14 minute read
Assessing Security of Twitter by Sentimental Analysis using Deep Learning


Abstract: In order to make an approximation that is as accurate as feasible, sentiment analysis or opinion analysis is essential. Given that thoughtfully designed and carried out sentiment analysis can produce better and more accurate projections in both politics and business, this is a very essential component. At its most fundamental, feeling Analysis is based on the views that users and individuals share or express.There is a vast amount of material posted and exchanged over the internet every day by the users on various platforms. Understanding how different products, services, political figures, businesses, governments, and other entities are considered and perceived could be gained by being able to find the pattern in such data. This can handle a range of challenges, including being more reliable.Although we have numerous methods for sentiment analysis, a successful plan for regularly extracting and producing reliable sentiment analysis needs to be constructed. Despite the fact that machine learning algorithms have significantly improved Naive Bayes, Support Vector Machine, and Maximum Entropy are the three that stand out as being particularly popular techniques for analysis, including good and bad views,is very much under study.
I. INTRODUCTION
Advertisement
Sentiment analysis divides and separates different emotions in a text.Tweets have a massive data that can be categorized in different ways. These stats allows us to conclude people’s view and opinions. Therefore, we need to create an automated machine learning sentiment analysis model. Modeling them is difficult because they have both useful and unhelpful qualities
We created a machine learning pipeline to assess Twitter sentiment utilizing machine learning, the sentiment of the tweets provided from the dataset, and three classifiers (Logistic Regression, Bernoulli Naive Bayes, and SVM) in addition to Term FrequencyInverse Document Frequency (TF-IDF). The accuracy and F1 Scores of these classifiers are then used to evaluate their efficacy. In this study, we try to apply an NLP Twitter sentiment analysis model that helps in overcoming the challenges of figuring out the feelings of the tweets. For the dataset utilized in the Twitter sentiment analysis project, the following details are required:
The 1,600,000 tweets in the Sentiment140 Dataset, were obtained by using the Twitter API. The several columns in the dataset include:
1) Target: the polarity of the tweet (positive or negative)
2) Ids: the text date, which serves as a special identification number.
3) Flag: It makes a hint about the query. If there is no such question, there is none.
