
A Review of deep learning techniques in detection of anomaly incredit card transaction.
Kiran Kumar M 1, Junaid Ahmed S.Y 2, Mohammed Faizan Ghani 3, Husama PM 4 , Mahesh Basavaraj 5Abstract - Creditcardfraudisacommonoccurrencethat causes enormous financial losses. Online purchases have dramatically expanded, and a major portion of those purchases are made using credit cards. As a result, banks and other financial organizations fund the development of software that identify credit card fraud. Fraudulent transactionscanoccurinavarietyofwaysandfallundera number of distinct categories. Credit card firms need to identify fraudulent credit card transactions in order to avoid having their customers’ accounts charged for goods they did not buy. Machine learning and data scienceaid in resolvingtheseproblems.Thelegaltransactionsaremixedin with the fraudulent transactions, so it is impossible to effectively identify the fraudulent transactions using simple identification approaches that compare both the fraudulentand legitimatedata.With the use ofcredit card fraud detection, this research aims to demonstrate the modelling of a knowledge set using machine learning.Our objective is to eliminate erroneous fraud classifications while detecting 100% of fraudulent transactions.A typical categorization sample would be credit card fraud detection. On the PCA converted CreditCard Transaction data,weconcentratedonanalyzingandpre-processingdata sets, as well as deploying numerous anomaly detection techniques such as the Local Outlier Factor and Isolation Forestalgorithm,aswellasoneclassSVM (Support Vector Machine).
Key Words: Credit Card Fraud Detection, Support Vector Machine, Data Science, Local Outlier Factor, and Isolation Forest Algorithm
1.INTRODUCTION
Groups like machine learning and data scienceshould pay attention to this issue because it has the potential to be automatically resolved. This problem is quite challenging from a learning perspective because there are far more legitimate transactions than fraudulent ones. Additionally, overtime,statisticalaspectscausethetransactionpatterns to change often or regularly. With numerous frauds, primarily the majority of people in the world are concernedaboutcreditcardscamsbecausetheyhavebeen inthenewssoregularlyrecently.Thecreditcard database is seriously affected when a legitimate transaction is
contrastedagainst a fraudulent one.Banksare switching to EMV cards, smart cards that store data on integrated circuits rather than magnetic stripes as technology progresses,enablingon-cardtransactions.
1.1 MOTIVATION
Fraudsters have improved their techniques over time in order to evade discovery, along with the technologies used to detect fraud. Even though there are many reported researchontheuseofdataminingmethodologiesforcredit cardfrauddetection,predictivemodelsforcreditcardfraud detectionarestillactivelyusedinpractice.

1.2 OBJECTIVES
Methods for detecting credit card fraud must always be improved. In an effort to better detect credit card fraud,we comparethetwocutting-edgedataminingtechniquesknown assupportvectormachines andrandomforests againstthe well-knownlogisticregression.
1.3 PROBLEM STATEMENT
Financiallossfromfraudisrisingdramatically,whichhasled to a significant increase in credit card scams. Farad LIERTV918070649 causes billions of dollars inlosses per year.Thereisn’tenoughstudytoexaminethefraud.Tofind actual creditcardfraudin the wild,many machine learning techniquesareused.

1.4 Machine Learning Using Python
A smart and popular programming language is Python. Python supports a wide range of libraries, including pandas,NumPy,SciPy,matplotlib,etc.Itsupportsavariety of packages, including Xlsx, Writer, and X1Rd. It isused to conduct complex science very effectively. There are many usefulPythonframeworksavailable.Withthe use of data, machine learning, a subfield of artificial intelligence, enables computer frameworks to learn newabilities and improve their performance. It is used to conduct research on the creation of computer-based algorithms for data prediction.Theprocessofmachinelearningbeginswiththe provision of data, after which the computers are taught using a range of algorithms to produce machine learning models
Table Dataset
ABasicSystemArchitectureofCreditCardFraudDetection Analysis.
