Data Storage CHANNEL GUIDE
Storage wird Bestandteil der KI-Fabrik
Die Storage-Branche profitiert vom KI-Boom: Denn die unterschiedlichen KI-Workloads benötigen enorme Mengen an Speicherplatz. Zudem gewinnt das Datenmanagement noch mehr an Bedeutung als Schlüsselelement für erfolgreiche KI-Projekte. 6
Speichermarkt im Ungleichgewicht
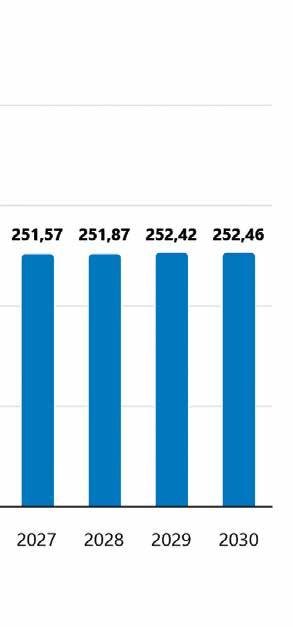
Mit dem KI-Rennen startet auch jenes um Speicherkapazitäten. 12
Starke NAS-Systeme mit lokaler KI
Leistungsfähige Prozessoren sorgen bei KI-NASSystemen für eine sichere lokale KI-Nutzung. 22
Die „Repatriierung“ ins eigene Datacenter Repatriierung ist kein Generalangriff gegen die Cloud, sondern eine selektive Neuausrichtung. 26
Storage wird Bestandteil der KI-Fabrik 6
Die Strorage-Branche profitiert vom KI-Boom, denn KIWorkloads benötigen enorme Mengen an Speicherplatz.
Zahlen und Fakten
Im Storage-Markt steigen die Preise und das Wachstum setzt sich fort.
Speichermarkt im Ungleichgewicht
Mit dem KI-Rennen startet auch jenes um Speicherkapazitäten.
Renaissance für HDDs und SSDs
HAMR-HDDs mit 100 TB sollen künftig den Datenhunger der KI- und Cloud-Rechenzentren stillen.
10
12
14
Glas und Film als Datenspeicher 18
Datenspeicher, die 1.000 Jahre überstehen sollen und sich einfach auslesen lassen, versprechen optische Speichertechnologien.
KI übernimmt das Storage-Management 20
Das durch KI und Compliance-Regeln forcierte Datenwachstum stellt die IT-Administration vor eine Zäsur.
Starke NAS-Systeme mit lokaler KI
Leistungsfähige Prozessoren sorgen bei KI-NAS-Systemen für eine sichere lokale KI-Nutzung.
22
Die „Repatriierung“ ins eigene Datacenter 26 Repatriierung ist kein Generalangriff gegen die Cloud, sondern eine selektive Neuausrichtung
Der intelligente Tresor für Daten 30 Für sichere Datenumgebungen müssen Storage und Security von Anfang an zusammen gedacht werden.
Der KI-Boom hat zwiespältige Auswirkungen auf die StorageBranche: Einerseits bringt er eine Nachfrage nach optimierten Systemen, andererseits treibt er die Preise nach oben.




























Prinzipiell geht es der Storage-Branche blendend: Die Hersteller von NAND-Flash verzeichnen Rekordgewinne, DatacenterHDDs verkaufen sich großartig und auch die Hersteller von Storage-Systemen können zufrieden sein: Laut dem IDC-StorageTracker sind die Umsätze in der EMEARegion im vierten Quartal 2025 um 4,3 Prozent im Vergleich zum Vorjahresquartal gestiegen, mit dem höchsten Wachstum bei All-Flash-Systemen und auch einem Plus bei reinem HDD-Storage. Ein wichtiger Faktor ist dabei die steigende Nachfrage nach KI-Lösungen in Unternehmen, die passenden Storage benötigen. Das zeigt sich auch in den Kategorien der StorageSysteme: Laut den IDC-Analysten sind Midrange-Systeme mit 8,8 Prozent stärker gewachsen als die High-End-Kategorie mit 5,4 Prozent. Die Nachfrage nach Entry-Systemen ist dagegen um 6,9 Prozent gesunken. Allerdings bereiten die steigenden Kosten für SSDs und auch HDDs vor allem dem Channel Kopfzerbrechen. Er sieht sich mit teilweise knappen Komponenten, steigenden Lieferzeiten und Preisanpassungen der Hersteller konfrontiert. Diese Umstände erschweren die Projektplanung und erfordern von den Systemhäusern eine intensive Kommunikation mit den Kunden.
Der KI-Boom wirkt sich nicht nur auf den Markt für Storage-Systeme aus, sondern auch auf die Systeme selbst. Denn die Anforderungen von KI-Infrastrukturen im großen Maßstab, den KI-Fabriken, lassen sich mit herkömmlicher Storage-Hardund Software kaum erfüllen. Hier sind spezielle Lösungen angesagt. Eine wichtige Rolle nimmt dabei Nvidia als mit Abstand führender Hersteller von KI-Lösungen ein, die nicht nur die Hardware, sondern auch das Software-Ökosystem umfassen. Bereits im vergangenen Jahr hat der KI-Gigant damit begonnen, Enterprise-Storage-Systeme für die eigenen KI-Lösungen zu zertifizieren und hat gleichzeitig mit der Nvidia AI Data Platform eine Referenzplattform geschaffen, an der sich Storage-Hersteller wie DDN, Dell Technologies, HPE, IBM und NetApp beteiligt haben. Dabei spielen natürlich Nvidia-Produkte wie BlueField DPUs und Spectrum-X-Netzwerk-Komponenten eine wichtige Rolle. HPE konnte da-
bei mit Alletra Storage MP X10000 kürzlich die erste Nvidia-Zertifizierung für ein Object-Storage-System auf dem Foundation-Level erringen. Darunter versteht Nvidia kleinere und mittlere KI-Umgebungen mit maximal 128 GPUs.
Auf der Hausmesse GTC im März hat Nvidia mit STX eine neue Referenzplattform für die kommende Vera-Rubin-Plattform vorgestellt und dafür mit Ausnahme von Huawei praktisch alle wichtigen Storage-Hersteller an Bord geholt. Laut Nvidia fehlt bei herkömmlichen Storage-Architekturen die Reaktionsfähigkeit für den großflächigen Agentic-AI-Einsatz. STX soll Storage-Anbietern eine Vorlage für einen modularen Storage-Stack bieten, der diese Anforderungen erfüllt. Eine zentrale Komponente dafür soll die CMX Context Memory Storage Platform mit Nvidias BlueField-4Storage-Prozessoren sein, die den GPUSpeicher um einen sehr schnellen Kontex-Layer für skalierbare Inferenz und KI-Agenten erweitert. Der Chip-Hersteller verspricht die fünffache Anzahl von Tokens pro Sekunde im Vergleich zu herkömmlichen Storage. Huawei hat auf dem MWC in Barcelona eine eigene KI-Datenplattform vorgestellt, die mit einem Unified Cache Manager (UCM) und KI-Daten-EngineNodes ähnliches leisten soll. Als Speicherplattform für neue Projekte soll dabei OceanStor A800 dienen. Allerdings kann die Lösung auch bestehende OceanstorDorado-Systeme einbinden.
