
Sign Language Detection using Action Recognition
Kavadapu NikhithaComputer Science and Engineering
Sreenidhi Institute Of Science and Technology
Hyderabad, Telanganga, India.
Kota Manish Kumar
Computer Science and Engineering
Sreenidhi Institute Of Science and Technology
Hyderabad, Telanganga, India.
M Yellama
Assistant Professor
Computer Science and Engineering
Sreenidhi Institute Of Science and Technology
Hyderabad, Telanganga, India
Abstract There are learning aids available for those who are deaf or have trouble speaking or hearing, but they are rarely used. Live sign motions would be handled via image processing in the suggested system, which would operate in real-time. Classifiers would then be employed to distinguish between distinct signs, and the translated output would show text. On the set of data, machine learning algorithms will be trained. With the use of effective algorithms, top-notch data sets, and improved sensors, the system aims to enhance the performance of the current system in this area in terms of response time and accuracy. Due to the fact that they solely employ image processing, the current systems can identify movements with considerable latency. In this project, our research aims to create a cognitive system that is sensitive and reliable so that persons with hearing and speech impairments may utilize it in day-to-day applications.
Keywords ImageProcessing,signmotions,sensors, speakingorhearing
I. INTRODUCTION
It can be extremely difficult to talk to persons who have hearing loss. The use of hand gestures in sign language by the deaf and the mute makes it difficult for non-disabled persons to understand what they are saying. As a result, there is a need for systems that can identify various symptoms and notify everyday people of what they mean. Forthedeafanddumb,itisessentialtodevelopspecificsign language applications so they may readily interact with others who do not understand sign language. Our project's main objective is to begin bridging the communication gap between hearing people and deaf and dumb sign language users.Ourresearch'smajorobjectiveistodevelopavisionbased system that can identify sign language motions in action or video sequences. The following was the method
Siddharth Kumar Singh
Computer Science and Engineering
Sreenidhi Institute Of Science and Technology
B Vasundhara Devi
Assistant Professor
Computer Science and Engineering
Sreenidhi Institute Of Science and Technology

Hyderabad, Telanganga, India
Hyderabad, Telanganga, India. ***
used for the sign language gestures: The spatial and temporal characteristics of video sequences. We have used models to learn both temporal and spatial features. The recurrentneuralnetwork'sLSTMmodelwas
II. OBJECTIVES
TheobjectiveofthispaperisthatthegoalofSignLanguage Recognition (SLR) systems is to provide an accurate and efficient means to translate sign language into text or voice for various applications, such as making it possible for youngchildrentoengagewithcomputersbyunderstanding signlanguage.
III. REVIEWOF RELATED LITERATURE
Most of the research in this sector is conducted with a glovebased technique. Sensors like potentiometers, accelerometers, and other devices are mounted to each finger in the glovebased system. The corresponding alphabet is shown in accordance with what they read. A glove-based gesture recognition system created by ChristopherLeeandYangshengXuwasabletorecognise14 of the hand alphabetic letters, learn new gestures, and updatethemodelofeachgestureinthesysteminreal-time. Over time, sophisticated glove technologies like the Sayre Glove, Dexterous Hand Master, and Power Glove have been developed. The primary issue with this glove-based system is that every time a new user logs in, it needs to be calibrated.
IV. METHODS AND RESULTS
Proposed method:
Long short-term memory networks, or LSTMs, are employed in deep learning. Many recurrent neural networks (RNNs) are able to learn long-term dependencies, particularly in tasks involving sequence prediction.
Researchers have created a variety of sign language recognition (SLR) systems, however they are only able to recognise individual sign motions. In this study, we suggestamodifiedlongshort-termmemory(LSTM)model for continuous sequences of gestures, also known as continuous SLR, which can identify a series of linked gestures.
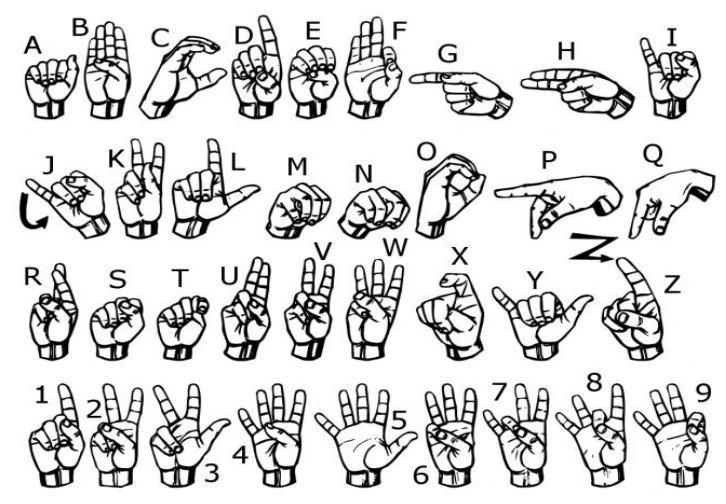
Since LSTM networks can learn long-term dependencies, they were investigated and used for the classification of gesture data. The created model had a 98% classification accuracy for 26 motions, demonstrating the viability of employing LSTMbased neural networks for sign language translation.