4) User: It mentions the user whose handle posted the following tweet: Referring to the tweet's
II. SENTIMENT CLASSIFICATION METHODS
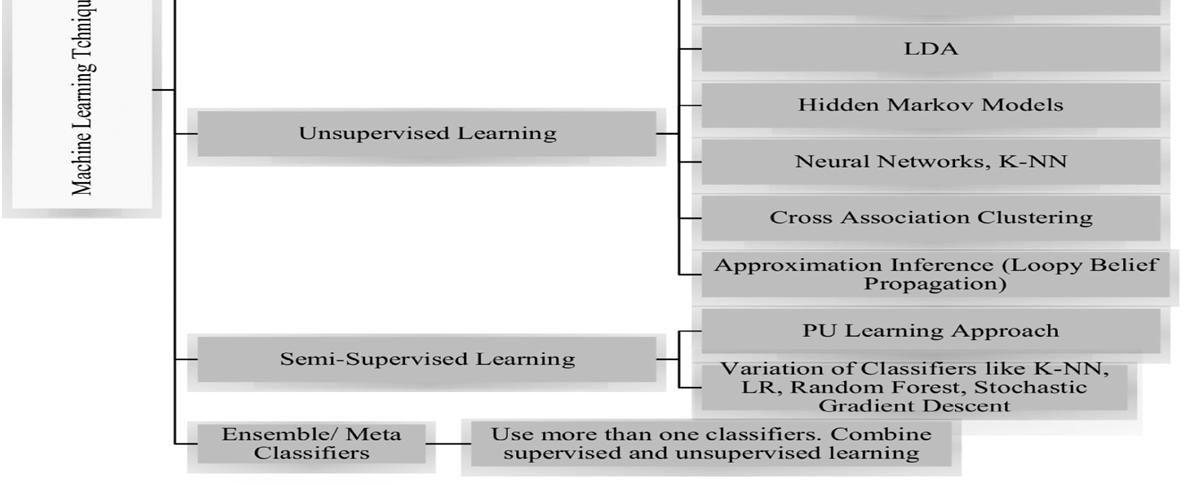
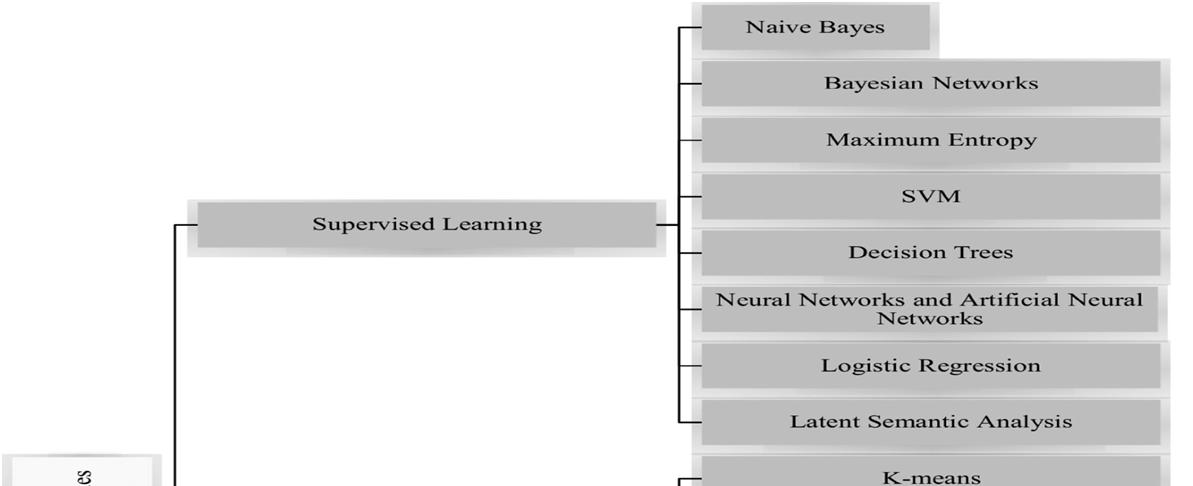
It includes approaches which make use of well-known machine learning (ML) methods as well as include linguistic features[5].The second step involves doing research utilizing a sentiment lexicon, a corpus of pre-compiled sentiment expressions. And further it is broken down into corpus-based techniques which will employ statistical or semantic techniques to determine the frequency of sentiment polarity.With both machine-learning and the hybrid strategy makes use of lexicon-based methodologies. The purpose of the following picture is to give an overview of some of the more well-liked sentiment categorization methods.
A. Use of Machine Learning
Machine learning techniques such as SA are conducted nearly completely and in great detail using machine learning (ML) algorithms[6,7,8,9,].In addition to linguistic and syntactic properties.
B. A Supervised Learning
Supervised Learning is a type of learning with labeled datasets.Such datasets are passed to supervised learning models to predict further[6,7,10].
ISSN: 2321-9653; IC Value: 45.98; SJ Impact Factor: 7.538

Volume 11 Issue II Feb 2023- Available at www.ijraset.com
With supervised learning, material that has been annotated is automatically categorized into specified classifications.[12] Khan et al. (2010) went into great length about a few of the supervised learning techniques. Here it discusses decision tree algorithms, Naive Bayes , K-means,, neural networks, support vector machines are examples of machine learning algorithms. According to [13] Medhat, Hassan, and Korashy (2014), supervised learning methods can also be categorized as Decision trees, linear classifiers, probabilistic classifiers, and classifiers based on rules. Probability classifier are based on mixture models, where the probability of sampling is specified for certain keywords. The Naïve Bayes classifier, Maximum_ Entropy, and Multidimensional algorithms are a few of these classifiers.The usage of these classifiers for sentiment classification is fairly widespread.The benchmark findings provided by these classifiers for sentiment classification [14, 16, 18]; The training data is divided using decision tree classifiers, which create a hierarchical structure in which a leaf node will display the classification outcome [12]. There are various methods like - ID3, C3, and C5 algorithms as well as several spanning tree and graph-based methods.Refer to these studies that employed decision tree algorithms for sentiment categorization for a better introduction[21].
