Can Small Quantized VLMs Drive? An Experimental Evaluation of Small Quantized VLMs for Autonomous Driving Samson Mathew, Zonghua Gu Hofstra University, USA
Introduction
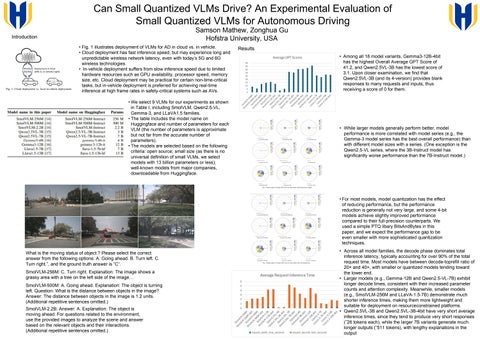
• Fig. 1 illustrates deployment of VLMs for AD in cloud vs. in vehicle. • Cloud deployment has fast inference speed, but may experience long and unpredictable wireless network latency, even with today’s 5G and 6G wireless technologies. • In-vehicle deployment suffers from slow inference speed due to limited hardware resources such as GPU availability, processor speed, memory size, etc. Cloud deployment may be practical for certain non-time-critical tasks, but in-vehicle deployment is preferred for achieving real-time inference at high frame rates in safety-critical systems such as AVs. • We select 9 VLMs for our experiments as shown in Table I, including SmolVLM, Qwen2.5-VL, Gemma-3, and LLaVA1.5 families. • The table includes the model name on Huggingface and number of parameters for each VLM (the number of parameters is approximate but not far from the accurate number of parameters). • The models are selected based on the following criteria: open source; small size (as there is no universal definition of small VLMs, we select models with 13 billion parameters or less); well-known models from major companies, downloadable from Huggingface.
Results • Among all 18 model variants, Gemma3-12B-4bit has the highest Overall Average GPT Score of 41.2, and Qwen2.5VL-3B has the lowest score of 3.1. Upon closer examination, we find that Qwen2.5VL-3B (and its 4-version) provides blank responses to many requests and inputs, thus receiving a score of 0 for them.
• While larger models generally perform better, model performance is more correlated with model series (e.g., the Gemma-3 model series has the best overall performance) than with different model sizes with a series. (One exception is the Qwen2.5-VL series, where the 3B-Instruct model has significantly worse performance than the 7B-Instruct model.)
• For most models, model quantization has the effect of reducing performance, but the performance reduction is generally not very large, and some 4-bit models achieve slightly improved performance compared to their full-precision counterparts. We used a simple PTQ libary BitsAndBytes in this paper, and we expect the performance gap to be even smaller with more sophisticated quantization techniques. What is the moving status of object ? Please select the correct answer from the following options: A. Going ahead. B. Turn left. C. Turn right.”, and the ground truth answer is ”C“. SmolVLM-256M: C. Turn right. Explanation: The image shows a grassy area with a tree on the left side of the image… SmolVLM-500M: A. Going ahead. Explanation: The object is turning left. Question: What is the distance between objects in the image? Answer: The distance between objects in the image is 1.2 units. (Additional repetitive sentences omitted.) SmolVLM-2.2B: Answer: A. Explanation: The object is moving ahead. For questions related to the environment, use the provided images to analyze the scene and answer based on the relevant objects and their interactions. (Additional repetitive sentences omitted.)
• Across all model families, the decode phase dominates total inference latency, typically accounting for over 90% of the total request time. Most models have between decode-toprefill ratio of 20× and 40×, with smaller or quantized models tending toward the lower end. • Larger models (e.g., Gemma-12B and Qwen2.5-VL-7B) exhibit longer decode times, consistent with their increased parameter counts and attention complexity. Meanwhile, smaller models (e.g., SmolVLM-256M and LLaVA-1.5-7B) demonstrate much shorter inference times, making them more lightweight and suitable for deployment on resourceconstrained platforms. • Qwen2.5VL-3B and Qwen2.5VL-3B-4bit have very short average inference times, since they tend to produce very short responses (˜26 tokens each), while the larger 7B variants generate much longer outputs (˜511 tokens), with lengthy explanations in the output