International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056

Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
1Assistant Professor, Department of Electronics and Communication Engineering, Sri Venkateswara College of Engineering, Chennai, Tamilnadu, India.
2Student, Department of Electronics and Communication Engineering, Sri Venkateswara College of Engineering, Chennai, Tamilnadu, India.
3Student, Department of Electronics and Communication Engineering, Sri Venkateswara College of Engineering, Chennai, Tamilnadu, India.
4Student, Department of Electronics and Communication Engineering, Sri Venkateswara College of Engineering, Chennai, Tamilnadu, India. ***
Abstract - Numerous people around the world experience various hearing difficulties. A sense of sound is critical for the quality of life of people with hearing difficulties, including deaf people. Wearable devices have substantial potential for sound recognition applications owing to their low cost and lightweight. They can assist deaf and physically impaired people to perform their daily activities more easily without requiring assistance from others. In this present study, A wearable assistive device has been designed and developed for the hearing impaired that informs the users of important sounds through vibrations, thereby understanding what kind of sound it is. The aim is to provide assistance for deaf people who cannot move around easily without any support. The classical Mel-frequency cepstral coefficients (MFCC) are used for feature extraction. Mel Frequency Cepstral Coefficient (MFCC) is for extracting the features from Audio. So overall MFCC technique will generate 13 features from each audio signal sample which are used as input for the Classification model. The performance of three Hidden Markov Model (HMM) models are compared with respect to various parameters and an improved HMM approach is proposed. An ensemble modelling approach is used to combine the three models to improve the accuracy of classification of the environmental sounds. This method is effective, robust, and well-suited for hearing aid applications. The model is deployed on Raspberry Pi which produces the vibration output based on the model prediction.
Keywords: HiddenMarkovModel(HMM),Mel-frequencycepstralcoefficients(MFCC),RaspberryPi,Wearableprocessing, Hearingaid,environmentalsound
The global burden of hearing impairment is estimated at 466 million people (6.1% of the world’s population) where 432million(93%) of these areadults(242 millionmales,190 millionfemales)and34million (7%) children.It is judgedthatthenumberofpeoplewithdeafnesswillgrowto630millionby2030andmaybeover900millionby2050.
Hearing impairment has an important bearing on many aspects of an individual’s life, including their socioeconomicstatus,mental well-being, educationand employmentopportunities. Olderpeoplewithmoderateormore severehearinglossweremorelikelytofeeldepressedandsufferfrompoormentalhealth.Thedeafchildcannotlistento herorhismotherandfocusonan activityatthesametimesincebothinputsmustbeprocessedvisually.Inaddition,the deaf child is unaware of sounds of the outside environment, and thus, is centred on self and own activities. This has consequencesonthechild’sdevelopmentoflanguage,socialskillsandcognition.[1].
Soundisabiometricfeatureusedtodifferencepeopleorspeciesfromoneanother.By filteringanexistingaudio signal, it is possible to detect whether this sound comes from a human or another object. Since voices differ from one person to another, they can be used for voice accolade purposes. It is also possible to power or direct various devices through words obtained from sound signals. Therefore, the processing and use of an audio signal are very important. Hearing is a very important sensory task for people. Developing a device that can perceive and classify various voices at home,andtherebyraisethequalityoflifeforhearingimpairedpeople,isregardedasabasicrequirement.Afirealarmor aphonealertthatwarnsagainstdangeraresomeofthesoundsthatshouldbeperceivedtoencourageurgentaction.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
Peoplewithhearinglosshavestraininhearingandunderstandingspeech.Despitesignificantadvancesinhearing aidsandinnerearimplants,thesedevicesarefrequentlynotenoughtoenableuserstohearandunderstandwhatisbeing communicatedindifferentsettings.Evenwiththelatest technology,hearingaidshavea limited effective range,basically amplifying almost all sounds, and usually can’t separate the background noise from the voices and sounds that the user actuallywantstohear,makingtheusersnotmuchsatisfiedwiththeuseofhearingaids.[2].
1.2.1.
Deteriorationofinnerearstructureshappensovertime.
1.2.2.
Subjectiontoloudsoundswillharmthecellsofyourinnerear.Damagewilloccurwithlong-runsubjectiontoloud noises,orfromabriefblastofnoise,suchasfromagunfire.
1.2.3.
Thegeneticmakeupmaymakeonemoresusceptibletoeardamageduetosoundordeteriorationfromageing.
1.2.4.
Jobswhereloudnoiseisaregularpartoftheworkingenvironment,suchasfarming,constructionorfactorywork, canleadtodamagetotheear.
1.2.5.
Subjection to unstable noises, like from firearms and airplane, may cause immediate and permanent hearing impairment.Otherdistractionactivitieswithhazardouslyhighnoiselevelsincludemotorcycling,listeningtoloudmusic.
1.2.6.
Drugs like sildenafil (Viagra), the antibiotic gentamicin and certain chemotherapy drugs, can damage the inner ear. Temporary effects on hearing ringing in the ear (tinnitus) or hearing loss may occur if very high doses of aspirin, alternativepainrelievers,antimalarialdrugsorloopdiureticsaretaken.
1.2.7.
Diseasesorillnessesthatendinhighfever,suchasmeningitis,canharmthecochlea.
People who are hearing impaired face considerable challenges. They experience and navigate the world very differentlycomparedtothosewhopossessperfecthearing.Togainanunderstandingofthedifficultiestheymayface,ten situationsthatmakelifemorechallengingareshownbelow
1.3.1.
Hearingimpairedpeoplecan’tgraspinformationtransmittedthroughpublicaddresssystems.
1.3.2.