Rule-based classifiers specify a collection of guidelines that are adhered to in accordance with the associations between the items. A rule is represented as a condition on one end, depending on the feature set and term presence, and the class label on the other. Refer to [24] [22] . The TF-IDF is the foundation of linear classifiers, which are used to categorize data. SVM, neural networks, artificial NN, and other linear classification methods are examples [25, 27, 28, 29].
C. Decision Tree Classifiers
The trained data space is broken down hierarchically using this kind of classifier, and attribute values are employed to separate the data. The technique continues for N number of records and when they are linked with the lead nodes that are making use of classification, depending on whether one or more words are present or absent.[10].
D. Naïve Bayes Classifier (NB)
To categorize text documents and perform SA on these types of materials, this classification method is fairly universally employed. The method, which is based on a probabilistic approach, approximates the probability of a particular group using the cooperative probabilities of individual phrases as input in a text document.[11]
E. Maximum Entropy Classifier (ME)
It is a kind of probabilistic classifier that belongs to the exponential family of models and does not rely on the idea that its constituent parts are independent. Conversely, ME is reliant on the Principle of Maximum Entropy. The model with the highest entropy is chosen. Applications for ME classifiers include dialect identification, assumption research, point arrangement, etc.
ISSN: 2321-9653; IC Value: 45.98; SJ Impact Factor: 7.538
Volume 11 Issue II Feb 2023- Available at www.ijraset.com
III. TOOLS
Massive amounts of heterogeneous data are present on social media, and to undertake analysis, there are specialized tools that can handle massive amounts of text data. On social media data, a variety of tools can do sentiment analysis, and different tools are needed to visualize social network data in real time. Numerous for-profit companies offer sentiment analysis tools that are aimed at analyzing reviews of customer on various products.
We have many tools available for free, including, MATLAB, and Python-NLTK. They offer a wide range of functionality for using machine learning and data analytics.
To keep track of data in real time and gauge emotion behind the text , sentiment visualization tools are employed. They display the structure and their properties.IN-Spire is one of the tools for sentiment visualization. such as Pulse, VISA, TIARA, etc. Table 7 lists the lexical resources and mash-up websites which we can use for sentiment analysis and also includes some visualization tools.
IV. LITERATURE SURVEY
[15] : Here, a group or a collection of tweets written by many end-users was constructed and were used to tell the user about the behavior that mostly focuses on sentiment analysis. Limitations: Data was acquired from the social sites to determine the person's activity. A website might be developed where people can type the Twitter search keyword.
[17] : We will be using the real and reversed data in pairs i.e. the dual training (DT) and dual prediction (DP) algorithms, respectively.The probability is maximum in case of DT for real and inverted data.We take both sides for review in case of DP. In other words, both the good and bad parts of the first assessment as well as the good and bad parts of the reversed assessment are considered.
[19] : The goal of this research is to outline some of these problems and offer some suggestions that will benefit the researchers and practitioners. Will explore general facets of the Arabic language. There are millions of native arabic people in the world.Additionally, 1.4 billion Muslims use this language for their regular prayers. Morphology is crucial in the highly structured and derivational language of Arabic.
