
Diagnosis of Diabetes Mellitus Using Machine Learning Techniques
Mr.P.Bhanu Chand1, M.Lalitha Kavya2, G.SAI SUSHMITHA3, M. KHYATHI SRI4,M. INDIRA51Assistant Professor Department of Information Technology, KKR & KSR Institute Of Technology And Sciences (A), Guntur, India

2,3,4,5Undergraduate Students ,Department of Information Technology , KKR & KSR Institute Of Technology And Sciences (A) ,Guntur, India ***
Abstract - Recently,manyterriblediseaseshaveaffected human health. Many diseases are spreading and causing serious damage to mankind. Advances in technology have proven that most diseases can be cured in the age of medicine, but some diseases can only be prevented and cannot be cured, one of which is diabetes. This article reports on a medical case examining the electronic medical records of diabetics from various sources. Analysis was performed using two data mining classification algorithms: Random Forest and Support VectorMachine.TheperformanceoftheSVMalgorithmis analyzed for different cores available. The best kernel is selected and used for prediction. Random forests are similartobootstrapalgorithmsusingdecisiontreemodels (CART).The purposeof the analysisistopredict diabetes using medical records and compare the accuracy of these two algorithms to find the best diabetes prediction algorithm.
Key Words: Diabetes Mellitus, Support Vector Machine, Gestational diabetes, decision tree, RandomForest.
1. INTRODUCTION
Data mining, usually referred to as knowledge discovery using databases, is the act of locating interesting and valuablerelationshipsandpatternswithinvastamountsof data. Large digital collections, or so-called data sets, require analysis using statistics and AI methods (such as neural networks and machine learning). Data mining is used in a number of sectors, including government security, finance, retail, and science research (astronomy, medical) (detection of criminals and terrorists). Data miningismorecrucialthaneverinthecurrenthealthcare context. Numerous complex reasons (data overload, early illness diagnosis and/or prevention, evidencebased care, and the reduction of hospital mistakes) may be used to promote the use of data mining in the health sector. Noninvasive diagnosis and decision-making, public health policy,andincreasedfinancialefficiencyandcostsavings) In data mining, the disease prediction is significant. Data mining may forecast a variety of illnesses, including
hepatitis, lung cancer, liver disorders, breast cancer, thyroid conditions, diabetes, etc. The Diabetes forecasts are examined in this essay. Diabetes mellitus generally comes in four different forms. They are diabetes of the Type1,Type2,gestational,andcongenitalvarieties.
Diabetes
One of the worst illnesses is diabetes. Obesity, a high glucoselevel,andotherfactorscancausediabetes.Italters thefunctionofthehormoneinsulin,whichcausescrabsto have an irregular metabolism and raises blood sugar levels. When the body does not produce enough insulin, diabetes develops. The term “diabetes”, often known as DiabetesMellitus,referstoagroupofailmentsthataffects howyourbodyconvertsfoodintoenergy
Type 1 Diabetes: If you have Type 1 diabetes, your pancreas either doesn't generate any insulin at all or producesverylittleof it,whichisinsufficienttoallowthe blood sugar to enter your cells and be utilized as energy. As a result, your blood sugar levels are abnormally high. Unusualthirst,frequenturinationortheneedtopee,high levels of weariness, unusual levels of hunger, and other symptoms can all be signs of type 1 diabetes. hazy vision, Lossofweight,woundsorbruisesthathealmoreslowly.
Type2 Diabetes: In most type 2 diabetics, some insulin is typically produced by the pancreas. However, either it is insufficientoryourbodyisnotproperlyusingit.Fat,liver, and muscle cells are typically affected by insulin resistance,whichiswhenyourcellsdon'treacttoinsulin. Type2 diabetes is frequentlymore manageable than type 1.Thetinybloodarteriesinyourkidneys,nerves,andeyes are particularly vulnerable, and it still has the ability to badly impair your health. If you have type 2, your risk of heartdiseaseandstrokerises.