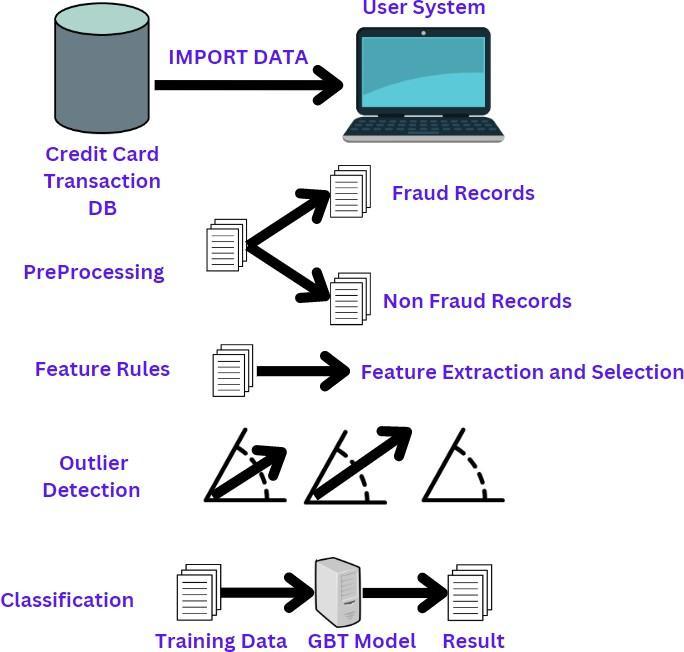
2.1 Credit Card Fraud Detection
As you can see, there does appear to be a correlation between several of our predictors and the class variable. Despitethelargenumberoffactors,thereappeartobe few significantrelationships.
1.SinceaPCA wasusedtopreparethedata,ourpredictors are principal components. 2. Due to the extreme class imbalance, some correlations with respect to our class variablemaynotbeassignificant.
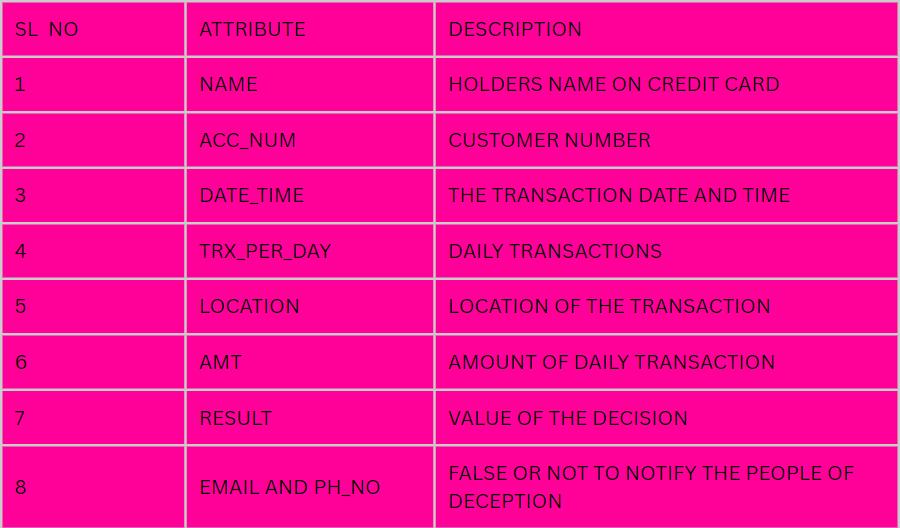
2.2 About dataset
ThefilesincludecreditcardtransactionsdonebyEuropean cardholdersinSeptember2013.Wehave492 frauds outof 284,807transactionsinourdatasetoftransactionsthattook placeoverthecourseoftwodays.