Auch die Nvidia-Partner entwickeln weiter eigenständige Storage-Lösungen für KIAnwendungen. So hat NetApp im März das 2U-All-Flash-Storage-System EF80 vorgestellt, das eine kostengünstige und mit 63,7 GB/s pro kW auch energieeffiziente Lösung für Hochdurchsatz- und NiedriglatenzWorkloads wie KI liefern soll. Der Hersteller gibt für EF80 einen Lesedurchsatz von über 110 GB/s und eine Schreibleistung von 55 GB/s an, eine Verbesserung von 250 Prozent gegenüber der bisherigen Generation. Das ebenfalls neue EF50-System soll sich dagegen eher für gemischte Workloads wie transaktionsorientierte Datenbanken eignen. Beide EF-Systeme lassen sich auf bis zu 1,5 PB auf zwei Höheneinheiten ausbau-
Die exponentiellen Fortschritte in KI, Cloud und Datenanalytik, vor allem in diesem Jahr, fordern bestehende IT-Infrastrukturen heraus und bringen Unternehmen zum Umdenken.
Vor sechzehn Jahren haben wir Storage völlig neu gedacht. Nun erfinden wir das Datenmanagement neu. Everpure ist unser nächstes Kapitel, damit Unternehmen mehr mit ihren Daten machen können, als sie nur speichern.
Begoña Jara, Vice President und General Manager Germany bei NetApp
John Colgrove, Gründer und Chief Visionary Officer von Everpure
DISAGGREGIERTER STORAGE FÜR KI
Die disaggregierten AXF-Systeme von NetApp bestehen aus AFX-1K-Storage-Controllern, NX224-Storage-Enclosures mit NVMe-SSDs, und optionalen DX50-Data-Compute-Nodes.
Mit der AXF-Serie hat NetApp ein disaggregiertes StorageSystem für anspruchsvolle KI-Anwendungen auf den Markt gebracht. Es besteht aus separaten Storage-Controllern und Storage-Enclosures als gemeinsamem Storage-Pool. Die Komponenten können unabhängig voneinander skaliert werden. Als optionaler Bestandteil soll noch ein Data-Compute-Node mit AMD-Epyc-CPU und Nvidia-GPU kommen. Als umfassender KI-Datenservice für alle NetApp-Daten in der hybriden Cloud dient die NetApp AI Data Engine (AIDE).
en. Eine integrierte Observability-Funktion stellt Performance-Werte wie Durchsatz, Latenz und Cache-Nutzung bereit, um mögliche Störfaktoren für die GPU-Auslastung zu identifizieren und zu beseitigen. Als High-End-Storage-System für KI hat der Hersteller Ende 2025 die disaggregierten Storage-Systeme der AFX-Serie vorgestellt.
Eine Kombi-Lösung für KI-Anwendungen haben Scality und Weka gemeinsam entwickelt. Die Objektspeicher-Software Scality Ring ist dabei für Skalierbarkeit und Kosteneffizienz zuständig. Sie erlaubt auf HDD-Systemen eine Skalierung bis in den Exabyte-Bereich. Wie Paul Speciale, Chief Marketing Officer (CMO) bei Scality, betont, fallen nicht nur bei multimodaler und generativer KI, sowie bei Agentic AI enorme Datenmengen an, sondern auch bei klassischem Machine Learning und Predictive Analytics. Weka NeuralMesh ist dagegen auf Performance optimiert. Bei der im Juni letzten Jahres vorgestellten Lösung handelt es sich um eine Storage-Software, die dafür ausgelegt ist, GPU- und TPU-Systeme möglichst schnell mit Daten zu versorgen. Der Hersteller
verspricht hier eine GPU-Auslastung von 93 Prozent beim KI-Training.
Einen spannenden Ansatz bei KI-Storage hat die noch junge Firma Hammerspace entwickelt: Die Data Platform mit einem globalen Namespace für File- und Object-Storage, der bestehenden und neuen Storage umfasst, und zwar On-Premises, in der Cloud und an Edge-Standorten. Dazu kommen automatisierte Data Services und eine intelligente Datenorchestrierung. Bestehende Metadaten von Objektspeichern werden in die Metadaten-Datenbank von Hammerspace kopiert und damit global verfügbar gemacht. In die Speicherebene der Hammerspace Data Platform können Storage-Systeme anderer Hersteller einfach eingebunden werden. Die Hammerspace-Software auf Anvil- und DSX-Nodes übernimmt dann das Metadaten- und das Daten-Management. Zudem wird lokaler NVMe-Speicher in einem GPUServer-Cluster als gemeinsame Hochleistungsressource aktiviert, um Workloads zu beschleunigen und die Auslastung der GPU-Server zu erhöhen. Die Hyperscale-NAS-Architektur soll die Performance von parallelen Dateisystemen wie Lustre oder GPFS mit der Einfachheit von Scale-outNAS-Systemen kombinieren. Hammerspace arbeitet auch intensiv mit Hitachi Vantara zusammen. Über das Model Context Protocol (MCP) können KI-Agenten in Hitachis iQ Studio, der KIEntwicklungs- und Deployment-Plattform des Unternehmens, direkt auf Hammerspace-verwaltete Daten zugreifen und mit ihnen arbeiten, ohne dass diese physisch verschoben werden müssen. Die Daten bleiben dabei auf der Virtual Storage Platform One von Hitachi Vantara.
Bestehende SSD-Ressourcen angesichts steigender Speicherpreise effektiver für KI oder andere Workloads nutzen: Das verspricht Vast Data für das Programm Vast Amplify. Dabei werden laut dem Hersteller zunächst ungenutzte SSD-Kapazitäten und durch Silos bedingte Fragmentierungen identifiziert. Unterstützte DAS-Systeme mit NVMe-SSDs können dann mittels Installation der Vast-Software in ein E-Box-Cluster verwandelt und in die DASE-Architektur (Disaggregated Shared Everything) des Vast AI Operating System konsolidiert werden. Ist das nicht möglich, lassen sich zumindest qualifizierte SSDs in NVMe-oFJBOF-Systemen verwenden, die dann zusammen mit Vast-Compute-Nodes einen disaggregierten Cluster bilden. Dort sollen modernes Erasure Coding und Datenreduktion sowie der Verzicht auf
BILD: NETAPP
redundante Replikation zu einer besseren Nutzung der Rohkapazität führen, als in traditionellen Storage-Systemen. Je nach Workload und Umgebung soll sich die effektive Speicherkapazität um bis zu Faktor sechs steigern lassen, verspricht Vast Data.