Gestational Diabetes: Insulin resistance is sometimes a side effect of pregnancy. Gestational diabetes is the term usedifthisdevelops.Inlateormiddlepregnancy,doctors frequently detect it. Gestational diabetes must be controlledinordertoprotectthegrowthanddevelopment of the baby since the mother's blood sugar levels are
transferred to the developing child through the placenta. Thebabyismoreatdangerfromgestationaldiabetesthan the mother is. A newborn may have an extraordinary prenatal weight growth, breathing difficulties at delivery, or a higher chance of developing obesity and diabetes in laterlife.Ahugebabymayrequireacaesareansection,or the mother may suffer injuries to her heart, kidney, nerves,andeyes.
Pre-diabetes: Technically, pre-diabetes is not a specific typeofdiabetes.Thesituationisreallyonewhereaperson hasraisedbloodsugarlevelsbutnotquitehighenoughto be classified as having type 2 diabetes. You have a higher riskofdevelopingtype2diabetesandheartdiseaseifyou have pre- diabetes. These hazards can be decreased by increasingyourexerciseandloweringadditionalweight evenonly5%to7%ofyourbodyweight.
The majority of diabetes symptoms are similar in both sexes. Constant thirst, frequent urination, weariness, lightheadedness, and weight loss are some of these basic symptoms. Losses of muscular mass and vaginal thrush are signs that are more frequently seen in males. In addition, women frequently encounter symptoms including polycystic ovarian syndrome, vaginal yeast infections,andurinarytractinfections.Diabetescancause awiderangeofsignificanthealthconsequencesifitisnot properlytreated.Theseincluderenaldisease,amputation, neuropathy, retinopathy, and cardiovascular disease. Due to nerve, muscle, and blood artery damage, erectile dysfunction occurs in 45% of diabetic men. However, heart disease, renal disease, and depression are significantlymorecommoninwomen.Overall,thismakes itfarmoredangerousto women'slivesthanitistomen's lives. Menopause is another challenge faced by diabetic women. Diabetes and this hormonal fluctuation together maycausebloodsugarlevelstoriseevenhigher,weightto gain,andsleepissues.Thus,majordifficultiesmaydevelop further as a result, aggravating earlier health problems. Overall,diabetescanstrikemenatlowerBMIs,alongwith extra issues including erectile dysfunction and loss of muscle mass. The decline in testosterone that occurs in malesastheyageisonepotentialexplanation.
LITERATURE REVIEW
[1] Priyanka Sonar in “Diabetes Prediction Using Machine LearningApproaches”article,usedDecisionTree,Support Vector Machine, Naive Bayes, and ANN. The data set used is the global Data set. The data set has seven sixty-eight instances and nine features. The demo database is the source and the target is a copy of production. The algorithm used for the classification task is Artificial Neural Network, Decision Tree, Support Vector Machine
Classifier, Naive Bayes Classifier, and Machine learning Matrix.SVMisthebestmethodtousewhenwedon'thave any idea about a dataset. Understanding the decision tree will be very easy. Naive Bayes is used to handling the missing values by ignoring estimation calculation. ANN givesgoodpredictionsandiseasytoimplement.
[2] In the article "Performance Analysis of Machine Learning Techniques to Predict Diabetes Mellitus" Md. Faisal Faruque accomplished their objective, the study methodology entails a few stages, including the gathering of a diabetic dataset with the pertinent patient variables, preprocessing the numeric valueattributes,application of various machine learning classification approaches, and corresponding prediction analysis using such data. From MCC, we obtained the data set. The dataset consists of several characteristics or risk factors associated with diabetes mellitus in 200 people. The characteristics are age, sex, weight, polyuria, water intake, and blood pressureateight.Asaresult,weselectedfourwell-known machinelearningalgorithmsforthestudy:SupportVector Machine (SVM), Naive Bayes (NB), and K-Nearest Neighbor (KNN)and, decision tree (DT), on adult populationdatatopredictDiabeticMellitus.