Whensomeonerealizesthey’reinteractingwitha hearing-damagedperson,they usually switchtoaslower kind of speech. Hearing impaired will have learned to understand words when they are spoken naturally, so slowing it down intentionallymayresultinmiscommunication.
1.3.3.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
The absence of light in the surrounding environment makes it difficult for hearing impaired people to interact with others. They generally rely on visual stimuli, such as lip-reading or sign language, so dark environments present a challenge.
When a person is hearing impaired, they won’t hear their name called. That’s why in deaf society, firm but civil tapping on the shoulder is normal in order to gain observation. However, those not familiar with the hearing impaired communitymaybeunawareofthis,leadingtoconfrontation.
Sign language is not universal, and different standards are present in different countries. In addition, regional areashavetheirownspecificvariationssimilartoaccentsorslangcausingadditionaldifficulty.Therearemanyinstances ofprofessionalinterpretersusingthewrongwordsduetothevariationsacrossregionsandcountries;whilethismaynot seemlikeabigdeal,ithasledtolastingharm,suchasinlegalsituationsoraccidentsduringhospitalvisits.
1.4. Comparing loudness of common sounds
Table - 1: ComparingloudnessofcommonSounds
Decibels Noise Source 30 Whisper 40 Refrigerator 60 Normalconversation 75 Dishwasher 85 Heavycitytraffic,Schoolcafeteria 95 Motorcycle 100 Snowmobile 110 Chainsaw 115 Sandblasting 120 Ambulance 140-165 Firecracker
The project is aimed at the development of a wearable assistive device for the hearing impaired that informs the users of important sounds through vibrations, thereby understanding what kind of sound it is. The classical MelFrequency Cepstral Coefficients (MFCC) is used for feature Extraction. The Hidden Markov Model (HMM) approach, GaussianHMMandGMM-HMMareusedtoclassifytheenvironmentalsounds.[3].
In recent years, research, especially on speech data, has gradually increased to meet the demands of the developing world. This is because speech data such as audio and voice data are those that are closest to human life, and they can best express daily life. Recently, study on audio-based systems and deep-learning technologies has improved rapidly.Examplesofsoundsourcesaretrafficnoise.Theoutputdatafromthesoundsourcemodelsarethereforefurther processedbyahierarchicalHMMinordertodeterminethecurrentlisteningenvironment.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page 102
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
Anacousticthumbprintisacondenseddigitalsummary,athumbprint,deterministicallygeneratedfromansound signal,thatcanbeusedtoidentifyansoundsampleorquicklylocatesimilaritemsinansounddatabase.Arobustacoustic fingerprint algorithm must take into account the perceptual characteristics of the sound. If two files sound alike to the humanear,theiracoustic thumbprintsshouldmatch,eveniftheir binaryrepresentationsarequitedifferent. Such sound fingerprintingtechniquescanbeusedtoidentifydifferentvoices.
The classified sound signals can be categorised into classes depending on the nature of sound and the importanceofthesound.Then,the vibrationmotorsendsawarningtotheuser,whichisperceivedthroughthesenseof touch.Foreachtypeofsound,adifferentvibrationstimulusistransmittedtothehearing-impairedpersonsothatdifferent sounds can be identified. Thus, this type of wearable device would be beneficial for the aged, disabled, and hearing impairedpatientswhocanunderstandimmediatelythetypeofrepetitivelyoccurringsoundsintheirdailylifesoeasilyby meansofvibrationswhichtheyfeelintheirskin.[4].
Thedatasetconsistsof1091audiofilesannotatedwith5labels.Allaudiosamplesareprovidedasuncompressed PCM 16-bit, 44.1 kHz mono audio files. The categories are: “Applause”, “Bark”, “Knock”, “Laughter”, “Telephone”. The dataset is created by extracting and restructuring data from the FSDKaggle2018 dataset and the Sound Event Classification(Kaggle)dataset.
Audio signal
preprocessing
Feature Extraction
GMM-HMM 1 Classification Raspberry Pi
Vibratio n motor GMM-HMM 2 Classification Gaussian HMM Classification






The audio signal is observed by the microphone and sent to the Raspberry Pi where pre-processing, feature extraction and classification processes occur. The output is given to the vibration motor corresponding to the predicted class.
The audio signals received are of unequal lengths making classification difficult. So, the audio signals are convertedtoexactly7secondsinlengthwithshorteraudiosignalsrepeateduntilitreachesthe7secondmarkandlonger audiosignalscutshort.
Feature Extraction is performed using Mel Frequency Cepstral Coefficients (MFCC) technique. It represents the audio signal with as a set of 39 cepstral coefficients which concisely describe the overall shape of the spectral envelope. Thefrequencybandsareequallyspacedonthemelscale,whichapproximatestheresponseofthehumanauditorysystem
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
morecloselycomparedtothelinearly-spacedfrequencybandsinthenormalspectrum.Thisfrequencywarpingallowsfor betterdescriptionofaudio
Classification scores are simultaneously calculated using a Gaussian HMM model and 2 GMM-HMM models. The overallmaximumscoreamongthe3modelsisfoundandtheclasscorrespondingtothescoreisthefinalprediction.