Thedatasetisveryskewed, with frauds making up 0.172% of all transactions in the positive class. It only has numericinput variables that have undergone PCA transformation. Unfortunately, we are unable to offer the original characteristics and additional context for the data due toconfidentiality concerns. The principal components obtained with PCA are features V1, V2,...,V28.Theonlyfeatures that have not been changed with PCA are Timeand Amount. The seconds that passed between eachtransactionandthedatasetsfirsttransaction arelistedinthefeatureTime.
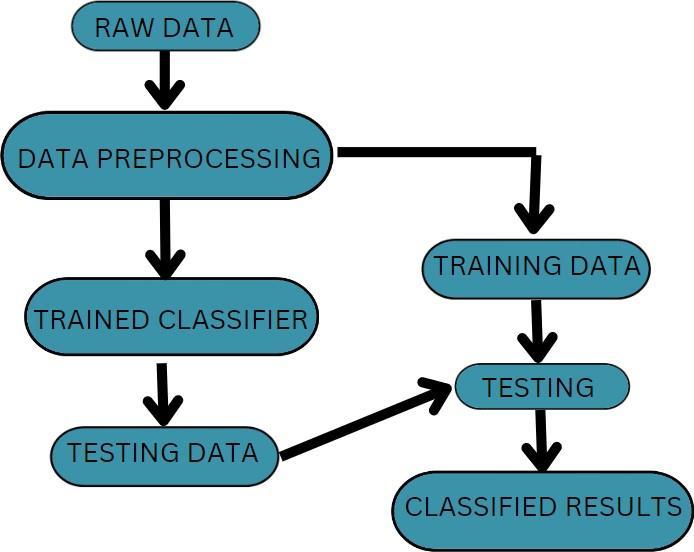
2.3 System Framework
Itillustratesthestepstakentocreatethemodel.Thefigure illustrates the crucial stages that went into creating the suggested model. Following a series of actions like data processing, data cleansing, and feature extraction, classificationisfinallycarriedout.
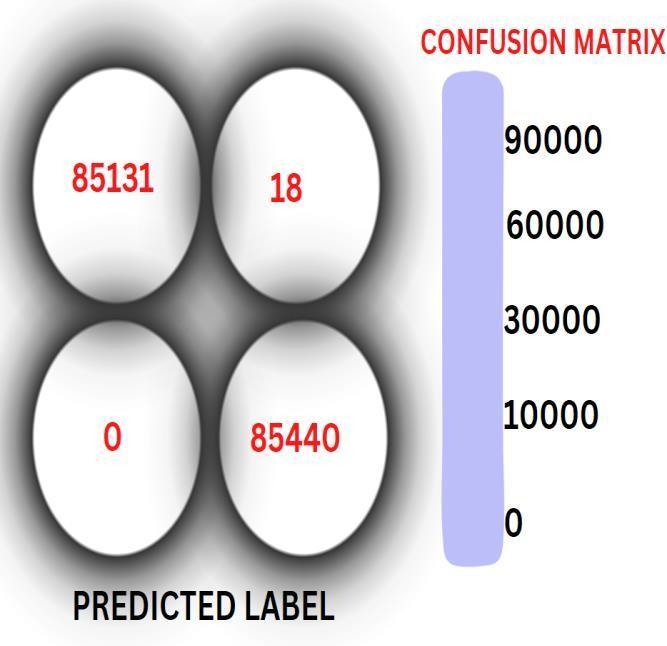
2.4 Results And Discussion
Without a doubt, the Random Forest model outperforms DecisionTrees.However,ifwelookatourdataset,wecansee that there is a significant class imbalance. The numberof legitimate(fraud-free)dealsexceeds99,whilethenumber of fraudulent deals is 0.17. If we train our modelusing a comparabledistributionwithoutconsideringtheimbalance problems, it predicts the label with higher significance assignedtoactualdeals(sincethereismoreevidenceabout them) and so acquires additional fragility. There are a varietyofviablemethodsforresolvingtheclassimbalance issue. One of them is overslicing. After oversampling, the accuracyscoresandtheconfusionmatrixarecalculated.
