
Classification of Sentiment Analysis on Tweets Based on Techniques from Machine Learning
Anjali Singh1 , Mr.Manish Kumar Soni21M.Tech, Computer Science Engineering, Bansal Institute of Engineering & Technology, Lucknow, India
2 Assistant Professor, Department of Computer Science Engineering, Bansal Institute of Engineering & Technology, Lucknow, India ***

Abstract - This trend is expected to continue growing in popularity. When it comes to making specific choices, the public and the stakeholders might benefit from hearing the thoughts of the people. The process of retrieving information via the use of search engines, online blogs, micro-blogs, Twitter, and social networks is referred to as opinion mining. The user-generated material on Twitter provides a wealth of opportunities to collect the perspectives of people. It is challengingtophysicallydelineatetheinformation duetothe enormous volume of tweets, which are in the form of unstructuredtext.Therefore,tomineandcondensethetweets from the corpora, one has to be knowledgeable in computational techniques and have an understanding of phrasesthatconveyemotions.Theextractionofemotionfrom unstructured text may be accomplished by the use of a wide variety of computer models, methodologies, and algorithms. The vast majority of them are based on machine-learning strategies, with the Bag-of-Words (BoW) representation serving as the primary foundation. In this investigation, we used a lexicon-based technique to automatically identify sentiment for tweets that were gathered from the public domain of Twitter.
Key Words: Bag-of-Words (BoW), Lexicon, Machine Learning Algorithms, Laplace Smoothing, Part-of-Speech (POS)
1. INTRODUCTION
In addition to this, an increasing number of people are turningtotheinternettomakeitpossibleforpeoplelivingin other countries to have access to their point of view. According to the findings of two surveys that were conductedonmorethan 2000adultsin the United States, each eighty percent of Internet users (or sixty percent of Americans)haveconductedresearchonaproductonlineat least once, and twenty percent (fifteen percent of Americans)preferitonaspecificday.Thesestatisticswere derivedfromthefindingsoftwosurveysthatwerecarried out in the United States. The polls were conducted in the United States by two different organizations that are independentofoneanother.TheUnitedStatesofAmerica servedasthelocationforallofthepollingandinterviewing thattookplace.
Ontheotherhand,researchersworkinginthesectorfound the fact that around eighty thousand new blogs and two millionnewarticlesaregeneratedeverysingleday.Because of the widespread use of the internet and the continually shifting behaviorsofcustomers,manyoftheconventional techniquesofmonitoringarebecomingmoreuseless.Asa direct result of this, there is a desire for cutting-edge technologythatisassociatedwithproductphotographsfor quality control. Therefore, in addition to individuals, a separateaudiencegroupforsystemsthatcanautomatically analyzeconsumersentiment,suchasisdescribedinnosmall part in online forums, are businesses that are eager to comprehend how their products and services are being perceivedbycustomersinthemarket.
1.1. Principle of Sentiment Analysis
The source of the opinion, the target of the view, and the evaluativeremarksorcommentsmadebytheopinionholder are the primary components that make up a SA problem. Thesecomponentsarenotlistedinanyparticularsequence. According to Liu [6,] the definition of a SA problem is as follows: "Given a set of evaluative text documents D that containopinions(orsentiments)aboutanobject,Sentiment Analysisaimstoextractattributesandcomponentsofthe objectthathavebeencommentedonineachdocumentd€D and to figure out whether the comments are positive, negative,orneutral."
1.2. Tracking down the Origins of Opinions
The person or medium that is responsible for the transmission of a feeling is considered to be the feeling's "carrier."Thegenesisofafeelingisthepersonormedium that is responsible for its transmission. The genesis of a feeling is of the utmost importance when it comes to validatingandcategorizingthatfeelingsinceitgivescontext tothe emotionintheissue. Thisis becausetheoriginof a positionhasasignificantimpact,bothpositiveandnegative, onthecredibilityanddependabilityofthatviewpoint.Thisis becausetheoriginofaperspectivehasamajorimpactonthe qualityofafeeling,whichisexpressedbythatviewpoint.For instance, the weight of an expert's perspective may be comparedtotheweightoftheopinionoftheaverageperson, and an opinion is considered to be credible when it is receivedfromarespectablesource.