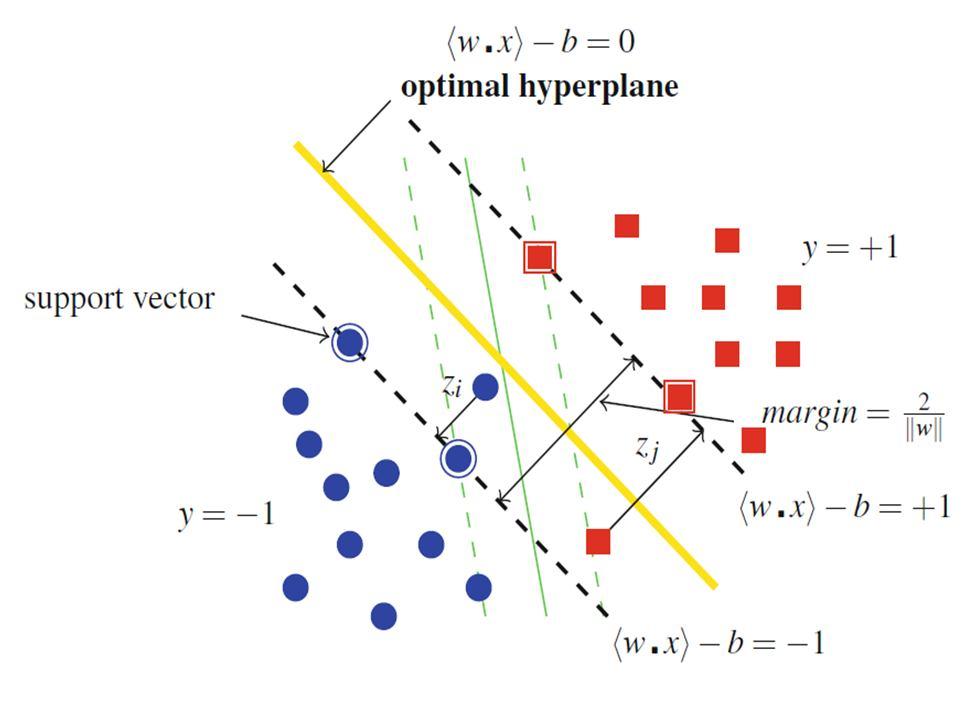
[20] : Practical usefulness for classification has been shown by SVM method. Face detection, text categorization, and bioinformatics are just a few of the areas where SVMs have been successfully applied [32]. They become more used as tools for data analysis. Despite having well-known traits, SVM is challenging to apply to the issue of handling massive data.Computational cost in case of svm is at least square of the number of data points. Scaling up learning methods is necessary for large data.
The SVM algorithm does not do well with large data sets. SVM performs poorly when the target classes overlap and the data set contains more noise.
[26] : The suggested method extracts features from tweets using both the methods.Supervised learning is used for the sentiment analysis, and utilizing the retrieved features, we train a number of classifiers.Designing and implementing a real-time system architecture in Storm involves feature extraction and classification tasks, which scale well in terms of input data size and data arrival rate, but are not critical steps. We use experimental evaluations to demonstrate the advantages of the proposed system, showing advantages in terms of efficiency, scalability and classification accuracy.
ISSN: 2321-9653; IC Value: 45.98; SJ Impact Factor: 7.538
Volume 11 Issue II Feb 2023- Available at www.ijraset.com
[5]: Sentiment analysis can handle a wide range of challenges, such as reliablity issues, binary classification issues, data issues, and polarity.Although numerous methods are created and proposed finding the emotions behind the text, a successful plan for regularly extracting and producing reliable sentiment analysis needs to be constructed. Despite the significant advancements in machine learning algorithms Naive Bayes, Support Vector Machine, and Maximum Entropy are the three that stand out as being particularly prevalent in research sentiment classification by category, including positive and negative sentiments, is still a research interest.. This article surveys popular sentiment analysis approaches and procedures in an effort to provide a clear evaluation report with supporting evidence.
[13]: In the field of sentiment analysis, text mining research is ongoing (SA). The subjectivity, emotions, and viewpoints of a text are handled algorithmically by SA. This survey study takes on a thorough analysis of the most recent advancement in this topic. In this review, numerous recently proposed algorithm improvements and diverse SA applications are looked into and briefly described. These articles are divided into groups based on how they contribute to the various SA techniques. The recent interest of researchers in the SA-related domains of transfer learning, emotion recognition, and resource building is explored.
[7]: The goal of sentiment analysis is to uncover any subjectivity, opinions, or feelings in the text. There are different ways of carrying out sentiment analysis using vocabulary based techniques and machine learning algorithms. In order to provide context, research works on sentiment analysis using machine learning are addressed in this article; (i) they are categorized according to the tasks they perform in terms of information extraction; and (ii) the difficulties that have been encountered and those that may arise in relation to this research topic are reviewed and discussed.
[8]: Utilizing sentiment analysis on more than 1000 Facebook posts on newscasts, this study contrasts the sentiment towards Rai, the Italian public broadcasting service, and La7, a young and more vibrant commercial enterprise. The findings of this study are contrasted with those of the Osservatorio di Pavia, an Italian research centre that examines political communication in the media and focuses on media analysis at both the theoretical and empirical levels. This study takes into account Auditel's statistics on the size of broadcast audiences and merges quantitative data from the public domain with social media analysis, notably Facebook analysis.