The Random Forest model performs significantly better than Decision Trees. But our dataset reveals a large class imbalance, as can be seen. There are more than 99 valid (fraud-free) transactions compared to just 0.17 fraudulent transactions. Our model predicts the label with higher importance attributed to actual deals (because there is more data about them) and hence develops additional fragility if we train it using a comparable distribution without taking the imbalance problems into account.There are many effective ways to address the class imbalance problem. One of them is cutting too thin. The accuracy ratings and the confusion matrix are computedfollowing oversampling.
2.5 Future enhancements
The accuracy score for our machine model that detects creditcardtransactionfraudshouldbe100%,with100%as theaim.Butwhenweachieveascoreof100%accuracy,we can deduce that our model is being over- fitted with data, giving us the results for which it has already been trained. Therefore, we can say that the precision and confusion matrixvaluescanbeenhancedwithawiderangeforfuture improvements. ThetransactiondatasetforEuropeancredit card holders canalso be updated with new algorithms, and the results of these algorithms precision and confusion matrices can becombined to get more accurate numbers. The data collection canalso be made better by normalising theextremelyskewednumbersandmatrices.
3 CONCLUSION
The detection of credit card fraud has long been a goal of testing for academics, and it will continue to be an intriguing aspect of testing in the future. By using three different algorithms and training our machine using the transaction information we have, we are launching a fraud detectionsolutionforcreditcards.Withtheaidofthemodel wedeveloped,theauthoritiesarebetterabletoidentifycredit card fraud, investigate it further, and determine if it was a fraudulent or valid transaction. These algorithms tell us whether a given transaction has a tendency to be fraud or not; they were chosen using the feature importance, discussion, and experimentation methods as described in themethodology.
4 ACKNOWLEDGEMENT
Weconsiderourselvesquitefortunatetohavereceived this support over the course of our project because the success andoutcomeofthisprojectrequiredagreatdealofdirection and assistance from many people. We wont forget to thank them for their guidance and support, which are the sole reasons we were able to do what we did. Mr. Puneet Goswami,HeadoftheDepartment,DepartmentofComputer Science and Engineering, and Dr. Paramjit S. Jaswal, ViceChancellor, SRM University, for giving all the necessary resources for the completion of my seminar. Mrs.Ishwari Singh,whoservedasourguide,forherinsightfuladviceand help with the study report. Finally, we would want to expressourgratitudetoeveryone.
5 REFERENCES
[1] Yvan Lucas, Pierre-Edouard Portier, Lea Laporte , Sylvie Calabretto, Liyun He-Guelon, Frederic Oble and MichaelGranitzer,IEEEExplore2019.
[2] Chunzhi, WangYichao, WangZhiwei, YeLingyu , Yuecheng Cai ,The 13th International Conference on ComputerScience&Education.
[3] Addisson Salazar, Gonzalo Safont, Luis Vergara, InternationalConferenceonComputationalScienceand ComputationalIntelligence(CSCI),2019
[4] Anu Maria Babu , Dr. Anju Pratap , IEEE EXPLORE ,2020
[5] Vinod Jain, Mayank Agarwal , Anuj Kumar , International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions)(ICRITO),2020.
[6] FahimehGhobadi,MohsenRohani,ICSPIS,2016.
[7] SP Maniraj , Aditya Saini, Swarna Deep SarkarShadab Ahmed , International Journal of Engineering Research &Technology(IJERT),2019..
[8] AdwaitA.Rajmane,PiyushS.Mahajan,AkshayD.Kolhe, Sandhya S. Khot , International Journal of Engineering Research&Technology(IJERT),2021.
[9] SIMI MJ , International Journal of EngineeringResearch &Technology(IJERT),2019.
[10] Arya Chandorkar , JOURNAL-International Journal of EngineeringResearch&Technology(IJERT),2022.