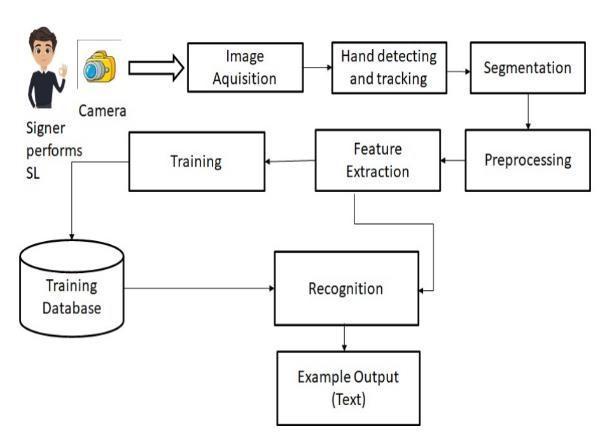
Methodology:
Our suggested system is a sign language recognition system that recognizes a range of motions by recording videoandturningitintoindependentsignlanguagelabels. Handpixelsarethencategorizedandmatchedtoapicture beforebeingcomparedtoatrainedmodel.Asaresult,our algorithm is particularly effective at locating specific character labels. Our suggested system is a sign language recognition system that identifies diverse movements in video recordings and converts them into separate frames. Thehandpixelsarethensplitandmatchedtotheresulting picture before being transmitted for comparison with a trained model, thus our method is quite tight in determining precise text labels for characters. The proposed system includes Collaborative Communication, which enables users to communicate effectively. In order
to overcome language or speech obstacles, the suggested system includes an Embedded Voice Module with a UserFriendly Interface. The main advantage of this suggested system is that it may be utilised for communication by both verbal speakers and sign language users. The proposed system is written in Python and employs the YOLOv5 Algorithm, which includes modules such as a graphical user interface for ease of use, a training module totrainCNNmodels,agesturemodulethatallowsusersto create their own gestures, a word formation module that allowsuserstocreatewordsbycombininggestures,anda speechmodulethatconvertstheconvertedtexttospeech. Oursuggestedapproachisintendedtoalleviatetheissues thatdeafpeopleinIndiaconfront.Thissystemisintended totranslateeachwordthatisreceived.
Fig 2 System Architecture
A. Image Acquisition:
It is the process of removing a picture from a source, usually one that is hardware-based, for image processing. Thehardware-basedsourceforourprojectisWebCamera. Due to the fact that no processing can be done without a picture,itistheinitialstageintheworkflowsequence.The image that is obtained has not undergone any kind of processing.
B. Segmentation:
It is the process of removing objects or signs from the background of a recorded image. The segmentation procedure makes use of edge detection, skin-color detection, and context subtraction. To recognize gestures, the motion and location of the hand must be recognized andsegmented.
C.
Features Extraction:
The preprocessed images are then utilized to extract predefined features such as form, contour, geometrical feature (position, angle, distance, etc.), color feature, histogram, and others that are then used for sign classificationorrecognition.Aphaseinthedimensionality reduction process that separates and organizes a sizable collectionofrawdataiscalledfeatureextraction.Lowered
to more manageable, smallerclasssizes Processing would be easier as a result. The most crucial characteristic of these big data sets is their abundance of variables. A significant amount of computer power is required to process these variables. Function extraction, which choosesandcombinesvariablesintofunctions,enablesthe extractionofthebestfeaturefromenormousdatasets. loweringthedata'ssize.
shown on the screen. The American Sign Language was developedtoassistthesekidsinmanaging theirschooling aswellastomakedailylifeeasierforthem.Toassistthese kids in learning, we came up with a model that would let them make ASL motions to the camera, which would then interpret them and give feedback on what language was understood. To do this, we combined Mediapipe Holistic with OpenCV to determine the essential indicators of the poser with all the values that needed to be collected and trainedontheLongShortTermMemory
4. TextOutput
Recognizing diverse postures and bodily gestures, as well as converting them into text, to better understand human behaviour.