[9] : The supervised classifier must classify each tweet as "positive," "negative," or "neutral" in order to solve the sentiment analysis problem, which is stated as a multi-class classification task. In total, a Support Vector Machine (SVM)[34] is trained using the training tweets. In our tests, we make use of an L1 regularization and a linear kernel. To choose the C parameter, cross validation is employed. As mentioned before, emoticons are no longer present in tweets that are utilized as input for the SVM.

ISSN: 2321-9653; IC Value: 45.98; SJ Impact Factor: 7.538
Volume 11 Issue II Feb 2023- Available at www.ijraset.com
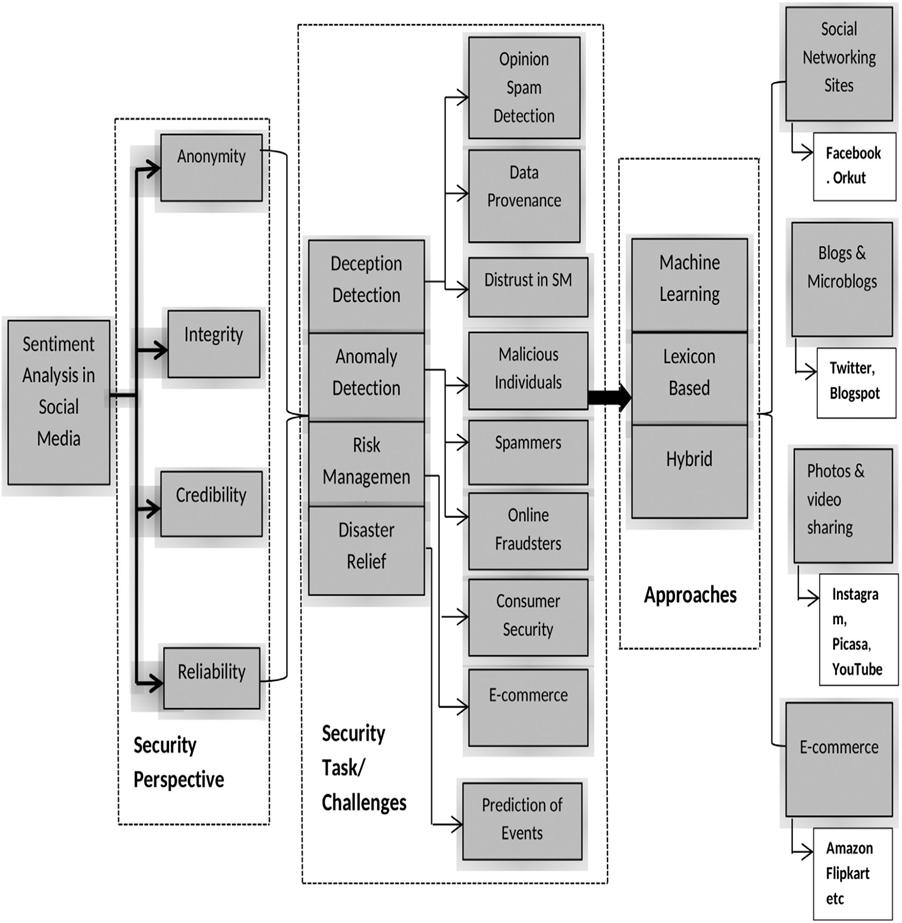
[35] : One of the most crucial areas of analysis that makes use of the vast amount of social data as well as its value in terms of its unprocessed and diverse character is sentiment analysis. The handling of such massive amounts of data when conducting analytics and making forecasts creates questions. To understand and convey the emotions portrayed in the text as well as to create predictions to address these issues, sentiment analysis uses text analytics, natural language processing, and other computational techniques to extract, preprocess, and detect subjective data. Social media usage and analytics are growing exponentially, and thus raises security and vulnerability analyses of such data, including the leak of confidential material, provenance and trust issues, and fraud and spam. Social media security and analysis heavily rely on sentiment analysis. It has been used extremely successfully to analyze social media content, identify numerous security aspects, and aid in the development of workable solutions. The role of sentiment analysis in identifying hostile actors, spammers, and online fraudsters is a key focus of this article. It also covers topics like data provenance, social media mistrust, e-commerce security, event prediction for disaster assistance, risk assessment, and other social media security solutions. Social media sentiment analysis is frequently used to examine user behavior and their interactions with other users.