[3]In"ComparisonofMachineLearningAlgorithmsinthe Predicting the Onset of Diabetes," Mahmood ABED published a study. In the suggested technique, many machine learning algorithms were examined for tasks including diabetes diagnosis. Support Vector Machines (SVMs), Linear Discriminant Analysis (LDA), K Nearest Neighbor (KNN), and Classification Naive Bayes (CNB) Classifier are among the techniques employed. They also tookinto account eight key factors:age, body massindex, number of pregnancies, plasma glucose concentration withintwohours,TricepsofSkinFoldThickness,diastolic bloodpressure,andseruminsulinwithintwohours.Since theMATLABMachineLearningToolboxhassomanybuiltin features, including trainer, fitc- nb, fitc- knn, fitc- svm, and fitc- discr, they chose it as the platform for their investigation.
[4] Sudhansh Sharma, Bhavya Sharma, in this article “ EDAS Based Selection of Machine Learning Algorithm Based On Diabetes Detection”. Outliers are handled using the winsorization technique. Class-wise mean is the best technique for comparing the data sets than any other technique.TheproposedSystemcontainsadatasetthatis dividedintotenparts.Inndatasets,onedatasetisusedfor testing and the remaining nine are used for training. The performanceiscomparedwithvariousmethodsbasedon: Accuracy,Sensitivity,andSpecificity.Thedatasetistested with various algorithms: Naive Bayes, Support Vector
machines, and LR. The classifiers are applied to data sets. Thisapproachisquitesuccessful.
[5]In the article “IntelligibleSupportVectorMachinesfor DiagnosisofDiabetesMellitus”,NahlaHBharakat,Andrew PBradley Support VectorMachineis used in this method. The linear hyperplane divides negative and positive data sets. Pre Pruning techniques are used to prune the data.SVM is tested by labeled data. The data is collected from different people of different ages, gender, different BMI, Blood pressure, Glucose level before eating, and Glucoselevelsafterfasting. Todetermine if the difference in AUC between the SQRexSVM and the eclectic approachesisstatisticallysignificant,alargesamplez-test was performed. a hypothesis shows that there is no difference in measured AUC between the two approaches cannotberejected(p>0.05).Furthermore,thedifferences inAUC betweentheSVMandthoseofthe eclecticandthe SQRex-SVM approaches are not statistically significant (p >0.05).
[6]Prabhu,S.Selvabharathiinthemanuscript"Deepbelief neuralnetworkModelforPredictionofDiabetesMellitus", has three phases. The three phases are Preprocess, Pretraining, and fine training. Before we process we need a Diabetes data set. After the data set is taken it will pass through three phases.Itusesmin and max normalization. DBN network is constructed. Data sets are trained using theDBMnetwork.Asthenext step,theywillbevalidated. NN-FF classification is applied to the data set. Randomly initialize all weights and biases in the network. Check for errors. Resolve those errors if there are. It gives output effectively.Here weusedtwovaluesTPandFN. The false negativeisFN,whereasthegenuinepositiveisTP.
[7] "Early prediction of Diabetes Mellitus using Machine learning", GauravTripathi, Rakesh Kumar, In this classification is mainly used in different platforms like pattern recognition, it can classifies the data in to many number of classes. To build a model there is a procedure, we need to follow those procedure ,The procedures were Dataset, Data pre-processing, Algorithms used in this predictive analysis is linear discriminant analysis, knearestneighbor,Supportvectormachine,Randomforest. Inthis weusedpima Indian Diabetes Database. Thereare many divergences occurred those are removed by preprocessinganditcankeepthedatasetclean.Inthisweuse fouralgorithmstoprepareamodel, thosefouralgorithms helpustopredictthediabetes.Thebestsuitablemethodis Random forest because it gives appropriate accuracy results.