Eine weitere Herausforderung für erfolgreiche KI-Projekte liegt im Management der Daten. Die will Everpure angehen, das Unternehmen, das bis Februar dieses Jahres als Pure Storage bekannt war. Der vor 16 Jahren gegründete Hersteller war seinerzeit ein Pionier bei der Flash-Storage-Technologie und mit Evergreen auch bei Storage als Service. In den folgenden Jahren hat die Firma ihren Fokus immer weiter in Richtung Datenmanagement erweitert, etwa mit der Übernahme des KubernetesData-Management-Anbieters Portworx und zuletzt mit der Enterprise-Data-CloudArchitektur. Nun will das Unternehmen die Zukunft des Datenmanagements neu definieren und dabei auch Plattformen anderer Storage-Hersteller abdecken. Laut John „Coz“ Colgrove, Gründer und Chief Visionary Officer der Firma, hat vor allem die Einführung von KI die Defizite beim Datenmanagement in vielen Firmen offengelegt. Daten liegen in isolierten Silos, unflexible Infrastrukturen und manuelle Prozesse bei der Datenverwaltung behindern die effiziente Nutzung für KIAnwendungen. Bereits die Enterprise Data Cloud (EDC) von Pure Storage hat Daten auf Pure-Storage-Systemen und in der Public Cloud in eine einheitliche, virtualisierte Daten-Cloud gebracht, die von einer intelligenten Steuerungsebene verwaltet wird. Nun wird die Plattform um Datenerkennung und semantischen Kontext ergänzt. Die Umbenennung in Everpure soll diesen erweiterten Ansatz reflektieren.

ETERNUS CS8000 FÜR KI
Die neue Generation der Storage-Lösung Eternus CS8000 von Fsas für File- und ObjectStorage soll sich nun auch für den Aufbau von Data-Lake-Architekturen für KI-Workloads eignen. Der Hersteller nennt vor allem RAG als Einsatzgebiet für das System mit bis zu 350 PB Speicherkapazität.
Die dafür nötige Software und auch die Entwickler bekommt Everpure mit der Übernahme des 2017 gegründeten US-Unternehmens 1Touch, einem Anbieter von Data Security Posture Management (DSPM). Die dafür entwickelte Technologie soll Everpure dazu befähigen, Daten über alle Datensätze und jede Umgebung hinweg – von SaaS bis zum Edge –mit KI-Hilfe zu erkennen, zu klassifizieren, zu kontextualisieren und anzureichern. „Mit 1Touch gehen wir den nächsten Schritt, um Unternehmen nicht nur dabei zu helfen, die Kontrolle über ihr wertvollstes Kapital – ihre Daten – zu erlangen, sondern diese Daten auch zu verstehen, zu verbessern und in einen Kontext zu setzen, um daraus verwertbare Erkenntnisse zu gewinnen“, erklärt dazu Charles Giancarlo, CEO von Everpure. Chief Data Officers und deren Teams sollen so erkennen, welcher Teil der Rohdaten in ihrem Unternehmen für KI-Anwendungen nutzbar ist und wo Einschränkungen bei der Datenqualität bestehen. Data- und Storage-Administratoren können überflüssige Kopien von Daten identifizieren, Daten konsolidieren und erkennen, welche Daten für KI-Workloads aus Compliance-Gründen nicht genutzt werden dürfen.
Mit der Übernahme von Dataloop baut auch Dell die eigenen Fähigkeiten in diesem Bereich aus. Das israelische Startup ist auf die Verwaltung und Kennzeichnung unstrukturierter Daten spezialisiert. Deren Technologie wird nun in der neuen Dell Data Orchestration Engine verwendet, einer zusätzlichen Schicht in der Dell AI Data Platform mit Nvidia.
Mehr unter: https://voge.ly/Nvidia_GTC26/
Autor: Klaus Länger
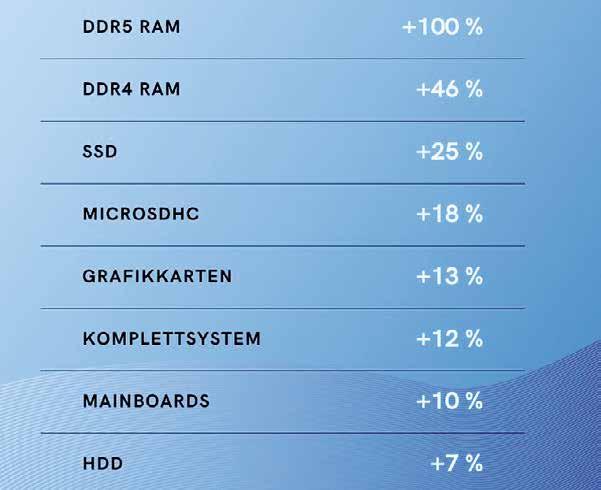
Das Vergleichsportal guenstiger.de verzeichnete von November 2025 bis Januar 2026 steigende Preise bei verschiedenen Proktkategorien aus dem PC-Bereich.



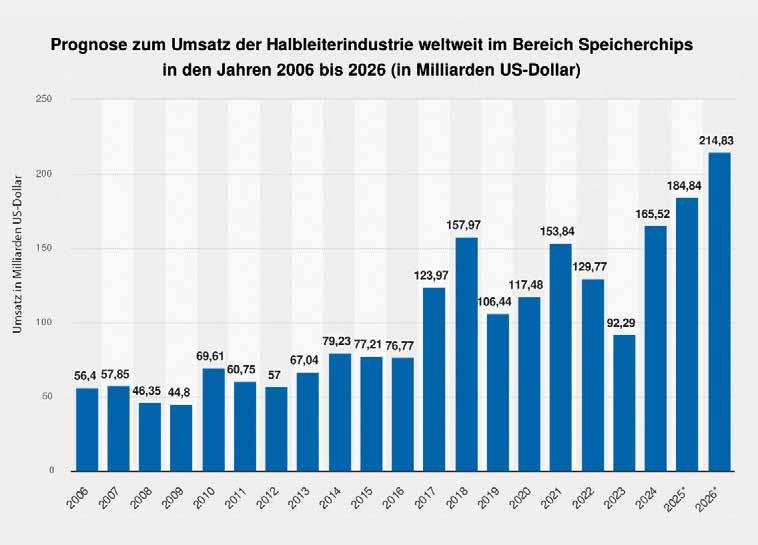



































Nutzer moderner RAM-Technik sind davon besonders betroffen, wie eine Auswertung des Vergleichsportals guenstiger.de zeigt. Demnach lag der Durchschnittspreis für DDR5 RAM im Januar 2026 um 100 Prozent höher als im November 2025. Auch bei DDR4 RAM (+46 %) sowie DDR3 RAM (+28 %) gibt es Erhöhungen. Rocco Frömberg, Leiter Vendor Development & Operations bei TIM, kann das bestätigen. Die Engpässe konzentrieren sich auf „DRAM und NAND-Flash als Basiskomponenten.“ Auch Nikolai Laubstein, Head of Category Management & Sales bei TD Synnex GCC, berichtet: „Aktuell zeigen HDDs, ausgewählte SSD-Segmente sowie DRAM-Komponenten eine eingeschränkte Verfügbarkeit und Preiserhöhungen.“ Dem schließt sich Julian Meyer, Head of Sales & Marketing bei Bytec, an: „Vor allem Flash-basierte Storage-Komponenten wie SSDs sowie RAM-Module stehen aktuell unter Preisdruck. Hier sehen wir steigende Einkaufspreise und teilweise verlängerte Lieferzeiten.“
Das bisherige Vorgehen der Distributoren gerät damit ins Ungleichgewicht, beispielsweise bei den Lieferzeiten. Hier berichtet Frömberg, dass die
Lieferzeiten nach Covid für individuell konfigurierte Storage-Systeme meist bei zwei bis vier Wochen lagen. „Aktuell beginnen sie eher bei vier Wochen und können – je nach Speicher- und Komponentenarchitektur – in Einzelfällen mehrere Monate betragen.“ Damit können Angebote für Partner nicht mehr in der gewohnten Geschwindigkeit erfolgen, wie noch vor ein paar Jahren. Zwar würden sich die Lieferzeiten je nach Hersteller und Produktkategorie unterscheiden, „grundsätzlich sehen wir jedoch eine anhaltende Herausforderung, verlässliche Lieferzeiten für bestimmte kritische Komponenten zu erhalten. Im Vergleich zu früheren Jahren ist die Planbarkeit deutlich geringer geworden“, so Laubstein.