State Chart Diagram:
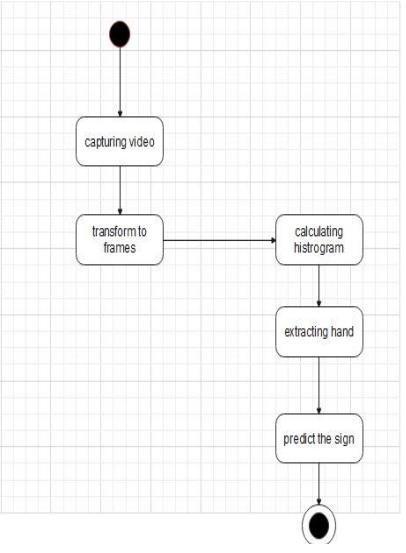
Astatemachinethatillustratesclassbehaviorisdescribed by a state chart diagram. By simulating the life cycle of objectsfrom eachclass,itdepicts the actual state changes rather than the procedures or commands that brought about those changes. It explains how an object transitions between its various states. In the State Chart Diagram, thereareprimarilytwostates:InitialCondition2.Thefinal state. Following are a few of the elements of a state chart diagram:
State:Itisastateorcircumstanceinanobject'slifecyclein whichitmeetsthesamecondition,carriesoutanaction,or waitsforanevent.
Fig3Preprocessing
Thefollowingarethestagesofpreprocessing:
1. Morphological Transform:
An input image's structural feature is used by morphological processes to produce an output image of a similar size. To identify the value of each pixel in the output image, it compares the matching pixel in the input image with its neighbours. Two distinct types of morphologicalchangesexisttheyareDilationandErosion.

2. Blurring:
A low-pass filter applied to an image is an illustration of blur ring. In computer vision, the term "low-pass filter" describes the process of removing noise from an image whileleavingthemajority oftheimageuntouched.Before doing more complex operations, including edge detection, theblurmustbefinished.
3. Recognition:
Childrenwhohavehearinglossareatadisadvantagesince they find it difficult to understand the lectures that are
Transition: A relationship between two states known as a "transition" shows that an object in the first state takes some actions before moving on to the next state or event. An event is a description of a noteworthy occurrence that takesplaceataspecifiedtimeandplace.
V. CONCLUSIONS
Hand gestures, which are a powerful form of communication,haveanumberofpotentialusesinthefield of human computer interaction. There are a number of proven advantages to the method of hand motion recognition utilising vision. Videos are difficult to analyse becausetheyhavebothtemporalandspatialproperties.We have used models to categorise depending on the spatial andtemporaldata.LSTMwasusedtoclassifybasedonboth attributes. If we take into account all the conceivable combinationsofgesturesthatasystemofthiskindneedsto comprehend and translate, sign language recognition is a challengingchallenge.Havingsaidthat,itisperhapsbestto break this difficulty down into smaller difficulties, with the approach provided here serving as a potential solution to one of them. Although the system wasn't very effective, it showedthatafirst-personsignlanguagetranslationsystem could be constructed using only cameras and convolutional neural networks. It was discovered that the model frequently mixed together different signs, including U and W.Butaftersomeconsideration,perhapsitdoesn'tneedto operate flawlessly because applying an orthography corrector or a word predictor will improve translation accuracy. Analyzing the answer and researching ways to enhance the system are the following steps. The vision system may be redesigned, more highquality data could be gathered, and new convolutional neural network architecturescouldbetested.
VI. FUTURE SCOPE
Fortherecognitionofsinglelanguagewordsandsentences, wecancreateamodel.Asystemthatcanrecognisechanges in the temporal space will be needed for this. By creating a comprehensive offering, we can bridge the communication gapforthosewhoaredeaforhardofhearing.
The system's image processing component needs to be enhanced in order for it to be able to communicate in both
directions, i.e., convert spoken language to sign language and vice versa. We'll try to spot any motion-related indicators. Additionally, we'll concentrate on turning the series of motions into text, or words and sentences, and thenturningthattextintoaudiblespeech.
VII. REFRENCES
[1]https://www.google.com/url?sa=t&source=web&rct=j &url
=https://arxiv.org/pdf/2107.13647&ved=2ahUKEwiRuKu FsI3
8AhX3XWwGHe2nAskQFnoECCkQAQ&usg=AOvVaw34S UJaWAK83ZC_C97CLK4p

[2]https://ijrpr.com/uploads/V2ISSUE9/IJRPR1329.pdf