[36]: HaterNet, an intelligence tool that monitors and recognises hate speech on Twitter, is now used by the Spanish National Office Against Hate Crimes of the Spanish State Secretariat for Security. This study has many contributions, some of which are as follows:
(1) It introduces the first intelligent system that uses social network analysis techniques to track and broadcast hate speech in social media. (2) It provides a brand-new dataset on hate speech in Spanish that is freely accessible and is made up of 6000 tweets that have been expertly categorised. (3) Using several document representation methods and text classification models, it compares various classification methodologies (4). The best method combines an LTSM+MLP neural network with the word, emoji, and expression token embeddings from tweets that have been enhanced using the tf-idf. This approach outperforms other tactics previously addressed in the literature, with an area under the curve (AUC) of 0.828 on our dataset.
Hate crimes are a specific category of legal infractions where the victims' perceived victimhood is the main driving force. This occurs when the perpetrator chooses his or her victims based on their affiliation with a specific group that is predominantly characterized by the traits mentioned before. There is proof that certain highly publicised events, such as terrorist attacks, unchecked migration, protests, riots, etc., have an impact on hate crimes [37]. These situations frequently serve as triggers, and inside SM, their impact is greatly heightened. As a result, SM functions as a sensor in the actual world [38] and a significant resource for crime predicting [39]. Social media platforms are actually flooded with posts from users calling for the punishment of various targeted groups. After a trigger event, these signals can be accumulated over time and used to study hate crimes in all aspects [37] climbing, stabilizing, duration, and fall of the threat. The analysis, prognostication, and identification of hate crimes thus depend heavily on monitoring social media.
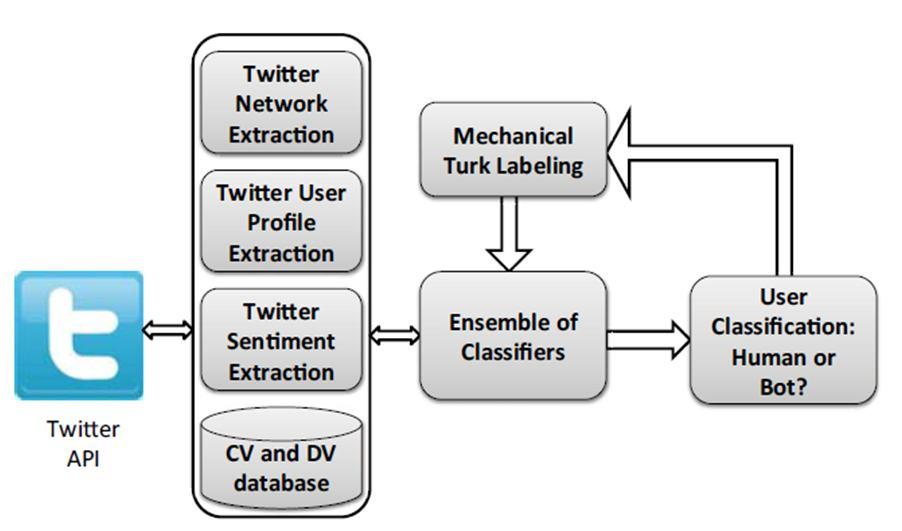
[40] : These "bots" post content that can be either beneficial (such as recent news articles or PSAs) or harmful (such as spam or phishing links). Such harmful Twitter bots have grown to be an annoyance, recently inspiring a lengthy tirade in The New Yorker [1].