TheGaussianhiddenMarkovmodel(GaussianHMM)isatypeoffinite-state-spaceandhomogeneousHMMwhere themeasurementprobabilitydistributionisthenormaldistribution, Yt|St~N(St, St) ......(2.1) where St and St are mean and covariance parameters at state St , St = 1,…,K. Hence, the initial state probability vector (ISPV) , thetransitionprobabilitymatrix(TPM) A,andtheobservationparameter B(≡{I , i} i=1….,K, whichconsists of mean and covariance parameters) together specify the Gaussian HMM; that is, the parameter of the Gaussian HMM is {,A,B}. BecausetheGaussianHMMisatypeoffinite-state-spaceandhomogeneousHMM,thesixcommonproblemslikefiltering, smoothing,forecasting,evaluating,decoding,andlearningproblemscanbesolvedusingthethreealgorithmsfoundinthe sectionHiddenMarkovModel
The GMM can be observed as a mixture between parametric and non- parametric density models. Like a parametricmodel,ithasstructureandparametersthat powertheactionsofdensityinknownways.Likenon-parametric model ithasmanydegrees of releasetoallowarbitrarydensitymodelling.TheGMMdensityis givenasweightedsumof Gaussiandensities: PGM(x)=∑ mg(x, m ,Cm) ……(2.2)
Wm are the component probabilities or weights (∑Wm = 1). The K-dimensional densities so the argument is a vectorx=(x1,...,xK )T.Theg(x,µm,Cm)isaK-dimensionalGaussianProbabilityDensityFunction(PDF). g(x, m ,Cm)=(1/(2)K/2 |Cm|1/2) (x-m)TCm-1(x-m) ……(2.3)
where Cm denotes the covariance matrix and µm denotes the mean vector Now, a Gaussian mixture model probability densityfunctioniscompletelygivenbyaparameterlistby, θ={w1,µ1,C1...w1,µ1,C1}m; m=1…M ……(2.4)
Sorting the data for input to the GMM is weight since the components of GMM play a major role in the creation of word models. For this purpose, The K- Means clustering technique is used to break the data into 256 cluster centroids. These centroidsarethencollectedintosetsof32andthenpassedintoeachcomponentofGMM.Asaresultasetof8components areobtainedforGMM.Oncethecomponentinputsaredecided,theGMMmodellingcanbeimplemented.[5].
The GMM/HMM hybrid model has the power to find the joint maximum probability among all viable reference words W given the sequence O. In real case, the union of the GMMs and the HMMs with a weighted coefficient may be a goodschemebecauseofthevarianceintrainingmethods.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
Raspberry Pi 4 Model B is the new product in the popular Raspberry Pi series of computers. It offers incredible increases in processor speed, multimedia performance, memory, and connectivity compared to the previous generation RaspberryPi3ModelB+,whilestillmaintainingbackwardscompatibilityandhavingsimilarpowerconsumption.Forthe enduser,Pi4ModelBgivesdesktopperformanceequaltotheentry-levelx86PCsystems.

The Raspberry Pi 4 Model B (Pi4B) is the first of the next generation of Raspberry Pi computers supporting additional RAM and having greatly improved GPU, CPU and I/O performance all within a similar power envelope, form factorandcostasthepreviousgenerationRaspberryPi3B+.ThePi4Bisobtainablewith1,2and4GBofLPDDR4SDRAM.
This product’s key details include an improved performance 64-bit quad-core processor, dual-display with resolutionsupto4Kviaapairofmicro-HDMIports,hardwarevideodecodeatupto4Kp60,upto4GBofRAM,dual-band of2.4and5.0GHzwirelessLAN,Bluetooth5.0,GigabitEthernet,USB3.0
The dual-band wireless LAN and Bluetooth have modular compliance certification, allowing the board to be designedintoendproductswithsignificantlyreducedcompliancetesting,thusimprovingbothcostandtimetomarket.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
PossessesQuadcore64-bitARM-CortexA72runningatfrequencyof1.5GHz
Differentoptionpossessing1,2and4GigabyteLPDDR4RAM
H.265(highefficiencyvideocoding)hardwaredecoding(upto4Kp60)
H.264hardwaredecode(upto1080p60)
VideoCoreVI3DGraphics
DualHDMIdisplayoutputupto4Kp60issupported
ARMv8InstructionSet
MatureLinuxsoftwarestack
Activelydevelopedandmaintained
RecentLinuxkernelsupport
Manydriversupstreamed
Stableandwellsupporteduserland
GPUfunctionsusingstandardAPIsareavailable
4.1.3.
802.11b/g/n/acWirelessLAN
Bluetooth5.0withBLE
1xSDCard
2xmicro-HDMIportswhichsupportdualdisplaysupto4Kp60resolution
2xUSB2ports
2xUSB3ports
1xGigabitEthernetport(supportingPoEwithadd-onPoEHAT)
1xRaspberryPiportforcamera(2-laneMIPICSI)
1xRaspberryPiportfordisplay(2-laneMIPIDSI)
28xuserGPIOpinswherevariousinterfaceoptionsaresupported:
Upto6xUART
Upto6xI2C
Upto5xSPI
1xSDIOinterface
1xDPI(ParallelRGBDisplay)
1xPCM
Upto2xPWMchannels
Upto3xGPCLKoutputs
4.1.4.1.
The Pi4B has 28 BCM2711 GPIOs available through a standard Raspberry Pi 40-pin header. It has backwards compatibilitywithallpreviousRaspberryPiboardswitha40-wayheader.
