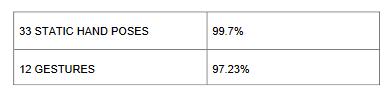
defined in ISL for gesture categorization. The system can attainanaccuracyof99.7%forstatichandposturesandan accuracyof97.23%forgesturesusingthismethodology.
DatasetUsed:
Pre-Processing: HandExtractionAndTracking
Feature Extraction Using Grid-Based Fragmentation Technique
Classification:RecognitionofISLHandposesusingkNN
• GestureClassificationusingHMM
• TemporalSegmentation
6. Real-Time Indian Sign Language (Isl) RecognitionKartik Shenoy ,TejasDastane Varun Rao , Devendra Vyavaharkar
The method described in this work uses grid-based characteristicstorecognisehandpositionsandmotionsfrom theIndianSignLanguage(ISL)inreal-time.Withthehelpof thissystem,thecommunicationgap between thehearingandspeech-impairedandthegeneralpublicismeanttobe closed.Thecurrentsolutionsareeithernotreal-timeoroffer justamodestlevelofaccuracy.Theoutputfromthissystem is good for both parameters. It can recognise 33 hand positionsandafewISLmovements.Asmartphonecamera recordssignlanguage,andtheframesaresenttoadistant server for processing. It is user-friendly because no other hardwareisrequired,suchasglovesortheMicrosoftKinect sensor. Hand detection and tracking employ methods including Face detection, Object stabilisation, and Skin Colour Segmentation. A Grid-based Feature Extraction approachisalsousedintheimage,representingtheattitude ofthehandasaFeatureVector.Thek-NearestNeighbours method is then used to categorise hand positions. The motion and intermediate hand postures observation sequences,ontheotherhand,aregiventoHiddenMarkov Modelchainscorrespondingtothe12pre-selectedgestures
Table-2: Accuracychart
7. TexttoSpeechConversion-S.Venkateswarlu,Duvvuri BKKameshDuvvuri,SastryJammalamadaka
The user can now hear the contents of text images rather than reading them thanks to a novel, effective, and costbeneficial technique proposed in the current research. It combinestheprinciplesofTexttoSpeechSynthesizer(TTS) andOpticalCharacterRecognition(OCR)intheRaspberryPi. Peoplewhoareblindorvisuallychallengedcanefficiently communicatewithcomputersusingthis typeofdevice. In computer vision, text extraction from colour images is a difficult task. Using OCR technology, text-to-speech conversion reads English alphabets and numbers that are present in images and converts them into voices. The device'sdesign,implementation,andexperimentalfindings arecoveredinthispublication.Thevoiceprocessingmodule andthepictureprocessingmodulemakeupthisgadget.The device's 900 MHz processing speed was taken from the RaspberryPiv2platform.
8. Design and Implementation of Text To Speech Conversion for Visually Impaired PeopleItunuoluwaIsewon,JeliliOyeladeOlufunkeOladipupo
There are two basic stages to the text-to-speech (TTS) synthesisprocess.Firstistextanalysis,whichconvertsthe inputtextintoaphoneticorotherlinguisticrepresentation; second is speech waveform creation, which creates the output using this phonetic and prosodic data. Typically, thesetwostagesarereferredtoashigh-levelandlow-level synthesis.Theinputtextcouldbe,forinstance,scannedtext
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072 © 2023, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page162
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072
fromanewspaper,standardASCIIfromemail,amobiletext message, or data from a word processor. The character string is then pre-processed and examined to produce a phonetic representation, which is typically a string of phonemes plus some extra information for proper intonation, length, and stress. The information from the high-level synthesiser is ultimately used to make speech sounds using the low-level synthesiser. There have been numerousreportedmechanicalattemptstoproducespeechlikesoundssincetheeighteenthcentury.
9. P.V.V Kishore, P. Rajesh Kumar, E. Kiran Kumar &S.R.C.Kishore, 2011,Video Audio Interface for Recognizing Gestures of Indian Sign Language, InternationalJournalofImageProcessing(IJIP),Volume 5,Issue4,2011pp.479-503
Theauthorsofthepaper[12]suggestedasystemthatcan translateISLmotionsfroma videofeedintoEnglish voice and text and recognise them. They achieved this by employing a variety of image processing techniques, including edge detection, wavelet transform, and picture fusion, to separate the shapes in the video stream. Shape features were extracted using Ellipsoidal Fourier descriptors,andthefeaturesetwasoptimisedandreduced usingPCA.Thesystemwastrainedusingthefuzzyinference system,anditachievedanaccuracyof91%.