2. COLLECTION AND PREPROCESSING OF DATA
Therapiddevelopmentofcommunicationandinformation technologyhasresultedintheemergenceofanentirelynew set of challenges, which has greatly increased the level of difficulty associated with the process of information dissemination.Onecannotresistemphasizingtherelevance ofsocialnetworkssuchasFacebook,Twitter,andMySpace while discussing the regulations that regulate the transmissionofinformationandthecollectionofbusiness intelligence. Examples of such networks are Facebook, Twitter, and MySpace. Tweets from Twitter were used to ensurethatthebehaviorthatwasthesubjectofthestudy could be maintained. Twitter is unique among social networkingsitesinthateachmessagemaybenolongerthan 140characters.ThischaracterlimitsetsTwitterapartfrom othersocialnetworkingservices.Despitethislimitation,the informationthatisincludedintweetsisofimmensevalue since it is feasible to extract a significant amount of data from such a restricted amount of space. Additionally, the images,videos,andtranscriptsofthepresentationsmayall be seen together in one location, making it feasible to comprehendthewholenarrativeinasinglesitting.Theease ofaccesstothedataisyetanothercrucialfactortotakeinto accountwhilemakingthisdecision.Inthepast,wewereonly abletoputourmodelthroughitspacesusingatrainingset consisting of hundreds of objects. However, now that we have access to the Twitter API, we can gather millions of tweetstoutilizeasdatafortrainingourmodel.Inthepast, wewereonlyabletoputourmodelthroughitspacesusinga trainingsetthathadhundredsofdifferentobjects.
2.1. The Twitter API
WhenusingtheTwitterplatform,usershaveaccesstotwo differentkindsofapplicationprogramminginterfaces(APIs). These APIs are referred to as REST and Streaming respectively.Inaddition,theRESTAPIiscomprisedoftwo moreAPIs,namelytheRESTAPIandtheSearchAPI(whose difference is due to their history of upgradation). The Streaming API, in contrast, to REST APIs, keeps an active connectiontotheserveratalltimesandtransfersdataina manner that is quite close to being in real-time. This differentiatesitfromRESTAPIsinasignificantway.Onthe otherhand,connectionstoRESTAPIswillonlybepermitted iftheyareactiveforacertainperiodandadheretospecified ratelimitations(onecandownloadarestrictedamountof dataperday).UserscanaccessthedatathatTwitterhasto offeratanytimeofthedayornightthankstotheRESTAPIs.
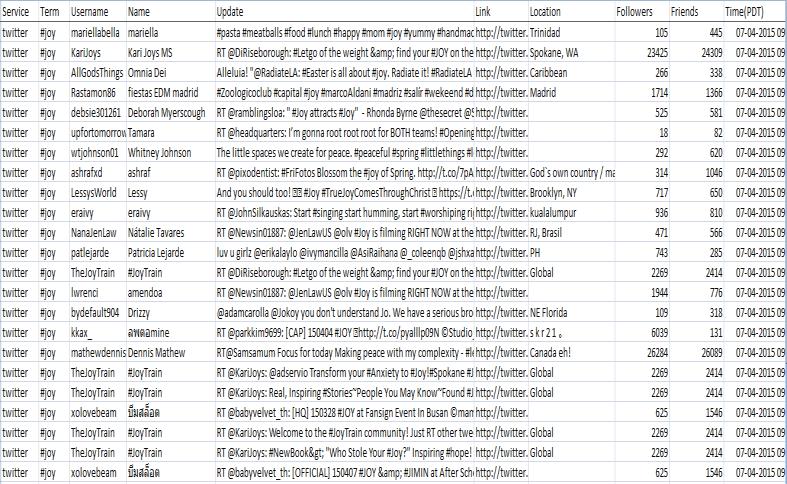
2.2. From Twitter using Third Party API (Twython)
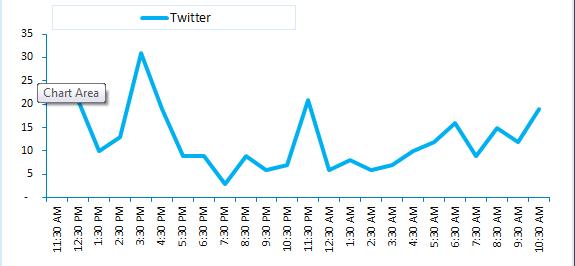
Itisessentialtocollectonlytweetsthatarespecificallyabout thatproductormoviegiventhatthepurposeofthethesisis todeterminethesentiment(positive,negative,orneutral)of tweets about a specific product or a movie, and it is the purposeofthethesistodeterminewhethertweetsaboutthe
productormoviearepositive,negative,orneutral.Thisis because the objective of the thesis is to analyze the sentiments expressed in tweets that are related to the productormovieinquestion.Thisisaresultofthefactthat thepurposeofthethesisistoanalyzethefeelingsthatare expressed in tweets that are relevant to the product or moviethatisunderdiscussion.Havingsaidthat,puttingthis ideaintoeffectwon'tbeaneasytaskbyanystretchofthe imagination.Itwouldseemthatnomethodcanbeemployed tousetocollectallofthetweetsthathavebeenmadeabout acertainsubjectthathasbeendiscussed.