4.1.4.2.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
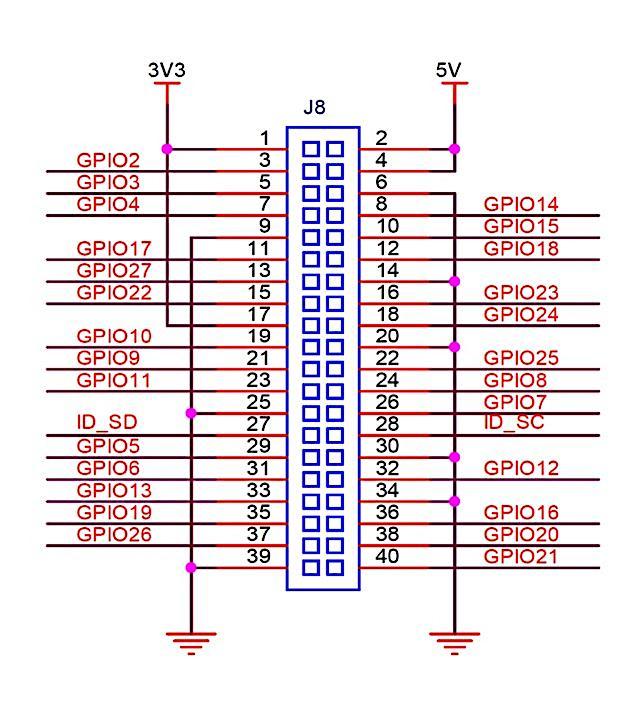
Fig - 3: GPIOConnectorPinout
Other than being capable of being used as straightforward software controlled input and output (with programmablepulls),GPIOpinscanbemultiplexedintovariousothermodesbackedbydedicatedperipheralblockssuch asI2C,UARTandSPI.
ExtraI2C,UARTandSPIperipheralshavebeenaddedtotheBCM2711chip inadditiontothestandardperipheral options found on legacy Pis and are available as further mux options on the Pi4. Much more flexibility is given to users whenattachingadd-onhardwarewhencomparedtooldermodels.
AstandardparallelRGB(DPI)interfaceisavailabletotheGPIOs.Thiscansupportasecondarydisplayup-toa24bitparallelinterface
ThePi4BhasadedicatedSDcardsocketwhichsupports1.8V,DDR50mode(atapeakbandwidthof50Megabytes /sec).AlegacySDIOinterfaceisalsoavailableontheGPIOpins.
ThePi4BhasoneRaspberryPi2-laneMIPICSICameraand oneRaspberryPi2-laneMIPIDSIDisplayconnector. These connectors have backwards compatibility with legacy Raspberry Pi boards, and provide support to all of the availableRaspberryPicameraanddisplayperipherals.
ThePi4BhastwoUSB2and twoUSB3type-Asockets.DownstreamUSBcurrentislimitedtoapproximately1.1A intotaloverthefoursockets.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
The recommended ambient operating temperature range is 0 to 50 degrees Celsius. The Pi4B reduces the CPU clock speed and voltage to reduce thermal output when idling or under light load. The speed and voltage (and hence thermal output) are increased during heavier load. The internal governor will throttle back both the CPU speed and voltagetoensurethattheCPUtemperatureneverexceeds85degreesCelsius.
The Pi4B can operate perfectly well without any extra cooling and is designed for sprint performance, that is, expectinga lightusecaseonaverageandrampingup theCPUspeedas needed. Furthercoolingmay be needed ifa user wishestoloadthesystemcontinuallyoroperateitatahightemperatureatfullperformance.
ThePi4Bhastwomicro-HDMIports,bothofwhichsupportCECandHDMI2.0,withresolutionsupto4Kp60.
The Pi4B supports near-CD-quality analogue audio output and composite TV-output through use of a 4-ring TRS’A/V’jack.Theanalogaudiooutputcanbeusedtodrive32Ohmheadphonesdirectly.
A good quality USB-C power supply capable of delivering 5V at 3A is required. If the attached downstream USB devicesconsumelessthan500mA,a5V,2.5Asupplycanbeused.
Table - 3: AbsoluteMaximumRatings
Symbol Parameter
Minimum Maximum Unit
VIN 5VInputVoltage -0.5 6.0 V
The Mobile Phone Vibration Motor is a shaftless vibration motor that is fully enclosed with no exposed moving parts.Ithasasmallsizeof10mmdiameterand3.4mmheightandcanbemountedontoa PCBorplacedintoapocketto addquiet,hapticfeedbacktoanyproject.[6].
The motor contains a 3M adhesive backing on it for easy mounting and 1.5 inch leads for making quick connections.
Thissmall,button-typevibratingmotorvibrateswithavibrationamplitudeof0.75ganddrawsapproximately60 mAwhen3Visappliedtoitsleads.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072


Ratedvoltage:DC3.0V
WorkingVoltage:DC2.5V–4.0V
WorkingTemperature:-200C–600C
Minimumratedrotatespeed:9000RPM
MaximumRatedcurrent:90mA
Maximumstartingcurrent:120mA
StartingVoltage:DC2.3V
InsulationResistance:10M
Terminalimpedance:31 15%(singleposture),59 15%(doubleposture)
Cablelength:20mm
Amikeisadevicethatusedtotranslatessoundvibrations withintheairintoelectronicsignalsandscribesthem toarecordingmediumoroveraspeakerunit.Microphonesareusedinmanytypesofaudiorecordingdevicesforvarious purposesincludingcommunicationsofmanykinds,aswellasmusicvocals,speechandsoundrecording.
Somefeaturesofthismicrophoneare:
OmnidirectionalmicwithLEDindicator
Noisefiltertoobtaincrispandclearaudio
FrequencyResponse100Hzto10KHz
SampleRate:44.1KHz
CompatibleOS:-WinXP/Vista/7/8/10
Impedance:2.2k
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
Mel-FrequencyCepstralCoefficients(MFCC)andtheirderivativesareusedforfeatureextractiontechniques.This cepstral coefficient is derived in terms of mean and correlation coefficient using MFCC and its derivatives. The preprocessing, feature extraction technique, selection of a feature, feature reduction as well as classification of features are usedforcalculatingtheefficiency.MFCCisthefeatureextractiontechniqueusedinthisproject.