[8] In this they have taken nearly 7 major steps for implementing their algorithm, namely Preprocess the
input dataset for diabetes disease in WEKA tool, Perform percentage split of 70% to divide dataset as Training set and Test set, Select the machine learning algorithm i.e, NaiveBayes,SupportVectorMachine,RandomForestand Simple CART algorithm, Build the classifier model for the mentioned machine learning algorithm based on training set, Test the Classifier model for the mentioned machine learningalgorithmbasedontestset,PerformComparison Evaluation of the experimental performance results obtained for each classifier. Determine the highest performing algorithm after analysis based on various metrics. The proposed classifier model has been built using WEKA tool and based on successful execution of eachstepwecangivetheexperimentalresults.Forgiving theaccurateresultstheyareusingconfusionmatrixwhich includes Actual Class, Predicted Class, True-Positive, FalsePositive, True-Negative. At last by using four classifiers Naive Bayes, Support Vector Machine, Random ForestandSimpleCARTtopredicttheresults
2. SYSTEM REQUIREMENTS SPECIFICATION
Software Requirements
∙OperatingSystem:WindowsOS
Libraries: Keras, Tensor Flow, Numpy, ScikitLearn, Matplotlib,OpenCV
Editor:ColabNotebook
∙ Technologies:Python
Hardware Requirements
∙Processor:i3
RAM:4GB
∙ Hard-disk:100GBandabove
Functional Requirements
Python3.6.2orlater,PIP,andNumPyforWindows
Pip
∙ Numpy
Pandas
∙ Anaconda
∙ JupyterNotebook
3. METHODOLOGY
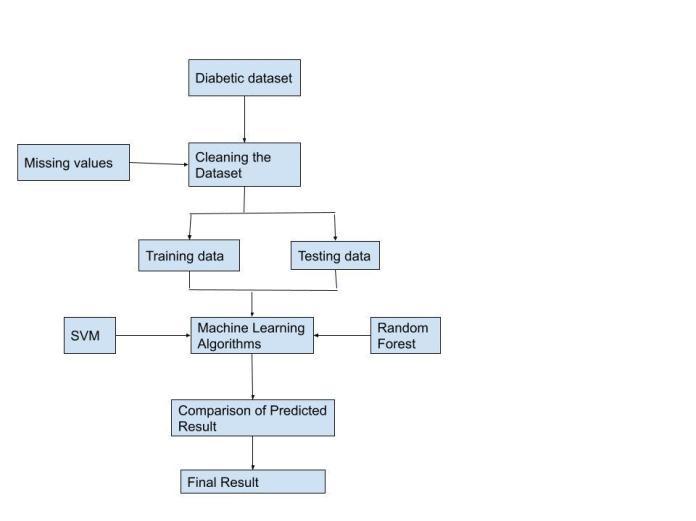
The proposed procedure is divided into various stages andeachstageisexplainedindetail.
∙Datasetasinput
Cleaningthedataset
SplittingDataforTrainingandTesting
∙PredictthediabetesusingMachineLearningTechniques
Compareandgetfinaloutput
The notion of machine learning has swiftly gained popularity in the healthcare business. Predictions and analysesproducedbytheresearchcommunityonmedical data sets aid in illness prevention by guiding proper treatment and safeguards. Machine learning algorithms are the sorts of algorithms that can assist in decision making and prediction. We also explore several machine learning applications in the medical industry, with an emphasis on diabetes prediction using machine learning. It is likely that models trained on the same data will perform poorly in real-world scenarios because they will be over-fitted. In order to avoid this problem, it is necessary to divide the data into two parts: a training set andatestset.Normalpracticeisan80/20split.Inthis,we used the train test split() method from the scikit-learn packagetodividethedatasetintotrainingandtestingsets. 0.2isthespecifiedsamplesize.