2.3. PREPROCESSING OF DATA
Preprocessing,whichisanessentialphase,isrequiredtoget ridofdatathatiseitherincomplete,noisy,orinconsistent. This is because preprocessing is a crucial step. This is necessaryduetotheneed forpreprocessing.Beforeusing any of the data mining capabilities, it is necessary to do preprocessing in its entirety. This need must be satisfied. Beforeusinganyofthemanymethodsthatareavailableto us for doing sentiment analysis, we first carried out the preprocessingstage,whichwillbediscussedinmoredepth in the following paragraphs (lexicon-based or machine learning).
2.3.1. Removal of the hash symbol
Thereisacertainlabelthatgoesbythenameofahashtag, andyoucanfinditonsocialnetworkingsitesaswellasother kindsofmicrobloggingservices.Thisformoflabelisusedto categorize posts. Users are now in a position to identify messagesthatinvolveacertaintopicmatterorcontentina far more expedient manner than was before feasible as a direct result of these labels. This advancement was previouslyimpossible.Forexample,ifyoudoasearchusing the hashtag #LOST (or #Lost or #lost as the search is not case-sensitive),wewillgetalistoftweetsthatarerelatedto the hashtag #lost. These tweets will include references to #LOST.
3. LEXICON-BASED APPROACH IN SENTIMENT ANALYSIS
Theuseoftermsthatarethoughttobeindicativeofeithera positive or negative bias is taken into consideration to achievethedetectionofsubjectivityandthecategorization ofattitudes.Thisisdonetoaccomplishbothofthesegoals.
Thewayofthinkingthatdrivesthistechniqueisdependent ontheidea thatthemeaningsattributedtowordsmaybe understoodintermsofthesubstanceofviews.Thisthesis servesasthefoundationforthislineofthought.Thecorpus of academic work that has been done in this field has documentedthedeploymentofseveralbeneficialtechniques thatarebasedonthisstrategy.Theseapproacheshavebeen successfulinachievingtheirgoals.Forinstance,Turneyand colleagues [13] provide a method for the identification of subjectivitythatisbasedontheuseofalistofseedwords that is determined by the proximity measure to other commonphrases.
3.1. SentiWordNet
SentiWordNetisalexicalresourcethatwasdevelopedtoaid with activities requiring opinion mining and sentiment analysis [14]. Its purpose was to help with these types of tasks.Itsonlyobjectivewastoassistintheaforementioned endeavors.Anapproachthatisonlysemi-automaticisused to generate SentiWordNet's term-level opinion polarity, whichisprovided tousers. The WordNetdatabase,which containsEnglishwordsandtheirrelationships,isthesource oftheinformationthatwasutilizedtogeneratethispolarity.
3.2. WordNet
WordNetisalexicaldatabasefortheEnglishlanguagethat wasdevelopedatPrincetonUniversitytorealizethenature of semantic relations of terms in the English language. WordNetwasdevelopedasalexicaldatabasefortheEnglish languagebecauseofthepurposeofrealizingtheserelations. Realizing the importance of these connections was the drivingforceforthecreationofWordNet,alexicaldatabase fortheEnglishlanguage.Thedawningunderstandingofthe significanceoftheseassociationsservedastheimpetusfor the development of WordNet, a lexical database designed specificallyfortheEnglishlanguage.
3.3. Tagging of Speech Elements
The display of the information that can be accessed on SentiWordNet is in the hands of the POS, which is responsibleforitsproperorganization.therearesignificant shiftsthatcantakeplaceintheamountofobjectivitythata synsetmayreflectdependingonthegrammaticalfunction thatitplays.Thiscan beseenasa direct result ofthefact thatthereisadirectresultofthis.Whenclassifyingasource text, we need to extract the information on the parts of speech so that we may correctly apply the scores that we have acquired from the SentiWordNet database. This is requiredsothatwecanproperlycategorizethesourcetext.