Dieser Herausforderung begegnen Distributoren unterschiedlich, setzen aber alle auf intensive Partnerkommunikation. „Die Anpassungen erfolgen in mehreren Wellen entlang der Wertschöpfungskette“, so Frömberg. „Wir sorgen dabei aktiv für Transparenz, erläutern Hintergründe, ordnen Auswirkungen auf Projekte ein und stimmen Preisgültigkeiten sowie Lieferfenster frühzeitig ab.“ Auch Laubstein unterstreicht: „In dieser an-
spruchsvollen Marktsituation stehen wir unseren Partnern mit Beratung und Unterstützung zur Seite. Preisanpassungen, die uns von den Herstellern erreichen, betreffen uns als Distributor unmittelbar und müssen entsprechend weitergegeben werden. Umso wichtiger ist eine enge und offene Kommunikation.“
Kommunikation macht nur einen Teil der Strategie aus. So setzt Bytec auf „eine Kombination aus Lagerstrategie, enger Abstimmung mit Herstellern und Unterstützung unserer Partner in Projekten“. Durch eine frühzeitige Bevorratung konnte der Spezialdistributor einen Puffer schaffen. Doch auch Vorräte gehen irgendwann zur Neige. „Gleichzeitig priorisieren wir derzeit die Auslieferung kompletter Server- und Storage-Systeme gegenüber der Abgabe einzelner Komponenten. So versuchen wir sicherzustellen, dass Projekte unserer Partner möglichst planbar bleiben“, nennt Meyer eine weitere Maßnahme. Vervollständigt wird das durch die Unterstützung bei Projektplanung, z.B. mit alternativen Konfigurationen, technischer Beratung oder Programmen, über die sich bestimmte Systemkonfigurationen schneller liefern lassen sollen. Auch TD Synnex hat bereits reagiert und setzt „unter anderem auf den Ausbau von Lagerbeständen sowie auf Vorbestellungen, um die Versorgungssituation bestmöglich abzusichern“, erklärt Laubstein. Das Aufstocken der Lagerbestände hält Frömberg für wenig sinnvoll: „Eine langfristige Bevorratung ist in der aktuellen Situation kein nachhaltiger Ansatz – sie kann kurzfristige Spitzen abfedern, löst jedoch keine strukturellen Kapazitätsengpässe.“ Der VAD setzt stattdessen auf eine enge Abstimmung mit Herstellern, um frühzeitig Informationen zu Preis- und Verfügbarkeitsentwicklungen zu erhalten. Der Schwerpunkt liegt daher auf „fundierter Architekturberatung: Gemeinsam mit dem Endkunden den optimalen Kompromiss aus Performance, Verfügbarkeit und Preis finden – und Lösungsstacks bei Bedarf gezielt anpassen.“ Die Meinungen, ob eine aktuelle Bevorratung vorteilhaft ist, gehen damit auseinander. Fest steht jedoch, Distributoren, die schon vor diesen Entwicklungen mit Komponenten vorge-
sorgt haben, können das nun zu ihrem Vorteil nutzen. Sie haben die Möglichkeit, ihren Partnern – solange der Vorrat reicht – Verfügbarkeiten zuzusichern.
Das jedoch auch nur, wenn von einer zeitigen Verbesserung auszugehen ist. Darin liegt das Problem. „Aktuell sehen wir einen extrem dynamischen und sehr ‚hungrigen‘ Markt, möglicherweise stärker und länger anhaltend als jemals zuvor“, getrieben durch den KI-Boom, beschreibt Laubstein die Lage. „Solange Angebot und Nachfrage nicht in ein besseres Gleichgewicht kommen, rechnen wir weiterhin mit einem angespannten Marktumfeld“, sagt er weiter. Frömberg gibt daher eine realistische Prognose ab: „Nach aktuellen Einschätzungen aus dem Lieferantenumfeld wird die angespannte Situation mindestens bis ins erste Halbjahr 2027 anhalten.“ Meyer hingegen erwartet, dass sich der Markt mittelfristig schrittweise stabilisiert. „Gleichzeitig bleibt Storage ein innovationsgetriebenes Segment mit teilweise starken Nachfragezyklen. Für Partner wird es deshalb weiterhin wichtig sein, Projekte frühzeitig zu planen, Alternativen im Portfolio zu kennen und eng mit Herstellern und Systemhauspartnern zusammenzuarbeiten.“
Handlungsempfehlungen gibt auch Frömberg: „Partner sollten Budgets frühzeitig sichern, Projekte priorisieren und Investitionen strukturiert planen.“ Und durch enge Abstimmungen mit Herstellern und „transparente Projektplanung lassen sich viele Vorhaben dennoch verlässlich strukturieren“. Ähnlich appelliert Laubstein: „Partner sollten frühzeitig planen, Bedarfe priorisieren und Projekte möglichst früh mit uns abstimmen, um Risiken in Verfügbarkeit und Preisentwicklung zu minimieren.“ Vorlauf und eine realistische Planung sind essenziell. Die Preissteigerungen betreffen alle Handelsstufen. Doch mit der richtigen Strategie, enger Partnerkommunikation, flexibler Projektplanung und Beratung lässt sich diese Phase besser meistern.