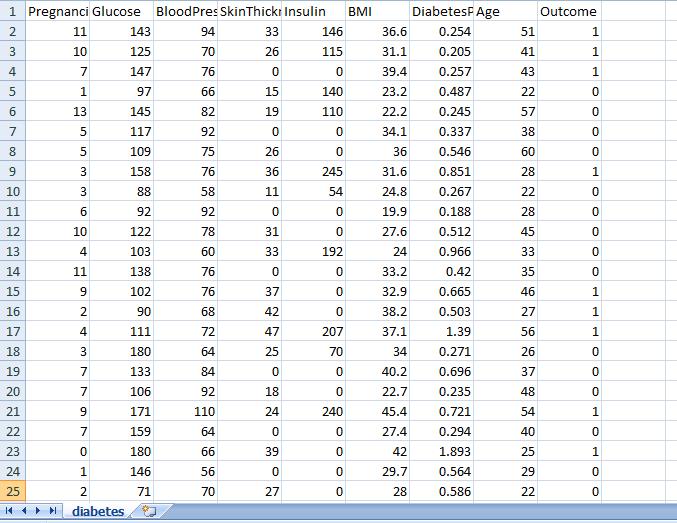
Theinputdatasetindiabetescontainsthefollowingfields: Pregnancy-Thetotalnumberofpregnancies,Glucose-A2hour oral glucose tolerance test's plasma glucose levels, blood pressure or diastolic blood pressure (mm Hg),
Thickness of the triceps skin fold ( mm), Insulin- 2-hour serum insulin (mu U/ml), BMI- body mass index (weight in kg/(height in m)2), and other terms as applicable. diabetespedigreefunctioninyears:(years),Classvariable asaresult(0or1).
TheDatasetofdiabeticpatients:
Diabetesdataset
Theresultisachievedinthefollowingsteps:
● Readthediabetesdataset
● Thestructuraldataofthedatasetwereexaminedusing exploratory data analysis. The dataset's variable kinds were investigated. The dataset's size information was obtained.Thedataset's0valuesrepresentmissingvalues. These0valueswereprimarilychangedtoNaNvalues.The dataset'sdescriptivestatisticswerelookedat.
● Section 3 of data preprocessing; df for The median values of whether each variable was unwell or not were usedtoNaNvaluesformissingdatashouldbefilledin.The LOF identified the outliers and eliminated them. The robusttechniquewasusedtonormalisetheXvariables.
● Cross Validation Score was determined during Model Building utilising machine learning models such as Logistic Regression, KNN, SVM, CART, Random Forests, XGBoost, and LightGBM. Later hyperparameter modificationsto RandomForests, XGBoost, and LightGBM designedtoboostCrossValidationvalue
● The prediction of diabetes is resulted accurately by random forest algorithm. The final output is attained by comparingtheallmethodologies.
Algorithmsused:
a) Support Vector Machine
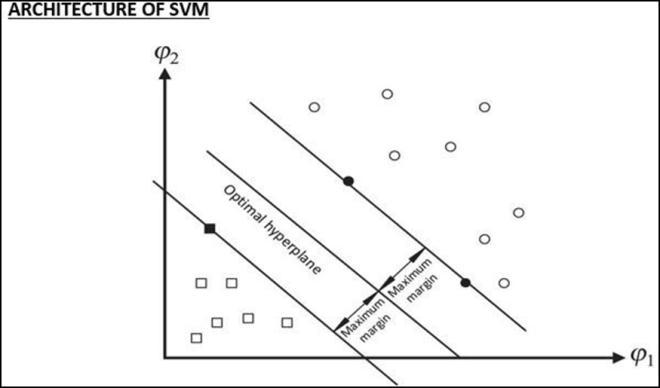
AmethodofsupervisedmachinelearningcalledaSupport Vector Machine (SVM) can be used to solve classification and regression problems. The majority of its applications come from classification problems. As part of this algorithm, each data item is plotted as a point in ndimensional space (where n represents how many features you have) with each feature's value being the coordinate value. Then, we perform classification by findingthehyper-planethat differentiatesthetwoclasses very well (look at the figure below). Kernels are used in practice to implement the SVM algorithm. In linear SVM, hyper-planes are learned using linear algebra, which is beyond the scope of this introduction. A powerful insight is that linear SVM can be rephrased by taking the inner product of any two given observations, rather than the observations themselves. The inner product between two vectors is the sum of the multiplication of each pair of input values. The equation for predicting a new input using the dot product between the input (x) and each supportvector(xi)iscalculatedasfollows:
forecast. Some decision trees may predict the proper output, while others may not, since the random forest mixes numerous trees to forecast the class of the dataset. But when all the trees are combined, they forecast the rightresult.Incomparisontootheralgorithms,itrequires less training time. Even with the enormous dataset, it operates effectively and predicts the outcome with a high degree of accuracy. Accuracy can be kept even when a sizableportionofthedataismissing.