10. Adithya, V., Vinod, P. R., Gopalakrishnan, U., and IEEE (2013). "Artificial Neural Network Based Method for IndianSignLanguageRecognition."
The authors of the paper [13] proposed a method for automatically identifying movements in Indian sign language.Thesuggestedmethodtransformstheinputimage beforeusingittodetecthandsusingYCbCrcolourspaceand digital image processing techniques.Some ofthemethods usedtoextractthefeaturesincludedistancetransformation, projection of distance transformation coefficients, Fourier descriptors, and feature vectors. The data were classified usinganartificialneuralnetwork,andtherecognitionrate was91.11percent
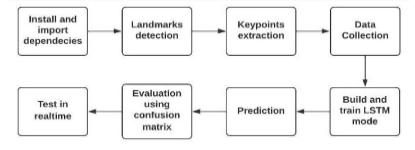
We have used Media Pipe holistic for real-time image tracking. Separate models for posture, face, and hand componentsareindividuallyintegratedintotheMediaPipe Holistic pipeline and are each customized for their respective fields. As a multi-stage pipeline, Media Pipe Holisticismadetotreateachregionwiththeproperimage resolution.WestartbycollectingkeypointsfromMediaPipe holisticandcollectabunchofdatafromkeypointsi.e.,our hands,ourbodyandonourfaceandsavedataintheformof NumPy arrays. We can vary the number of sequences according to our needs, but each sequence will have 30 frames.
•WethenbuildanLSTMmodeltotrainwithourstoreddata which helps us to detect action with several frames. The usageofLSTMwasadvantageousbecauseLSTMnetworks areanextensionofrecurrentneuralnetworks(RNNs)which were developed primarily to address failures in RNNs. LSTMsprovideuswithalargerangeofparameterssuchas learningrates,andinputandoutputbiases.Thus,thereisno needforprecisemodifications.WithLSTMs,updatingeach weightismuchmoresimilartoBackPropagationThrough Time(BPTT),reducingcomplexitytoO(1).
•Imageprocessingistheprocessofanalysingapictureand turningtheresultsintosentences.Forthis,adatasetwitha significantnumberofimagesandcorrespondinglydetailed captions is needed. To forecast the characteristics of the photos in the dataset, a trained model is employed. This comesunderphotodata.Thedatasetisthenanalysedsuch thatonlythemostintriguingtermsareincludedinit.Datain textformat.Wetrytofitthemodelwiththesetwosortsof data.Byusinginputwordsthatwerepreviouslypredictedby themodel andtheimage,themodel'stask istoproduce a descriptivesentenceforthepicture,onewordatatime.
• We have utilized categorical classification for model training as we include multiple classes of signs However thereisnointrinsicorderingofthecategories.Thenumber ofepochsforthemodelisdeterminedbyusifweincrease thenumberofepochs theaccuracyincreasesbutthetime takentorunthemodelalsoincreasesandoverfittingofthe modelcanhappen,forgesturerecognition.
•Oncetrainingisdone,wecanusethismodelforreal-time hand gesture detection and simultaneously convert the gesture to speech using OpenCV. OpenCV is a significant open-sourcetoolkitforimageprocessing,machinelearning, and computer vision. Python, C++, Java, and many other programming languages are supported by OpenCV. It can analysepicturesandmoviestofindfaces,objects,andeven human handwriting. When it is integrated with various libraries,suchasNumpywhichisahighlyoptimizedlibrary fornumericaloperations.
Fig-1: Systemflow–1
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072
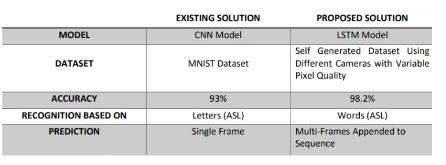
Table-3: Comparisonbetweenexistingandproposedmodel
connectedlayerusingSoftMaxactivation.Aregressionlayeris thenapplied.