3.4. PROPOSED MODEL
In the last section of this chapter, the organization of the SentiWordNet database was dissected in great detail, and questionswereraisedaboutthechallengesandconstraints
that are involved with the process of accumulating the required amount of opinion data. By making use of SentiWordNet, we were able to devise a model for the organizationoffeaturesthathavethepotentialtobeusedin thecourseofsentimentanalysis.Thisisthelocationwhere you may find the model. The building of this model was accomplishedwhilekeepingallofthesedifferentissuesin mindatthesametime.However,themethodologyforalist offeaturessuggestedinthissectionbeginsfromtherulethat thefeaturesobtainedthroughSentiWordNetcatchdifferent aspectsoftweetsentimentandarebestsuitedtotrainany classifieralgorithm. Thisruleservesasthefoundationfor the methodology for a list of features suggested in this section. The technique for a list of characteristics that are recommendedinthispartisbuiltontopofthisrule,which actsasthebasis.

4. INTERVENTIONAL SETUP
Figure 6 illustrates the component of our system that we havejudgedtobeofthehighestrelevance,sogoaheadand havealookatit.Aswegoahead,wearegoingtodiscussthis issue in a more in-depth manner, focusing more on the details. To successfully carry out the implementation, we havetakenuseofourdatacollection,whichismadeupof 6000 tweets that have been sorted by hand into several categories.Thecompilation oftweetsincludes talksabout businesses and services like Apple, Google, Microsoft, and Twitter, among others. Positive, negative, neutral, and irrelevantarethefourclassificationsthatmaybeappliedto tweets.Tweetsareconsideredtobeunimportantiftheyare written in a language other than English or if there is no relationship between the tweet and the issue that is the focus of the conversation that is taking place right now. Throughoutourinvestigation,wehaveplacedthemajority ofouremphasisonthreedistinctcategories:thepositive,the negative,andtheneutral.
5. RESULT AND DISCUSSION
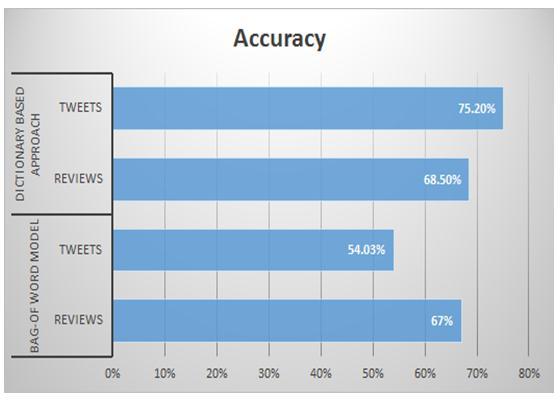
We investigate a wide range of different factors, each of whichisknowntohaveasignificantimpactonthefindings ofsentimentanalysis.WemadeuseofN-gramfeaturessuch as unigrams (n = 1) and bigrams (n = 2), which are used ofteninavarietyoftextclassificationsincludingsentiment analysis.Specifically,weemployedunigramswithn=1and bigrams with n = 2. We have focused specifically on unigramsandbigramsinourwork.Duringourinquiry,we experimentedwithbooleanqualitiesbyusingbothunigrams and bigrams in our work. This allowed us to examine the relationship between the two. Each n-gram feature has a booleanvalueassociatedwithit,whichmaybeturnedonor off according to the user's preferences. This value is only madeto be trueunder the very precise conditionthatthe requiredn-gramcanbelocatedinthetweet[12],whichisa criterionthatmustbemet.
Table 1: F1 rating for the MNB classifier

higher.Thisisbecausethegreatmajorityofthetweetsthat were included in our data collection were manually categorizedastermsthatwereeitherirrelevantorneutral. Thisisthereasonwhythisisthecase.Thereasoningforwhy thingsarethewaytheyaremaybesummedupasfollows: Asadirectresultofthis,touseanyofthemachinelearning methods,wewillneedatrainingdatasetthatisfreefrom any kind of bias and does not call for any kind of human annotation.Thiswillbenecessaryforustobeabletouseany ofthemachinelearningmethods.