ISSN: 2321-9653; IC Value: 45.98; SJ Impact Factor: 7.538
Volume 11 Issue II Feb 2023- Available at www.ijraset.com
They allegedly contribute to the public's perception of political candidates being distorted. For instance, the website botornet.net asserts that Newt Gingrich, a past candidate for the US presidency, obtained more than a million Twitter followers by deploying bots, a claim Mr. Gingrich apparently denied. Additionally, Hill [2] states that "up to 29.9% of Barack Obama's [Twitter] followers and 21.9% of Mitt Romney's followers may be fake." 83 million of Facebook's users, in the company's opinion, are fake. In conclusion, it is now widely accepted that a sizable portion of social media is made up of bots, many of which have malicious intentions.
V. CONCLUSION WITH FUTURE WORK
We covered information extraction as well as preprocessing methods for tweets from Twitter. Additionally, we researched Support Vector Machine for text categorization, a supervised learning method that may be utilized to determine the polarity of textual tweets. in studies.We can draw the conclusion that SVM recognizes some characteristics of text, such as high dimension. Various findings demonstrate that SVM performs well on text categorization when compared to ANN. SVM reduces the requirement for feature selection because of its capacity to generalize high dimensional feature space.Tweets polarity is used as Twitter sentiment analysis.It is then passed to the machine learning model to train to and then test with the same, allowing us to employ this model going forward in accordance with the findings. It entails actions including gathering data, text preparation, sentiment categorization, sentiment detection, model training, and testing.
But the dimension of data diversification is still missing. Other application difficulties are also consequences of the language and acronyms used.
Performance of analyzers is suffering as the number of classes rises. Additionally, the accuracy of models are not tested yet. As a result, sentiment analysis has a highly promising future.Finding the most effective method for recognising feelings in Twitter data proved to be one of the biggest challenges, as comparing different methods is a very tough undertaking when there are no established benchmarks.Future research would be interesting in examining how sentiment analysis algorithms perform for a particular feature. In other words, it was discovered that integrating different features usually improved performance, but in certain situations had mixed results. Therefore, a fascinating work has to be done to help the performance limitations. Another option may be to look into the problem of data sparsity utilizing both ensemble and hybrid methods. The goal of this is to assess how well different Twitter sentiment techniques cope with data scarcity
References
[1] W. Medhat, A. Hassan, and H. Korashy, ―Sentiment analysis algorithms and applications: A survey‖, Ain Shams engineering journal, Vol. 5, No. 4, pp. 10931113, December 2014, doi:10.1016/j.asej.2014.04.011.
[2] X. Fang, and J. Zhan, ―Sentiment analysis using product review data‖, Journal of Big Data, Vol. 2, No.1, p.5, June 2015, doi: 10.1186/s40537-015-0015-2.
[3] H. Kang, S.J. Yoo, and D. Han, ‖Senti-lexicon and improved Naïve Bayes algorithms for sentiment analysis of restaurant reviews‖, Expert Systems with Applications, Vol. 39, No. 5, pp. 6000-6010, 2012
[4] Batrinca, and P.C. Treleaven, ―Social media analytics:a survey of techniques, tools and platforms‖, Ai & Society, Vol. 30, No. 1, pp. 89-116, 2015.
[5] INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 9, ISSUE 05, MAY 2020 ISSN 2277-8616166 IJSER©2020
Raktim Kumar Dey, Debabrata Sarddar, Indranil Sarkar, Rajesh Bose, Sandip Roy:A Literature Survey On Sentiment Analysis Techniques Involving Social Media And Online Platforms
[6] W. Med Hat , Ahmed Hassan ,Hoda Korashy―Sentiment analysis algorithms and applications: A surve‖, Ain Sham University, Faculty of Engineering,Computer & Systems Department, Egypt 19, Vol. 5, No. 4, pp. 1093-1113, December 2014.
[7] E. Erdogan, and M. A. Akyol, ―A Comprehensive Survey for Sentiment Analysis Tasks Using Machine Learning Techniques‖, In proc. 2016 International Symposium on INnovations in Intelligent SysTems and Applications (INISTA), IEEE, Sinaia, Romania, August 2016, doi: 10.1109/INISTA.2016.7571856.
[8] F. Neri, C. Aliprandi, F. Capeci, M. Cuadros, T. By,―Sentiment Analysis on Social Media‖, In Proceedings of 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Istanbul, August 2012,doi: 10.1109/ASONAM.2012.164.