4.4
We choose the number of epochs for the model; while this increasesaccuracy,italsolengthensthetimeittakestorun and increases the risk of overfitting the model, which is problematicforgesturerecognition.
WehaveusedOpenCVforcapturingtheinputvideothrough severaldevicessuchasdesktopwebcam,phonecameraand DSLR. Python comes with several libraries for processing imagesandvideos.OpenCVisoneamongthem.Alargelibrary calledOpenCVhelpsprovideavarietyofmethodsforimage andvideooperations.Wecanrecordvideofromthecamera usingOpenCV.Itletsyoucreateavideocaptureobjectwhich ishelpfultocapturevideosthroughawebcamandthenedit them as you see fit. We can specify the countdown timer insteadofchoosingoneofthespecifiedcountdowns.Whenthe appropriate key is pressed, the countdown timer is started, and we display the countdown on our camera using the cv2.putText()function.Whenthecountdownreacheszero,we takeanimage,displayitforapredeterminedamountoftime, andthenwriteorsaveittodisc.
WehaveusedMediaPipeHolisticforfeatureextraction.The Media Pipe Holistic pipeline includes separate models for posture,face,andhandcomponentsthatareeachtailoredfor theirparticularindustries.MediaPipeHolistic,amulti-stage pipeline,isdesignedtotreateachregionwiththeappropriate image resolution. Starting with key points from Media Pipe Holistic,wegatheralotofdatafromkeypointssuchasour hands,ourbody,andourfaceandrecordtheinformationas NumPyarrays.Thenumberofsequencescan bechangedto suitourneeds,buteachserieswillinclude30frames.

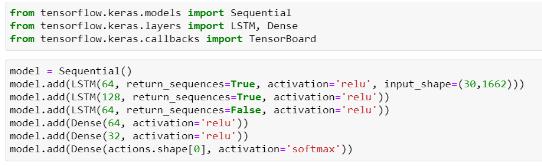
Here,weemployauniqueclassofRNNcalledanLSTM,which enables our network to learn long-term and training of our storeddatatakesplace,whichenablesustorecognizeaction overseveralframes.Thesecondtechniqueinvolvessending theInceptionCNNmodel'santicipatedlabelstoanLSTM.The inputtotheLSTMisprovidedbythefinalhiddenlayerofthe CNN.WeutilizedanetworkwithasinglelayerofseveralLSTM units after extracting the bottleneck features, then a fully
value:
ThegesturesweretranslatedintovocaloutputusingGoogle Text-to-Speech.Inadditiontothis,theoutputtextisdisplayed onthescreen.Thiswholesetoftheprocesstakesplaceagain forrecognizingasentence.
Fig-2 : Systemflow2
TheMediaPipeHolisticpipelineintegratesseparatemodels for pose, face and hand components, each of which is optimized for their particular domain. However, because of theirdifferentspecializations,theinputtoonecomponentis notwell-suitedfortheothers.Theposeestimationmodel.
Fig-3
ThevanillaLSTMnetworkhasthreelayers;aninputlayerand a single hidden layer followed by a standard feedforward outputlayer.Theproposedsystemisdesignedtodevelopa real-timesignlanguagedetectorusinga.TensorFlowobject detectionAPIandtrainitthroughtransferlearning.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072
Fig- 4: BuildingamodelpoweredbyLSTMlayers
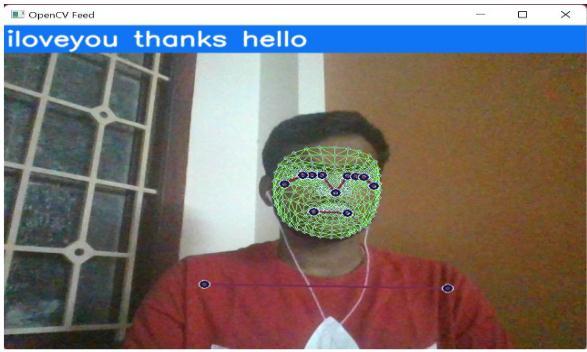
Thesystemmakesreal-timepredictionsofthesignsshown by the user on the camera and appends the labels of the predictionstoasentencebeltonthescreen.Itthenvoices outthepredictionmade.