4. RESULT
Fig3: SupportVectorMachine
b) Random Forest
Now that computing power has increased, we may select algorithms that carry out extremely complex calculations. The algorithm "Random Forest" is one example. With a decision tree (CART) model, random forest is comparable to a bootstrapping process. Let's say that there are 1000 observations in the entire population across 10 variables. With various samples and various beginning factors, Random Forest attempts to construct several CART models.ACARTmodel,forinstance,willrequirearandom sample of 100 observations and 5 randomly selected beginning variables. After doing the procedure, let's say, ten times, it will generate a final forecast based on each observation. Each forecast influences the final one. The mean of all previous predictions can be used as the final
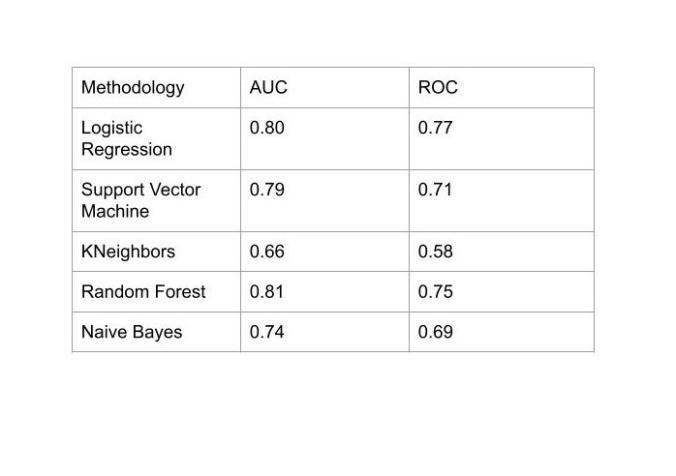
Fig3: Graphicalrepresentationofoutcomes
Therandomforestmethodyieldsthemostaccurateresult. The graph displays the general effectiveness of every strategy on the same set of data. Due to the lack of data, Logistic Regression and Naive Bayes have relatively low prediction rates. When the data is missing, the prediction is inaccurate. Random forest achieves the ultimate high prediction rate because it retains good accuracy even whenasignificantamountofthedataismissing.
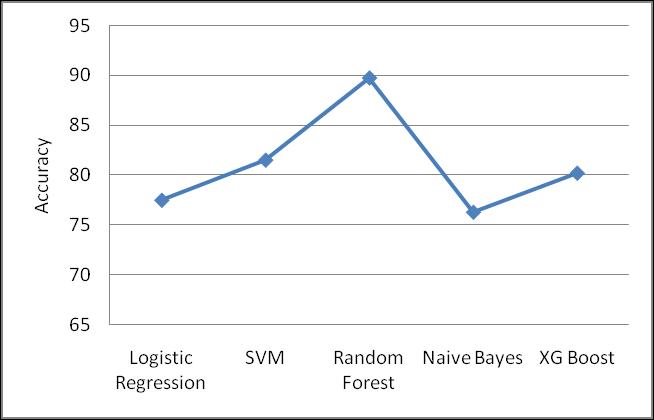
The proposed approach built in python and make use of various classification and ensemble algorithms. These technique are common Machine Learning techniques usedc to get the maximum accuracy out of data. We can see from the competition. Overall,makepredictions and achieve high performance accuracy, we applied thebest machine learning approaches. The outcome of these machinelearningtechniquesisshowninFigure.