5.1. EMOTION DATASET
Hashtags are often used by people as a means of communicatingthethoughtsandfeelingsthatarecurrently goingoninsidetheirminds. Asa consequenceofthis,one may be able to deduce a sufficient number of ideas and feelings from the utterances that include the hashtag. To provideourmachinelearningalgorithmwithmoredata,we haveupgradedittotakeintoconsiderationthesehashtags. Thiswillallowittoprocessmoreinformation.
Figure 7: ROC curve for the MNB tweet classifier
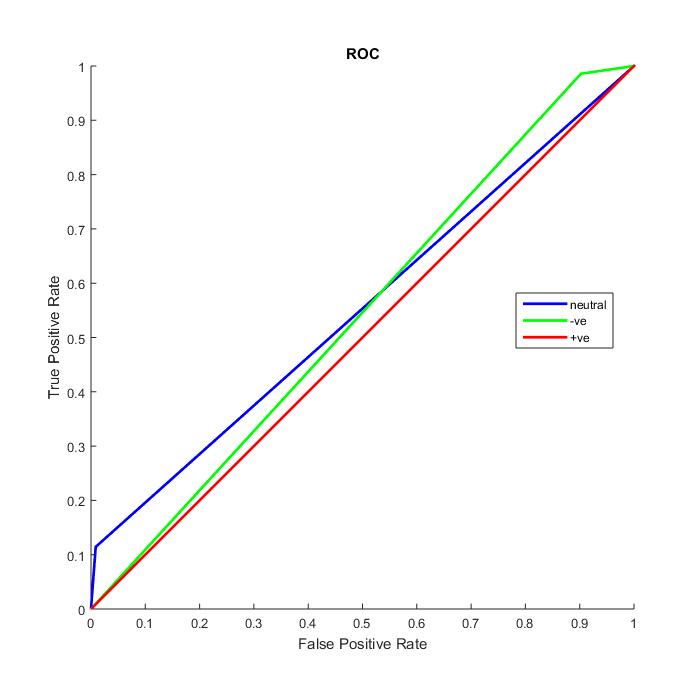
ThefindingsofourresearchindicatethattheF1scorefor thepositiveclassandthenegativeclassismuchlowerthan thescorefortheneutralclass.Ontheotherhand,thescore for the class that was seen as neutral was substantially
6. CONCLUSION
Thisresearchisacademicinthefieldofsentimentanalysis;it focusesontheapplicationoflexicalresourcesandmachine learning algorithms to the problem of classifying the emotionaltoneoftweetsandtextmessages,twoexamplesof unstructured data sources. Due to the abundance of subjective information accessible online, applications of SentimentAnalysis,whichusesanautomatedapproachto
detectsubjectivecontentinatext,maybevaluableinmany sectors,includingonlineadvertisingandmarketresearch.In therealmofknowledgemanagement,thiskindofopinion data is a crucial criterion since it is often the determining factorinmajordecisions.Thereasonwe'redoingthisstudy istolearnmoreaboutthedifficultiesofSentimentAnalysis andthemanyapproachesthathavebeendevelopedtodeal with them. Given the volume and variety of social media data, extracting its underlying sentiment might be challenging.Researchingwhichelementsaremostusefulfor SentimentAnalysis,wepickedtweetsfromthepublicstream andanalyzedthem.Wehavetriedlexicon-basedmethodsas wellasmachine-learningtechniquesforSA.
REFERENCE
[1] John A Horrigan. Online shopping. Pew Internet & AmericanLifeProjectReport,36,2008.
[2] Bing Liu. Sentiment analysis and opinion mining. Synthesis Lectures on Human Language Technologies, 5(1):1–167,2012.
[3]BoPangandLillianLee.Opinionminingandsentiment analysis. Foundations and trends in information retrieval, 2(1-2):1–135,2008.
[4] Bo Pang and Lillian Lee. A sentimental education: Sentimentanalysisusingsubjectivitysummarizationbased on minimum cuts. In Proceedings of the 42nd annual meetingonAssociationforComputationalLinguistics,page 271.AssociationforComputationalLinguistics,2004.
[5]BingLiu.Opinionminingandsentimentanalysis.InWeb DataMining,pages459–526.Springer,2011.
[6]BingLiu.Sentimentanalysisandsubjectivity.Handbook ofnaturallanguageprocessing,2:627–666,2010.
[7] Andr´es Montoyo, Patricio Mart´ıNez-Barco, and AlexandraBalahur.Subjectivityandsentimentanalysis:An overview of the current state of the area and envisaged developments. Decision Support Systems, 53(4):675–679, 2012.