Chart-1 :Categoricalaccuracygraphs
Fig- 5: Realtimedetectionandprediction
ThereareseveralAPIsavailabletoconverttexttospeechin Python. One such API is the Google Text-to-Speech API commonlyknownasthegTTSAPI.gTTSisaveryeasy-to-use toolwhichconvertsthetextentered,intoaudiowhichcanbe savedasanmp3file.
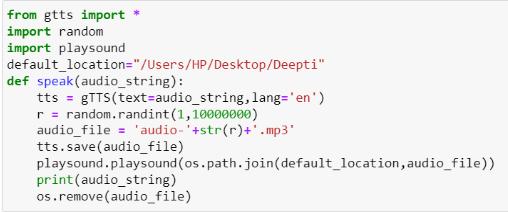
Chart-2 : TrainingLossgraphs
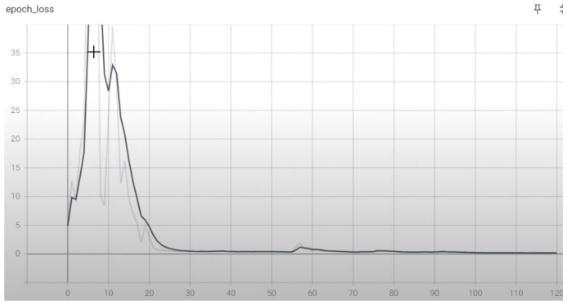
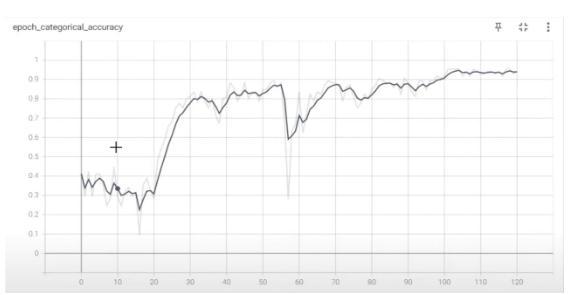
Thetrainedmodelisfoundtobeofanaccuracyof98.2%. Thelossoverthetrainingepochsisfoundtobenearlyzero
Motivations to pursue further research to develop an improvisedversionoftheproposedsystem.Enhancingthe recognition capability under various lighting conditions. Implementingandidentifyingagreaternumberofgestures andatthesametimemaintaininghigheraccuracy.Applying thisgesturerecognitionforaccessinginternetapplications. Weintendtobroadenthescopeofourdomainscenariosand integrateourtrackingsystemwitharangeofhardware,such as digital TV and mobile devices. We want to make this techniqueaccessibletoavarietyofpeople
The model is trained on categorical classification for over 2000epochs
Ourmethod,calledhandgesturerecognition,acknowledged that constructing a database from scratch utilizing video sequences and frames has time constraints and that the process is sensitive to variations in gesture. It is a wellknownissueforhumanitythatsomepeopleareunableto talkorhear.Thetechnologywillprovideauserinterfacethat makes communication . Our method, called hand gesture recognition, acknowledged that constructing a database fromscratchutilizingvideosequencesandframeshastime constraintsandthattheprocessissensitivetovariationsin gesture. It is a well-known issue for humanity that some people are unable to talk or hear. The technology will
2023, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page165
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN: 2395-0072
provide a user interface that makes communicating with people with disabilities straightforward. The Long ShortTermMemoryNetworkhasperformedexceptionallywellat recognizingsignlanguagehandgesturesinvideoclips.The technology recognizes sign language more rapidly and accuratelythanothertechniquesreportedintheliterature. Human-computerinteractionhasseveralpotentialusesfor hand gestures, which are an effective form of human communication. When compared to conventional technologies, vision-based hand gesture recognition algorithms offer several demonstrated advantages. The current work is only a small step towards achieving the outcomesrequiredinthefieldofsignlanguagerecognition, ashandgesturerecognition isa challengingproblem. The chosen hand traits worked well with machine learning techniquesandcouldbeappliedinavarietyofreal-timesign languagerecognitionsystems.Thesystemwillcontinuetobe improved, and trials using full language datasets will be conductedinthefuture.Incaseswherethereisaneedfor trustworthysolutionstotheissueofstartandfinishgesture identification,itisalsoplannedtoevaluatesystemsthatcan read dynamic sign language gestures. The proposed approach is a strong foundation for the creation of any vision-based sign language recognition user interface system, even if there is still more work to be done in this fielding with people with disabilities straightforward. The Long Short-Term Memory Network has performed exceptionally well at recognizing sign language hand