Mehr unter: https://voge.ly/vglWavd/ Autor: Mihriban Dincel
Rocco Frömberg, Leiter Vendor Development & Operations bei TIM
„Durch unsere enge Abstimmung mit den Herstellern erhalten wir frühzeitig Informationen zu Preis- und Verfügbarkeitsentwicklungen, die wir in die Projektplanung einfließen lassen.“
„Aktuell sehen wir einen extrem dynamischen und sehr ‚hungrigen‘ Markt, möglicherweise stärker und länger anhaltend als jemals zuvor.“
Julian Meyer, Head of Sales & Marketing bei Bytec
„Wir setzen aktuell auf eine Kombination aus Lagerstrategie, enger Abstimmung mit Herstellern und Unterstützung unserer Partner in Projekten.“
Nikolai Laubstein, Head of Category Management & Sales bei TD Synnex GCC
Seagate hat als erster Hersteller Festplatten mit HAMR-Technologie in Serie gefertigt. Bei diesen Festplatten sitzt ein winziger Halbleiterlaser im Schreibkopf, der durch das Erhitzen der PlatterOberfläche deren Speicherdichte erhöht. Der Speicherspezialist hat seine HAMR-Implementierung Mozaic 3+ getauft und damit bei 3,5-ZollHDDs bis zu 3,3 TB pro Platter erreicht. Nun kommt mit Mozaic 4+ die nächste Evolutionsstufe mit bis zu 4,4 TB pro Magnetscheibe bei SMRund 4 TB bei CMR-Festplatten. Bei zehn Plattern pro Laufwerk erreichen die neuen HAMR-Modelle damit 40 beziehungsweise 44 TB Kapazität. Derzeit werden die Platten dieser Evolutionsstufe bereits in großen Stückzahlen an Hyperscaler geliefert und dort eingesetzt, so Seagate. Sobald die Produktion weiter hochgefahren ist, sollen sie auch über den Channel verkauft werden.
Um die Speicherdichte weiter zu erhöhen, hat Seagate an einigen Stellschrauben der MozaicTechnologie gedreht. So wurde der im eigenen Haus entwickelte Laser im Schreibkopf verbessert, damit er die Magnetpartikel auf der Oberfläche
der Platter präziser erhitzen kann. Der Hersteller spricht von einem Plasmonic Writer der zweiten Generation. Dazu kommen Speichermedien, ebenfalls der zweiten Generation. Die einzelnen Nanopartikel in der Eisen-Platinlegierung auf der Oberfläche der ansonsten aus einem Spezialglas bestehenden Magnetscheiben sind nun dichter gepackt. Das erhöht die Speicherdichte. Damit die Informationen aus diesen kleiner gewordenen Magnetpartikeln – jedes entspricht einem Bit –auch korrekt gelesen werden, kommt ein Spintronic Reader der achten Generation zum Einsatz. Laut Seagate ist das der kleinste und empfindlichste Magnetfeldsensor in der Industrie. Dazu kommt ein bei Seagate selbst entwickelter Controller, der im 7-Nanometer-Verfahren hergestellt ist. Trotz höherer Performance soll er weniger Energie benötigen als der 12-Nanometer-Chip in den Mozaic-3+-Platten. Zudem biete er gemeinsam mit der neuen Firmware einen Schutz gegen potenzielle Angriffe mit Quantencomputern.
Während Festplatten aus Notebooks komplett und aus PCs weitgehend verschwunden sind, blei-
ben sie im Datacenter und vor allem bei Hyperscalern das vorherrschende Speichermedium. Laut Jason Feist, Senior Vice President, Cloud Marketing bei Seagate, sind derzeit etwa 87 Prozent aller Daten in der Cloud auf Festplatten gespeichert. Und er geht davon aus, dass sich dieser Anteil nicht wesentlich verändert. Gleichzeitig steige aber der Bedarf an Speicherplatz, vor allem getrieben durch KI-Anwendungen, massiv an. Die großen HAMR-HDDs sind seiner Ansicht nach ein Segen für die Hyperscaler: Mit Mozaic 4+ und bis zu 44 TB pro HDD können die Betreiber der Rechenzentren ein Exabyte an Daten auf 22.700 Festplatten speichern, die zusammen etwa 1,0 GWh an Leistung aufnehmen. Bei 30-TB-Platten sind dafür 33.330 HDDs mit einer Leistungsaufnahme von insgesamt rund 2,6 GWh notwendig. Gleichzeitig sinkt auch der Platzbedarf pro Exabyte dramatisch. Insgesamt soll sich so die Effizienz der Infrastruktur um etwa 47 Prozent verbessern. Als nächster Schritt steht für 2028 Mozaic 5+ mit mehr als 5 TB pro Platter in den Startlöchern. Eine Kapazität von mehr als 10 TB pro Magnetscheibe und damit die 100-TB-Festplatte soll im Jahr 2032 erreicht sein. Zudem soll die MozaicTechnik auch in HDDs mit geringerer Kapazität die Anzahl der Magnetscheiben verringern. Sinkende Kosten für die HAMR-Komponenten machen es dann beispielsweise möglich, eine 8-TBHDD mit zwei und eine 8-TB-HDD mit vier Magnetscheiben zu realisieren, was den Materialaufwand reduziert und die Platten günstiger macht.
Western Digital will im kommenden Jahr mit 44-TB-HAMR-HDDs nachziehen und hat schon erste Festplatten bei ausgewählten Kunden in der Qualifizierung. Bei der Speicherdichte hinkt der Hersteller allerdings im Vergleich zu Seagate noch hinterher: Western Digital benötigt für 44 TB derzeit noch 14 Magnetscheiben im Festplattengehäuse. Der Hersteller verspricht für seine HAMRHDDs eine ähnliche Haltbarkeit und Performance wie bei den bisherigen ePMR-Modellen. Ein von WD entwickelter und patentierter Vertical-Cavity-Surface-Emitting-Laser (VCSEL) soll die Kapazität in den kommenden Jahren noch deutlich steigern. Er ist laut Ahmed Shihab, Chief Product Officer bei Western Digital, im Vergleich zu den bislang verwendeten Edge-Emitting-Lasern kleiner und präziser. Zudem sei die Ausbeute bei der Produktion der Schreib-Lese-Köpfe besser. Mit dieser neuen Technologie will Western Digital bis 2030 die Flächendichte erhöhen und somit 10 TB
DUAL-PIVOT-TECHNOLOGIE VON WESTERN DIGITAL
Bei der Dual-PivotTechnologie kommen zwei Laufwerksarme zum Einsatz.
Im Gegensatz zur Dual-Actuator-Technologie von Seagate, bei der zwei unabhängige Sätze von Armen übereinander montiert sind, montiert Western Digital sie diagonal entgegengesetzt im Laufwerksgehäuse. Im Gegensatz zu herkömmlichen HDDs und auch Seagates Ansatz ist bei der Dual-Pivot-Technologie einer der Aktuatoren nur für die Oberseite und der andere nur für die Unterseite zuständig. So kann der Abstand der Platter vermindert und deren Anzahl pro HDD erhöht werden. Zudem beschleunigen die beiden Laufwerksarme die Zugriffe auf die Magnetscheiben und erhöhen damit die Leistung.
pro Platter erreichen, also HDDs mit 140 TB Kapazität. Gleichzeitig setzt Western Digital weiterhin auf ePMR-Festplatten und will deren Kapazität ebenfalls steigern. Noch dieses Jahr soll eine UltraSMR-HDD mit 14 Plattern und 40 TB Kapazität auf den Markt kommen. In zwei Jahren sollen dann sogar bis zu 60 TB möglich sein. Damit ist aber wohl das Limit der ePMR-Technik endgültig erreicht.