[8]ErikCambria,BjornSchuller,YunqingXia,andCatherine Havasi. New avenues in opinion mining and sentiment analysis.IEEEIntelligentSystems,28(2):15–21,2013.
[9]KhairullahKhan,BaharumBaharudin,AurnagzebKhan, and Ashraf Ullah. Mining opinion components from unstructured reviews: A review. Journal of King Saud University-ComputerandInformationSciences,26(3):258–275,2014.
[10]RonenFeldman,MosheFresko,JacobGoldenberg,Oded Netzer, and Lyle Ungar. Extracting product comparisons fromdiscussionboards.InDataMining,2007.ICDM2007.
SeventhIEEEInternationalConferenceon,pages469–474. IEEE,2007.
[11] Mohammad Sadegh, Roliana Ibrahim, and Zulaiha Ali Othman.Opinionminingandsentimentanalysis:Asurvey. InternationalJournalofComputers&Technology,2(3):171
178,2012.
[12] Bo Pang, Lillian Lee, and Shivakumar Vaithyanathan. Thumbsup?sentimentclassificationusingmachinelearning techniques. In Proceedings of the ACL-02 conference on Empiricalmethodsinnaturallanguageprocessing-Volume 10,pages79–86.AssociationforComputationalLinguistics, 2002.
13]PeterDTurney.Thumbsuporthumbsdown?:semantic orientationappliedtounsupervisedclassificationofreviews. InProceedingsofthe40thannualmeetingonassociationfor computational linguistics, pages 417–424. Association for ComputationalLinguistics,2002.
[14]AndreaEsuliandFabrizioSebastiani.Sentiwordnet:A publicly available lexical resource for opinion mining. In Proceedings of LREC, volume 6, pages 417–422. Citeseer, 2006.
[15] Alaa Hamouda and Mohamed Rohaim. Reviews classificationusingsentiwordnetlexicon.InWorldCongress onComputerScienceandInformationTechnology,2011.
[16] Bruno Ohana. Opinion mining with the sentwordnet lexicalresource.2009.
[17] Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beatrice Santorini. Building a large annotated corpus of english: The penn treebank. Computational linguistics, 19(2):313–330,1993.
[18]DougCutting,JulianKupiec,JanPedersen,andPenelope Sibun.Apractical part-of-speechtagger.InProceedingsof thethirdconferenceonAppliednaturallanguageprocessing, pages133–140.AssociationforComputationalLinguistics, 1992.
[19] Shitanshu Verma and Pushpak Bhattacharyya. Incorporatingsemanticknowledgeforsentimentanalysis. ProceedingsofICON,2009.
[20] Kamal Nigam, John La erty, and Andrew McCallum. Using maximum entropy for text classification In IJCAI-99 workshop on machine learning for information filtering, volume1,pages61–67,1999.
[21]HuifengTang,SongboTan,andXueqiCheng.Asurvey on sentiment detection of reviews. Expert Systems with Applications,36(7):10760–10773,2009.
[22] Daniel M Bikel and Je rey Sorensen. If we want your opinion. In Semantic Computing, 2007. ICSC 2007. InternationalConferenceon,pages493–500.IEEE,2007.
[23] Hiroshi Kanayama and Tetsuya Nasukawa. Fully automaticlexiconexpansionfordomain-orientedsentiment analysis.InProceedingsofthe2006ConferenceonEmpirical Methods in Natural Language Processing, pages 355–363. AssociationforComputationalLinguistics,2006.
[24]MatthiasHagen,MartinPotthast,MichelB¨uchner,and Benno Stein. Twitter sentiment detection via ensemble classificationusingaveragedconfidencescores.InAdvances inInformationRetrieval,pages741–754.Springer,2015.
[25]SaifMMohammad,SvetlanaKiritchenko,andXiaodan Zhu.Nrc-canada:Buildingthestate-of-the-artinsentiment analysisoftweets.2013.
[26] George Miller, Christiane Fellbaum, Randee Tengi, PWakefield,HLangone,andBRHaskell.WordNet.MITPress Cambridge,1998.
[27]GebrekirstosGebremeskel.Sentimentanalysisoftwitter postsaboutnews.SentimentAnalysis.Feb,2011.
[28] I Hemalatha, GP Saradhi Varma, and A Govardhan. Preprocessing the informal text for e cient sentiment analysis.InternationalJournal,2012.