gestures in video clips. The technology recognizes sign languagemorerapidlyandaccuratelythanothertechniques reportedintheliterature.Human-computerinteractionhas several potential uses for hand gestures, which are an effectiveformofhumancommunication.Whencomparedto conventional technologies, vision-based hand gesture recognition algorithms offer several demonstrated advantages.Thecurrentworkisonlyasmallsteptowards achievingtheoutcomesrequiredinthefieldofsignlanguage recognition, as hand gesture recognition is a challenging problem.Thechosenhandtraitsworkedwellwithmachine learningtechniquesandcouldbeappliedinavarietyofrealtime sign language recognition systems. The system will continue to be improved, and trials using full language datasets will be conducted in the future. In cases where thereisaneedfortrustworthysolutionstotheissueofstart and finish gesture identification, it is also planned to evaluate systems that can read dynamic sign language gestures.Theproposedapproachisastrongfoundationfor thecreationofanyvision-basedsignlanguagerecognition userinterfacesystem,evenifthereisstillmoreworktobe doneinthisfield.
[1]MaheshKumarN B“Conversionof SignLanguageinto Text“,InternationalJournalofAppliedEngineeringResearch ISSN0973-4562Volume13,Number9(2018)
[2]DeepLearningforSignLanguageRecognition:Current Techniques,Benchmarks,andOpenIssues--MuhammadAlQurishi,,ThariqKhalid,RiadSouissi,IEE,vol9
[3] Muhammad Al-Qurishi , ,Thariq Khalid , Riad Souissi ”Deep Learning for Sign Language Recognition: Current Techniques,Benchmarks,andOpenIssues”,IEE,vol9
[4]SruthiC.JandLijiya A“Signet:ADeepLearningbased Indian Sign Language Recognition System” , 2019 InternationalConference
[5] Yogeshwar Ishwar Rokade , Prashant Jadav “INDIAN SIGN LANGUAGE RECOGNITION SYSTEM”,July 2017 International Journal of Engineering and Technology 9(3S):189-196
[6] Recognition Kartik Shenoy ,TejasDastane Varun Rao , Devendra Vyavaharkar “Real-Time Indian Sign Language (Isl)”,9thICCCNT2018July10-12,2018,IISC,
[7]S.Venkateswarlu,DuvvuriBKKameshDuvvuri,Sastry Jammalamadaka“Text to Speech Conversion “ , October 2016IndianJournalofScienceandTechnology9(38)
[8] Isewon ,JeliliOyelade Olufunke Oladipupo “Design and ImplementationofTextToSpeechConversionforVisually Impaired People Itunuoluwa “,International Journal of AppliedInformationSystems(IJAIS)–ISSNVolume7–No.2, April2014
[9]Al-Jarrah,A.Halawani,“RecognitionofgesturesinArabic sign language using neuro-fuzzy systems,” The Journal of ArtificialIntelligence133(2001)117–138.
[10]Rajam,Subha&Ganesan,Balakrishnan.(2011)“Real timeIndianSignLanguageRecognitionSystemtoaiddeafdumbpeople”,InternationalConferenceonCommunication TechnologyProceedings
[11]GeethaM.,ManjushaU.C.“VisionBasedRecognitionof Indian Sign Language Alphabets and Numerals Using BSpline Approximation”, International Journal of Computer ScienceandEngineering(IJCSE)
[12] PV.V Kishore, P. Rajesh Kumar, E. Kiran Kumar &S.R.C.Kishore, ” Video Audio Interface for Recognizing GesturesofIndianSignLanguage”,InternationalJournalof ImageProcessing(IJIP),Volume5,Issue4,2011
[13] Adithya, V., Vinod, P. R., Gopalakrishnan, U., and Ieee (2013)."ArtificialNeuralNetworkBasedMethodforIndian SignLanguageRecognition."
[14] A Deep Learning-based Indian Sign Language Recognition System , International Journal of Advanced Research in Science, Communication and Technology (IJARSCT)Volume2,Issue2,February2022