Thefirststepinanyautomaticspeech recognitionsystemistoextract options i.e.identifytheparts oftheaudio signal that are good for recognizing the linguistic content and removing all the unimportant stuff which carries information like emotion, background noise etc. The most purpose to know concerning speech is that the sounds generated by a personality’s square measures filtered by the form of the vocal tract together with the tongue, teeth etc. This shape determines what sound comes out. If one can determine the shape accurately, this should give an accurate representation of the phoneme being produced. The shape of the vocal tract is shown in the envelope of the short-time powerspectrum,MFCCsarerequiredtocorrectlyrepresentthisenvelope.
Mel Frequency Cepstral Coefficients (MFCCs) are widely used automatic speech recognition (ASR). Before the introductionofMFCCs,LinearPredictionCoefficients(LPCs)andLinearPredictionCepstralCoefficients(LPCCs)werethe predominantfeaturetypeforASR,especiallywithHMMclassifiers.
5.2.1.
Windows
Fig - 6: StepsinvolvedinMFCC









DFT Mel Filterbank Log( ) DCT
In this step, the conversion of audio signal from analog to digital format with a sampling frequency of 8kHz or 16kHzisperformed.
5.2.2.
Pre-emphasis significantly increases the magnitude of energy in the higher frequencies. On observing the frequency domain of the audio signal for the voiced segments like vowels, it is observed that the energy at a higher frequencyismuchlesserthantheenergyinlowerfrequencies.Boostingtheenergyinhigherfrequencieswillimprovethe phonemedetectionaccuracytherebyimprovingtheperformanceofthemodel. Thefirstorderhigh-passfilter isusedfor pre-emphasis.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
The MFCC technique aims to develop the features from the audio signal which can be used for detecting the phonemes in the speech. But in the given audio signal there will be many phonemes, so the audio signal is broken into different segments with each segment having 25ms width and with the signal at 10ms apart. On an average, a person speaks three words per second with 4 phonemes and each phoneme will have three states resulting in 36 states per second or 28ms per state which is close to our 25ms window. From each segment, 39 features are extracted. Moreover, while breaking the signal, if the signal is chopped directly at the edges of the signal, the sudden fall in amplitude at the edgeswillproducenoiseinthehigh-frequencydomain.Soinsteadofarectangularwindow,Hanningwindowsareusedto chopthesignalwhichwon’tproducethenoiseinthehigh-frequencyregion.
Framing is the method of blocking the audio signal into frames of “n” samples in the time domain. After the framing step, each individual frame is windowed using the window function. The window function is a mathematical functionthatisusedtominimizesignaldiscontinuitiesatthebeginningandattheendofeachframebytakingtheblockof thenextframeinconsiderationandintegratingallclosetfrequencylines. Thisstepmakestheendofeachframeconnects smoothlywiththebeginningofthenextframeafterthewindowfunctionisapplied.[7].
ThesignalisconvertedfromthetimedomaintothefrequencydomainbyapplyingtheDFTtransform. Analysing audiosignalsiseasierinthefrequencydomainthaninthetimedomain.
X(k)=∑ ;0 k N–1 ......(6.1)
Theperceptionofsoundbyhumanearsisdifferentfromthatofmachines.Humanearshavehigherresolutionat lowerfrequenciescomparedtohigherfrequencies.Soifasoundisheardat200Hzand300Hz, it iseasilydifferentiated by humans when compared to the sounds at 1500 Hz and 1600 Hz even though the difference is the same However, machines have the same resolution at all frequencies. It is noticed that modelling the human hearing property at the featureextractionstagewillimprovetheperformanceofthemodel.So,theMelscaleisusedtomaptheactualfrequency tothefrequencythathumanbeingswillperceive.
Mel(f)=1127ln(1+f/700) ……(6.2)
Filterbankscanbeimplementedinboththetimeandfrequencydomains TocomputetheMFCCcoefficients,the filter banks are usually implemented in the frequency domain. The centre frequencies of the filters are normally evenly spacedonthefrequencyaxis.
Humans are less sensitive to changes in audio signal energy at higher energy compared to lower energy. Log functionalsohasasimilarproperty,atalowvalueofinputxgradientoflogfunctionwillbehigherbutata highvalueof inputgradientvalueisless.SothelogisappliedtotheoutputofMel-filtertomimicthehumanhearingsystem.
Thevocaltractissmooth,therefore,theenergylevelsinadjacentbandstendtobecorrelated.TheDCTisapplied to the transformed Mel frequency coefficients and produces a set of cepstral coefficients. The Mel spectrum is usually representedonalogscalebeforecomputingDCT.Theoutputisasignalinthecepstraldomainwithaque-frequencypeak correspondingtothepitchoftheaudiosignalandanumberofformantsindicatinglowque-frequencypeaks.Sincemostof theaudiosignalinformationisrepresentedbythefirstfewMFCCcoefficients,thesystemcanbemaderobustbyignoring ortruncatinghigherorderDCTcomponentsandextractingonlythosefirstfewcoefficients.
C(n)=∑ 10 (s(m))cos(( ; n=0,1,2,....,C–1 ......(6.3)
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
Where,s(m)islog-energyattheoutputofeachfilter Misthenumberoffilteroutputs
Cepstralcoefficientsarecalledasstaticfeaturessincetheyonlycontaininformationfromagivenframe. Further information regarding the temporal dynamics of the audio signal is obtained by computing the first and second order derivatives of the cepstral coefficients. The first-order derivatives are known as delta coefficients, and the second-order derivatives areknownas delta-delta coefficients.Delta coefficientstell aboutthespeechrate,anddelta-delta coefficients andthesecond-orderderivativeiscalleddelta-deltacoefficients.Deltacoefficientsindicatetheaudiorate,anddelta-delta coefficientsindicatetheaccelerationoftheaudiosignal
Cm(n)=(∑ Cm(n+i))/(∑ ) ......(6.4)
whereCm(n) indicates the mth feature for the nth time frame, Tisthe numberofsuccessiveframesused forcomputation, andki istheith weight.Generally,Tistakenas2.Takingthefirst-orderderivativeofthedeltacoefficientsgivesthedeltadeltacoefficients.Therefore,theMFCCtechniquewillgenerate39featuresfromeachaudiosignalsample Thesefeatures areusedasinputfortheaudiorecognitionmodel.