Etliche Storage-Hersteller, allen voran Everpure, bisher als Pure Storage bekannt, wollen mit verhältnismäßig günstigen QLC-SSD-Storage-Systemen die noch weit verbreiteten Hybrid-Flash-Systeme mit SSDs und HDDs überflüssig machen. Ein Argument für diese immer noch kostspieligeren All-Flash-Systeme ist deren höhere Performance. Western Digital will mit schnelleren HDDs kontern. Sie sollen das SATA-Limit von etwa 500 MB/s sogar deutlich übertreffen. Den Schlüssel dazu stellen zwei unterschiedliche Technologien dar: High Bandwidth Drive und Dual Pivot. Die High-Bandwidth-Drive-Technologie (HBDT) soll das gleichzeitige Lesen und Schreiben von Daten mit mehreren Köpfen gleichzeitig ermöglichen, was bisher noch nicht funktioniert. Die Triple-Stage-Actuator-Technologie mit drei
SUPER-HIGH-IOPS-SSD VON KIOXIA
Speziell für KI und High-Performance-Computing hat Kioxia die Super-High-IOPS-SSDs der GP-Serie entwickelt. Als Antwort auf die Storage-Next-Initiative von Nvidia soll der neue SSD-Typ den GPU-Speicherraum erweitern. Die GP-Serie basiert auf XL-Flash von Kioxia, einem 3D-SLC-NAND-Flash, der die Lücke zwischen dem HBM der GPU und herkömmlichen SSDs schließen soll. Der Hersteller verspricht deutlich höhere IOPS, eine feinere Granularität beim Datenzugriff (512 Byte) und einen niedrigeren Energieverbrauch als bei herkömmlichen TLC-SSDs.











Drehpunkten pro Laufwerksarm von Western Digital soll dies durch eine exaktere Positionierung ermöglichen. Zunächst soll noch dieses Jahr eine Verdoppelung der Bandbreite durch zwei simultane Zugriffe erfolgen, bis 2030 dann die 8-fache Bandbreite. Die Dual-Pivot-Technologie mit zwei diagonal entgegengesetzt Sätzen von Laufwerksarmen soll nicht nur Zugriffe beschleunigen, sondern gleichzeitig die Kapazität erhöhen. Die Kombination beider Technologien vervierfache den sequenziellen Durchsatz von den heute möglichen 300 MB/s auf zunächst bis zu 1.200 MB/s. Mit 8-Track-HBDT wären sogar bis zu 4.8 GB/s möglich.
Bei Seagate gibt es laut Feist derzeit keine vergleichbaren Pläne, was wohl auch damit zu tun hat, dass das Unternehmen im Gegensatz zu Western Digital auch SSDs produziert. Der CloudMarketingleiter von Seagate argumentiert damit, dass die HDD-Infrastruktur bei Hyperscalern oder anderen Betreibern großer Rechenzentren auf SATA-HDDs ausgelegt sei. Da es bei HDD-Speicher auf geringe Kosten ankomme, gebe es keine Bereitschaft für erhebliche Investitionen, um das zu ändern. Eine höhere Performance sei bei vielen Anwendungen gar nicht notwendig, da die Cloud-Anbieter mit Tiering dafür sorgen, dass Datenzugriffe mit hoher Bandbreite durch SSDs abgewickelt werden.
Bei SSDs liegt der Fokus derzeit vor allem auf einer weiteren Steigerung der Performance, die vor allem für KI-Anwendungen notwendig ist. Hier fallen auch die massiv gestiegenen Preise für NAND-Flash nicht so sehr ins Gewicht. Micron und Samsung haben bereits erste SSDs mit PCIExpress-6.0-Interface vorgestellt, obwohl es die dazu passenden Prozessoren noch gar nicht gibt.

Denn AMDs Epyc Venice und Intels Xeon der Diamond-Rapids-Generation sollen erst in der zweiten Jahreshälfte auf den Markt kommen. Micron verspricht für die PCIe-Gen6-SSD 9650 eine sequenzielle Lesegeschwindigkeit von 28.000 MB/s, doppelt so viel wie bei einer PCIe-Gen5SSD. Die Schreibrate soll mit bis zu 14.000 MB/s um 40 Prozent höher sein. Ebenso zugelegt hat die Leistung bei Random Read und Write mit 5,5 MIOPS und bis zu 900 KIOPS. Hier liegt die Steigerung laut Micron bei 67 beziehungsweise 22 Prozent. Die TLC-SSD wird in den Formfaktoren E1.S mit maximal 15,36 TB Kapazität und E3.S angeboten. Hier sind bis zu 30,72 TB möglich. Die kompakten E1.S gibt es auch in einer für Flüssigkeitskühlung ausgelegten Variante.
Samsung verspricht für die PCIe-6.0-SSD PM1763 sogar eine sequenzielle Schreibrate von bis zu 21.000 MB/s und eine Lesegeschwindigkeit von bis zu 28.400 MB/s. Produziert wird die bis zu 64 TB große PCIe-Gen6-SSD ebenfalls in den Formfaktoren E1.S und E3.S. Zusätzlich wird es sie auch im U.2-Format geben, allerdings nur mit Unterstützung für PCIe Gen5. Die für Flüssigkeitskühlung ausgelegte E1.S soll in entsprechenden Storage-Systemen mit einer 1,8-fach besseren Energieeffizienz arbeiten. Zudem hat der KIBoom Samsung auch dazu bewogen, den schon beerdigten Z-NAND eine neue Chance zu geben. Der Speicher konnte sich wegen des hohen Preises und einer vergleichsweise geringen Kapazität nicht durchsetzen. Mit einer direkten Anbindung an die GPU könnte er eine Renaissance erleben.
Mehr unter: https://voge.ly/Storage_Verbrauch/
Autor: Klaus Länger
BILD:KIOXIA
Bei der Speichertechnik von Piql werden auf einem aus PET hergestellten Film sowohl analoge als auch digitale Informationen abgelegt; letztere in Form von Bitmustern ähnlich wie bei einem QR-Code.
Das Speichern von Daten über einen sehr langen Zeitraum hinweg ist mit magnetischen Speichern wie HDD und Tape oder Halbleiterspeichern wie SSDs nicht möglich, ohne die Daten umzukopieren. Die HDDs und SSDs halten nur einige Jahre, Tapes bis zu 30 Jahre. Die Lösung für dieses Problem sind optische Speichertechnologien, wie sie Piql, Cerabyte und Microsoft entwickelt haben. Hier sollen die gespeicherten Daten für wenigstens 1.000 Jahre sicher erhalten bleiben.