5. CONCLUSION
Machine learning algorithms and data mining algorithms inthemedicalfieldcanidentifyhiddenpatternsinmedical data. The systems can be used to analyze critical clinical parameters, predict diseases, forecast medical tasks, extractmedical knowledge, support therapy planningand maintain patient records. There have been several algorithms proposed for predicting and diagnosing diabetes. These algorithms provide more accuracy than the available traditional systems. We tried and optimized every algorithm and we found the RANDOM FOREST algorithm to be the most suitable for over applications. Futureresearchmayinvolvethepredictionordiagnosisof other diseases that use the developed system and the machine learning classification methods. Other machine learning algorithms can be added to the work to improve andexpanditfortheautomationofdiabetesanalysis.
6. REFERENCES
[1] P. Sonar and K. JayaMalini, "Diabetes Prediction Using Different Machine Learning Approaches," 2019 3rd International Conference on Computing Methodologies andCommunication(ICCMC),Erode,India,2019, pp.367371,doi:10.1109/ICCMC.2019.8819841.
[2] M. F. Faruque, Asaduzzaman and I. H. Sarker, "PerformanceAnalysisofMachineLearningTechniquesto Predict Diabetes Mellitus," 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox'sBazar, Bangladesh, 2019, pp. 1-4, doi: 10.1109/ECACE.2019.8679365.
[3]M.Abed and T.İbrıkçı,"Comparisonbetween Machine Learning Algorithms in the Predicting the Onset of Diabetes," 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 2019,pp.1-5,doi:10.1109/IDAP.2019.8875965.
[4]S.Sharma,"EDASBasedSelectionofMachineLearning Algorithm for Diabetes Detection," 9th International Conference System Modeling and Advancement in Research Trends (SMART) 2020, Moradabad, India, 2020, pp.240-244,doi:10.1109/SMART50582.2020.9337118.
[5] N. Barakat, A. P. Bradley and M. N. H. Barakat, "Intelligible Support Vector Machines for Diagnosis of Diabetes Mellitus," in IEEE Transactions on Information Technology in Biomedicine, vol. 14, no. 4, pp. 1114-1120, July2010,doi:10.1109/TITB.2009.2039485.
[6] P. Prabhu and S. Selvabharathi, "Deep Belief Neural Network Model for Prediction of Diabetes Mellitus," 2019 3rd International Conference on Imaging, Signal ProcessingandCommunication(ICISPC),Singapore,2019, pp. 138-142, doi: 10.1109/ICISPC.2019.8935838. [7] G. Tripathi and R. Kumar, "Early Prediction of Diabetes Mellitus Using Machine Learning," 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 2020, pp. 1009-1014, doi: 10.1109/ICRITO48877.2020.9197832.
[8] A. Mir and S. N. Dhage, "Diabetes Disease Prediction Using Machine Learning on Big Data of Healthcare," 2018 Fourth International Conference on Computing CommunicationControlandAutomation(ICCUBEA),Pune, India, 2018, pp.1-6, doi: 10.1109/ICCUBEA.2018 .8697439.
[9] S. Sivaranjani, S. Ananya, J. Aravinth and R. Karthika, "Diabetes Prediction using Machine Learning Algorithms with Feature Selection and Dimensionality Reduction," 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 2021, pp. 141-146, doi: 10.1109/ICACCS51430.2021.
[10]C.Huang,G.Jiang,Z.ChenandS.Chen,"Theresearch on evaluation of diabetes metabolic function based on Support Vector Machine," 2010 3rd International Conference on Biomedical Engineering and Informatics, Yantai, China, 2010, pp. 634-638, doi: 10.1109/BMEI.2010.5640041.
[11]R. Deoand S. Panigrahi,"PerformanceAssessment of Machine Learning Based Models for Diabetes Prediction," 2019 IEEE Healthcare Innovations and Point of Care Technologies, (HI-POCT), Bethesda, MD, USA, 2019, pp. 147-150,doi:10.1109/HI-POCT45284.2019.8962811.
[12]M.Ayad,H.KanaanandM.Ayache,"DiabetesDisease Prediction Using Artificial Intelligence," 2020 21st InternationalArabConferenceonInformationTechnology (ACIT), Giza, Egypt, 2020, pp. 1-6, doi: 10.1109/ACIT50332.2020.9300066.