HiddenMarkovModel(HMM)isastatisticalmodelwherethemodelledsystemisassumedtobeaMarkovprocess withhiddenstates.Ithasasetofstateseachofwhichhaslimitednumberoftransitionsandemissions.
TheHMMis dependent onaugmentingtheMarkovchain.AMarkovchainisamodel providesinformationabout theprobabilitiesofsequencesofrandomvariables andstates,eachofwhichcantakeonvaluesfromaparticularset.The setmay bewords,or tags,orsymbolsrepresenting somethingsuchastheweather. AMarkovchainmakesa verystrong assumption that to predict the future in the sequence, all that matters is the current state. The states before the current statehavenoimpactonthefutureexceptviathecurrentstate.[1]
Fig - 7: AMarkovchainforweathershowingstatesandtransitions.
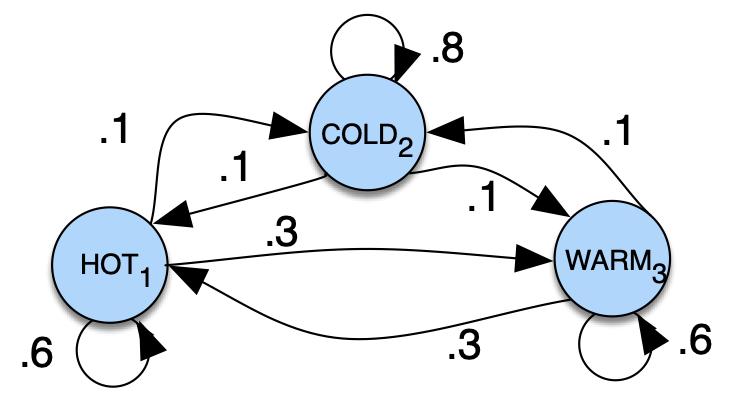
Consider a sequence of state variables q1,q2,...,qi. A Markov model incorporates the Markov assumption on the probabilitiesofthissequence:whenpredictingthefuture,thepastdoesn’tmatter,onlythepresent.
MarkovAssumption:P(qi =a|q1...qi−1)=P(qi =a|qi−1) ……(6.1)
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
Thenodesinthegraphrepresentvariousstatesandtheedgesindicatetransitionsalongwiththeirprobabilities.Sincethe transitionsareprobabilities,thesumofvaluesofarcsleavingagivenstatemustbeequal to1
AMarkovchainisgenerallyusefulwhenthereisaneedtocalculatetheprobabilityforasequenceofobservable events. However, in many cases, the events that one is interested in are hidden: they cannot be observed directly. For example,part-of-speechtagsina text can’t beobserved directly.Rather, the words areseen thetags need to be inferred fromthewordsequence.Thusthetagscanbecalledashiddenbecausetheyarenotobserved.
A hidden Markov model (HMM) incorporates both observed events (like words that are seen in the input) and hiddenevents(likepart-of-speechtags)thatcanbethoughtascausalfactorsinaprobabilisticmodel.
TwosimplifyingassumptionsareusedbyafirstorderHiddenMarkovModel.
First,sameasafirst-orderMarkovchain,theprobabilityofaparticularstateisdependentonlyonthepreviousstate: MarkovAssumption:P(qi|q1...qi−1)=P(qi|qi−1)……(6.2)
Second,theprobabilityoftheoutputobservation oi isdependentonlyonthestatethatproducedthatobservation, qi and notonanyotherstatesorobservations.
OutputIndependence:P(oi|q1 ...qi,...,qT ,o1,...,oi,...,oT )=P(oi|qi)……(6.3)
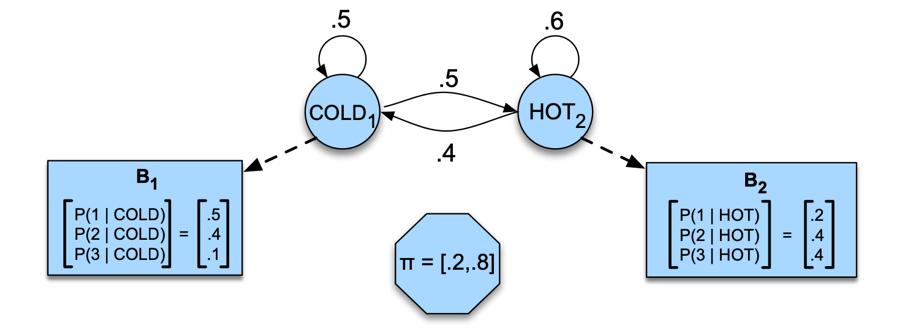
Given a sequence of observations O (where each integer represents the number of ice creams eaten on a given day) , to findthe‘hidden’ sequenceQofweatherstates(HorC)whichcausedTomtoeattheicecream.
Thetwohiddenstates(H andC)indicatehotandcoldweather,andtheobservations(drawnfromthealphabet O={1,2, 3})indicatethenumberoficecreamseatenbyTomonagivenday.
Fig - 8: SampleHMMfortheicecreamtask.