Die norwegische Firma Piql kommt aus der Filmindustrie und hat 2004 einen Echtzeit-Recorder für 35-mm-Film vorgestellt. Da in der Filmproduktion inzwischen überwiegend mit digitalen Kameras und Medien gearbeitet wird, hat Piql die Datenarchivierung als neues Geschäftsfeld entdeckt: Als Datenträger dient ein aus robustem PET hergestellter Schwarzweißfilm, der im Piql Writer mittels einer LED und einem Digital Mirror Device belichtet wird. Die Daten können sowohl analog in Form von Bildern und lesbarem Text gespeichert werden als auch digital in einer einem QR-Code ähnelnden Matrix. Die maximale Datenmenge pro Filmrolle gibt der Hersteller mit 120



GB an, die Schreibrate mit 50 MB/s. Zum Auslesen dient der Piql Reader, für den die Firma auch Baupläne bereitstellt. Im Prinzip genügt aber auch ein Mikroskop mit Bilderfassung. Die nötigen Informationen zur Dekodierung der QR-Codes liegen dabei in Klartext mit auf dem Film, einschließlich der Quellcodes für die Software. Das Belichten der Filme erledigt Piql als Service, auf Wunsch mit zusätzlichem Online-Storage der gespeicherten Daten. Die in stabilen Boxen untergebrachten Filme werden an die Kunden verschickt. Gegen Gebühr können sie auch in automatisierten Lagern oder sogar dem verbunkerten Arctic World Archive untergebracht werden.
Das 2022 gegründete Startup Cerabyte hat bisher erst ein Pilotsystem fertiggestellt, das die Funktionstüchtigkeit der von ihm entwickelten Ceramic-Nano-Memory-Technologie (CNM) belegt. Das deutsch-österreichische Unternehmen nutzt als Speichermedium flexible Glasplatten mit einer Dicke von nur 100 µm, die mit einer 10 µm dünnen Nano-Keramikschicht versehen sind. Ein ultrakurz gepulster Laser, ein Digital Mirror Device – ähnlich dem in einem DLP-Projektor – und
eine Mikroskop-Optik erzeugen winzige Löcher in der Keramikschicht, die eine QRCode-ähnliche Matrix bilden. Das Schreiben einer Matrix – auf den 9 x 9 cm großen Platten finden mehrere Platz – erfolgt in einem Rutsch. Ein ganzer Stapel der Glasplatten mit zusammen etwa einem TB Speicherkapazität findet in einer Cartridge Platz, deren Abmessungen denen einer LTO-Cartridge entsprechen. So lassen sich deren automatisierte Aufbewahrungssysteme verwenden. Die Platten selbst sollen unempfindlich gegen extreme Hitze sowie Kälte sein. Sie können auch Informationen im Klartext über die Dekodierung der QRCodes enthalten. Der Preis pro TB soll unter dem von Tape liegen, verspricht Cerabyte. Aktuell wird ein Pilotsystem für erste Kunden validiert, mit einem PB Gesamtkapazität pro Rack, 100 MB/s Datenrate und 90 Sekunden Zugriffszeit bis zum ersten Byte. Dabei kommen mehrere Schreib-/Leseköpfe zum Einsatz. Gelesen wird mit Mikroskop-Optik und einem Hochgeschwindigkeits-Bildsensor. Ein FPGA sorgt für die parallele Verarbeitung. Fortschritte in der Laser- und der Bilderkennungstechnologie wie etwa der Einsatz eines CMOS-Arrays sollen Kapazität und Datenrate erheblich steigen lassen. Bis 2030 will das Unternehmen bis zu 100 PB in einem Rack unterbringen und die Datenrate auf mehr als 2 GB/s steigern. Das liegt deutlich über der von LTO und HDDs. Aktuell hat die TU Wien gemeinsam mit Cerabyte einen QRCode mit der Fläche von 1,98 Quadratmikrometern geschrieben und wieder gelesen: Ein Weltrekord für den bisher kleinsten QR-Code, der jemals produziert wurde. Dabei kamen fokussierte Ionenstrahlen und ein Elektronenmikroskop zum Einsatz.
Microsoft Research, die für Grundlagenforschung zuständige Abteilung des Konzerns, arbeitet mit Project Silica ebenfalls an einer Langzeit-Datenspeicherung auf Glas. Hier soll das Speichermedium sogar 10.000 Jahre überstehen. Zuletzt war es um das 2017 erstmals öffentlich erwähnte Projekt still geworden. Im Februar 2026 vermeldete die Microsoft-Forschungsgruppe in der Zeitschrift Nature erhebliche Fortschritte sowohl bei den Kosten für das Speichermedium als auch bei der Datenrate
beim Schreiben. Die Daten werden hier mit einem Femtosekundenlaser als Voxel in einem dreidimensionalen Gittersystem gespeichert. Ein Bitstrom mit zusätzlichen Bits für die Fehlerkorrektur wird in Symbole umgewandelt. Die Voxel, die diese Symbole repräsentieren, nehmen mehr als ein Bit auf. Sie werden dabei in horizontalen Sektoren und vertikalen Tracks abgelegt. Geschrieben werden die Symbole Schicht für Schicht, von unten nach oben. Anfangs war dafür als Speichermedium ein hochreines und teures Quarzglas (Fused Silica) notwendig. Nun reicht günstiges Borosilikatglas aus, das beispielsweise für mikrowellentaugliches Geschirr verwendet wird. In einer zwei Millimeter dicken Glasscheibe mit 7,5 cm Kantenlänge können so in 258 Layern rund zwei TB an Daten gespeichert werden. Bei Quarzglas waren noch 301 Layer mit 4,8 TB Kapazität möglich. Dafür funktioniert das Schreiben der Daten im Borosilikatglas viel schneller. Die Forscher nutzen nun ein Verfahren, bei dem anstelle der Polarisation die Phasenänderung des Glases modifiziert wird. Um ein Phasen-Voxel zu erstellen, ist nur ein einzelner Laserpuls mit modulierter Energie notwendig, statt viele, wie beim vorhergehenden Verfahren. Zudem wird der Laserstrahl durch ein Objektiv in vier unabhängig voneinander modulierte Strahlen aufgeteilt, was die Schreibrate auf 65,9 Mbit/s erhöht. Fortschritte vermelden die Microsoft-Forscher auch beim Lesen der Daten, das mit einem Weitfeldmikroskop und einer sCMOS-Kamera erfolgt. Zuvor waren dafür vier Kameras notwendig. Beim Erkennen der Symbole in den Bildern hilft Machine Learning mit einem Convolutional Neural Network (CNN). Anschließend werden die Symbole wieder dekodiert. Das Project Silica ermöglicht zwar eine hohe Speicherdichte, benötigt dafür aber eine aufwendigere Technik beim Auslesen.




Mehr unter: https://voge.ly/ langzeitarchivierung/ Autor: Klaus Länger
Die Leseeinheit von Microsofts Silica-Projekt im Labor.