Theperformanceofthe3modelsareanalysedusing2tools:
Classificationreport Confusionmatrix
7.1.1.
Itissoneoftheperformanceevaluationmetricsusedforaclassification-basedmachinelearningmodel.Itshowsa model’s precision, F1 score, recall and support. It gives a better understanding of the overall performance of a trained model.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified
7.1.2.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
Aconfusion matrix or an error matrix is a specific table layout that enables visualization of the performance of the.model.Eachrowofthematrixrepresentstheinstancesofanactualclasswhileeachcolumnrepresentstheinstances ofapredictedclass,orviceversa.Itvisualisesandsummarisestheperformanceofthemodel.
7.1.3. True Positive (TP)
Thesearecaseswherethepredictedclasswascorrect.
7.1.4. True Negative (TN)
Thesearecaseswheretheclasswascorrectlynotpredicted.
7.1.5. False Positive (FP)
Thesearecaseswheretheclasswasincorrectlypredicted.
7.1.6. False Negative (FN)
Thesearecaseswheretheactualclasswasnotpredicted.
7.1.7.
It is defined as the ratio of sum of true positives and true negatives to the total number of predictions. It shows howoftentheclassifierpredictioniscorrect.
Accuracy=(TP+TN)/total ……(7.1)
7.1.8. Precision
Precisioncanbedefinedastheratiooftruepositivestothesumoftrueandfalsepositives. Outofallthepositive predicted,itshowswhatpercentageistrulypositive.
Precision=TP/(TP+FP) ……(7.2)
7.1.9. Recall
Recallcanbedefinedastheratiooftruepositivestothesumoftruepositivesandfalsenegatives
Recall=TP/(TP+FN) ……(7.3)
7.1.10.
Itiscalculatedastheharmonicmeanofrecallandprecision Bothfalsenegativesandfalsepositivesaretakeninto account.Thus,itperformswellonanimbalanceddataset.
F1Score=2*(Precision*Recall)/(Precision+Recall) ……(7.4)
7.1.11.
Supportshowsthenumberofactualoccurrencesofaclassinthedataset.Itdoesn’tdifferbetweenmodels The performance of 3 different HMM models on MFCC features produced from audio data are studied and the classification reports and the confusion matrices for the Gaussian HMM Model and the GMM-HMM models are given below:
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
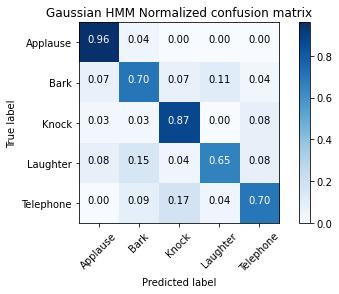
IntheGaussianHMMmodel,thenumberofcomponentsis7.
7.2.1.
Table - 4: GaussianHMMModelClassificationReport. Precision Recall F1-score Support
Applause 0.83 0.96 0.89 25 Bark 0.70 0.70 0.70 27 Knock 0.83 0.87 0.85 39 Laughter 0.81 0.65 0.72 26 Telephone 0.73 0.70 0.71 23
Accuracy 0.79 140 Macro Avg 0.78 0.78 0.78 140 Weighted Avg 0.78 0.79 0.78 140
ItcanbeseenthatPrecisionishighestforApplauseandKnockandlowestforBark. FortheF1-score,ApplausebeingthehighestandBarkthelowestwith0.89 0.70respectively.
7.2.2. Confusion matrix
Fig - 9: GaussianHMMModelConfusionMatrix.
While comparing Recall for various classes, Applause is having the highest value of 0.96 followed by Knock with 0.87, Laughterbeingthelowestwith0.65
InthisGMM-HMMModel,thenumberofcomponents)is7andnumberofmixturesis5.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
7.3.1. Classification report
Table - 5: GMM-HMMModel-1ClassificationReport.
Precision Recall F1-score Support
Applause 0.88 0.92 0.90 25 Bark 0.70 0.70 0.70 27 Knock 0.82 0.85 0.84 39 Laughter 0.82 0.69 0.75 26
Telephone 0.72 0.78 0.75 23
Accuracy 0.79 140 Macro Avg 0.79 0.79 0.79 140
Weighted Avg 0.79 0.79 0.79 140
ItcanbeseenthatPrecisionishighestforApplauseandKnockandlowestforBark. FortheF1-score,ApplauseisthehighestandBarkthelowestwith0.90and0.70respectively.
7.3.2. Confusion matrix
Fig - 10: GMM-HMMModel-1ConfusionMatrix.
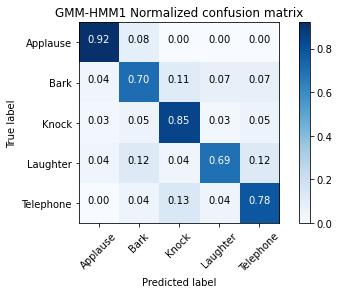
While comparing Recall for various classes, Applause is having the highest value of 0.92 followed by Knock with 0.85, Laughteristhelowestwith0.69.
InthisGMM-HMMModel,thenumberofcomponentsis4andnumberofmixturesis3.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
7.4.1. Classification report
Table - 6: GMM-HMMModel-2ClassificationReport.
Precision Recall F1-score Support
Applause 0.88 0.92 0.90 25 Bark 0.68 0.70 0.69 27 Knock 0.80 0.82 0.81 39 Laughter 0.86 0.69 0.77 26 Telephone 0.72 0.78 0.75 23
Accuracy 0.79 140 Macro Avg 0.79 0.78 0.78 140 Weighted Avg 0.79 0.79 0.79 140
ItcanbeseenthatPrecisionishighestforApplauseandLaughterandlowestforBark. FortheF1-score,ApplauseisthehighestandBarkthelowestwith0.90and0.69respectively.
Fig - 11: GMM-HMMModel-2ConfusionMatrix.
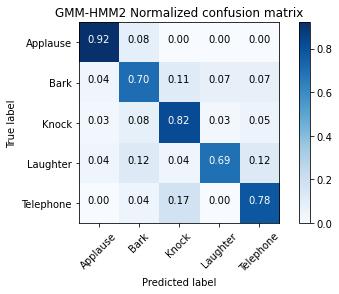
WhilecomparingRecallforvariousclasses,Applauseishavingthehighestvalueof0.92,Laughteristhelowestwith0.69.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
Gaussian HMM GMM-HMM1 GMM-HMM2
Fig - 12: PerformanceofIndividualHMMModelsforDifferentClasses.
AcrossthethreemodelsitisobservedthattheperformanceofthemodelisbestfortheclassApplausewithgood performance for Knock as well. The less complex Gaussian HMM shows similar performance to GMM-HMM for the Applause,BarkandKnockclasseswiththebiggestimprovementoftheGMM-HMMshownfortheTelephoneclass.Thetwo GMM-HMM models with different parameters show minimal difference in performance. All three models show the tendencyto misclassifyTelephonesoundsas Knock sounds. The ensemblemodel combiningthese three modelsensures that even if one of the models predicts the wrong class, the other two models’ predictions are taken into account and so therightclassispredictedmoreoften.
Inthisstudy,theperformanceof3differentHMMmodelsonMFCCfeaturesproducedfromaudiodataare studiedandcomparedandan improvedHMMmodel isproposedbyensemblemodellingthe3models.Theclassification accuracyofthemodeldropssignificantlywhendeployedinareal-timescenarioascomparedtocheckingitsperformance on the Test dataset. This may be due to the external noise. Use of better noise suppression techniques as well as use of noisyaudiosimilartowhat wouldbefoundinthedeploymentenvironment wouldimprovetheperformance. Oneofthe main issues when dealing with audio datasets compared to image datasets is the lack of large quantity of data. Further data collection including collecting relevant audio data directly from the deployment environment to create custom datasets would improve the HMM model’s performance as well as improve the performance of the deep learning approach. In future works, more classes covering all the major indoor sounds can be added for classification to provide comprehensivecoverageoftheindoorenvironmentandtoreducemisclassificationofsoundsnotcoveredbythismodel. Furthermore, better feature extraction techniques including use of deep learning models such as Convolutional Neural Networks(CNN)onmelspectogramsmayimprovetheperformanceoftheHMM.
1. Anders Krogh, “ Two methods for improving performance of an HMM and their application for gene finding”, CenterforbiologicalsequenceAnalysisTechnicalUniversityofDenmark,ISMB-97,2018.
2. Ashish Castellino and Mohan Kameswaran, “Audio-Vestibular neurosensory Prosthetics: Origins, Expanding Indications and future directions, Prosthetics and Orthotics”, Electronics, DOI: 10.5772/intechopen.95592 October2021.
3. D.Clason,"Newdevicehelpshearing-impairedfeelsoundsintheirenvironment",healthyhearing.com,November 23,2020.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 10 Issue: 01 | Jan 2023 www.irjet.net p-ISSN:2395-0072
4. M. Yoganoglu, "Real time wearable speech recognition system for deaf persons," Computers & Electrical Engineering,vol.91,pp.107026,2021.Doi:10.1016/j.compeleceng.2021.107026.
5. P. Nordqvist, "Sound Classification in Hearing Instruments," Doctoral thesis, Royal Institute of Technology, Stockholm,2004.
6. Rashidul Hasan, Mustafa Jamil, Golam Rabbani, Saifur Rahman, Speaker identification using mel frequency cepstralcoefficients.
7. Virender Kadyan, Archana Mantri, “Acoustic Features Optimization For Punjabi Automatic Speech Recognition System”,ChitkaraUniversity,2018.
8. HirakDipakGhaelandL.Solanki,“AReviewPaperonRaspberryPianditsApplications”,ijaem.com,2020.
9. BrankoBalon,“UsingRaspberryPiComputersinEducation”,IEEE,2019.
10. Latifur Rahman and S.A. Fattah, “Smart Glass for Awareness of Important Sound to People with Hearing Disability”,IEEE,2020.
11. MaraimAlnefaie,“SocialandCommunicationAppsfortheDeafandHearingImpaired”,Talfuniversity,2017.
12. MeteYaganoglu,“WearableVibrationBasedComputerInteractionandCommunicationSystemforDeaf”,Applied sciences,2017.
13. Cesar Lozano Diaz, “Augmented Reality System to Promote the Inclusion of Deaf people in Smart Cities”, ISSN, 2019.
14. Linda Kozma spytex, “Factors Affecting the Accessibility of voice Telephony for people with Hearing Loss: Audio Encoding,NetworkImpairments,VideoandEnvironmentalNoise”,GalloudetUniversity,2021.
15. HemanthaKumar,“ContinuousSpeechsegmentationandRecognition”,electronics,2018.
16. Jayabalan Kennedy, “Studies in hidden Markov models and related topics”, Computer and electrical engineering, 2017.
17. M.YoganogluandC.Lose, "Real-timeDetectionofImportantSoundswithaWearableVibrationBasedDevicefor Hearing-ImpairedPeople,"Electronics,vol.7,pp. 50,2018.Doi:10.3390/electronics7040050.
18. LuizW.Biscainho,“MobileSoundRecognitionFortheDeafandHardofHearing”,electronics,2017.