Project Silica von Microsoft Research ist derzeit noch ein reines Laborsystem für die Forschung, wie der Aufbau der Leseeinheit zeigt. Bis zur Serienreife werden wohl noch einige Jahre ins Land gehen.
Cerabyte speichert Daten in einer QR-Code ähnlichen Matrix.
Cerabyte wird vom Europäischen Innovationsrat (EIC) gefördert und ist ein gutes Stück näher an der Serienreife. Das fertige System soll automatisiert funktionieren und sich in LTO-Bibliotheken einbinden lassen.
BILD: VOGEL
BILD:
Bei dem IBM-KI-Assistenten FlashSystem.ai wird die AI-Intelligenz On-Premises in einem Container bereitgestellt, die LLMModelle und GPUs laufen in der IBM-Cloud. Nutzerdaten werden dabei nicht übertragen.
Menschliche Administratoren stoßen bei der Verwaltung komplexer Speichersysteme an ihre Grenzen. Spezialisierte KIAgenten müssen daher die Transformation hin zur vollautomatisierten, prädiktiven Orchestrierung übernehmen. Sie erfassen und kartografieren erstens systematisch fragmentierte Datenbestände und schaffen Transparenz, was manuell Jahre dauern würde. Richtlinien werden zweitens systemübergreifend aktiv durchgesetzt. Jede Aktion wird drittens für ComplianceAudits lückenlos protokolliert. Viertens identifizieren Agenten durch kontinuierliches Monitoring Anomalien, unbefugte Zugriffe oder Policy-Verstöße proaktiv.
Traditionelle Anbieter werden zunehmend um solche ergänzt, die ihre Infrastruktur über das Model Context Protocol (MCP) einbinden. MCP-Server abstrahieren proprietäre APIs, ohne bestehende Schnittstellen zwingend zu ersetzen. Ein solcher Server übersetzt spezifische Metriken von SAN- oder NAS-Systemen – wie Latenzen, IOPS oder Füllstände – in ein für Large
Language Models (LLM) lesbares Format. Das Modell muss die Hardware-Logik nicht mehr kennen, sondern kommuniziert standardisiert mit dem MCP-Server, der Steuerungswerkzeuge bereitstellt. So kann ein Agent direkt Befehle für das Provisioning oder Snapshots auslösen. Der MCP-Server entscheidet, welche technischen Metadaten an ein externes LLM gesendet werden. Zudem kann er kritische Aktionen, wie das Löschen von Daten, blockieren oder eine menschliche Freigabe erzwingen.
Der Atlassian Rovo MCP Server ist ein Beispiel dafür. Atlassian stellt hierbei eine Governance- und Workflow-Ebene über der physischen Infrastruktur bereit. Während Agenten der Hardware-Hersteller Datenblöcke optimieren, verbindet Rovo in Lösungen wie Jira, Confluence und Compass KI-Agenten mit der Software-Infrastruktur auf Ebene des InfrastructureCodes. Über Compass agiert der Agent als Storage-Auditor, der Cloud-Komponenten den jeweiligen Teams zuordnet. Bei einem
Ralf Colbus, Storage Chief Strategist DACH bei IBM
beispielsweise durch HPE InfoSight gemeldeten Hardware-Ausfall kann ein mit Atlassian verbundener Agent sofort Jira-Vorgänge erstellen, Teams benachrichtigen und die Dokumentation aktualisieren. Sicherheitsrichtlinien legen fest, auf welche technischen Metadaten KI-Agenten zugreifen dürfen, anstatt dass der MCP-Server kundenseitig verwaltete Schlüssel (CMK) direkt steuert. „Wir sind fest davon überzeugt, dass großartige Teams nicht in geschlossenen Systemen arbeiten, sondern auf offenen Plattformen. Für uns ist MCP der Weg, dieses offene Ökosystem in das KI-Zeitalter zu bringen“, erklärte Sanchan Saxena, Head of Product bei Atlassian, gegenüber IT-BUSINESS.
HPE seinerseits verfolgt einen zweigeteilten Ansatz über InfoSight und GreenLake Intelligence. InfoSight agiert als hardwarenaher Autopilot, der Billionen Telemetriedatenpunkte nutzt, um Ressourcenkonflikte auf Block-Ebene prädiktiv aufzulösen. GreenLake Intelligence fungiert als übergeordnete Flugsicherung: Es koordiniert ein Agenten-Mesh über Domänen hinweg – Storage, Compute, Netzwerk, Observability, Kosten und Nachhaltigkeit –, um die gesamte IT in einen autonomen Betrieb zu überführen. „Storage-Management allein reicht nicht“, so Florian Bettges, Head of Hybrid Cloud Category bei HPE, „es muss Teil eines durchgängigen Datenmanagements für KI sein.”
IBM liefert mit der neuen Generation an Flashsystemen die kostenfreie Plattform FlashSystem.ai. „Dabei wird die AI-Intelligenz on-Premise in einem Container deployed, die LLM-Modelle und GPUs laufen in der IBM Cloud“, erläuterte Ralf Colbus, Storage Chief Strategist DACH bei IBM. Für den Nutzer fielen keine zusätzlichen Kosten an, es würden keine Nutzerdaten übermittelt und der Anwender könne dem System in natürlicher Sprache Befehle erteilen. Das System sei so designt, dass der Nutzer keinen Schaden aus Versehen anrichten könne und lerne permanent dazu.
In der Welt von NetApp bildet Active IQ das zentrale Gehirn der Data Fabric. Als Cloudbasierte Engine nutzt sie einen digitalen
Zwilling der Kundeninfrastruktur für Simulationen. Da das Betriebssystem ONTAP hybrid über Cloud- und On-PremisesGrenzen hinweg läuft, kann ein Active-IQbasierter Agent Optimierungen global steuern, wobei die Datenhoheit stets lokal verbleibt. „Mit Active IQ und ONTAP schaffen wir eine softwaredefinierte Intelligenz, die Storage-Management erstmals wirklich hybrid denkt: Optimierungen laufen global, die Datenhoheit bleibt lokal“, erklärt Johannes Pape, Head of AI EMEA & LATAM bei dem Hersteller.
Everpure (ehemals Pure Storage) ermöglicht mit Everpure Fusion Interoperabilität zwischen verschiedenen Umgebungen, indem es das Betriebssystem Purity OS mit der Managementebene Fusion kombiniert. „Für die Effizienz eines Rechenzentrums ist es erforderlich, so viele Funktionen wie möglich zu automatisieren – nicht nur für einen einzelnen Speicherendpunkt, sondern für die gesamte Infrastruktur“, erklärte Markus Grau, Enterprise Architect im Office of the CTO bei Everpure. Als Erleichterung für das Management der Systeme soll ein KI-Chatbot das IT-Personal unterstützen. Er hat Zugriff auf Handbücher, Support-Anfragen und Telemetriedaten. Infinidat ist durch neuronale Netze im Array auf Cyber-Souveränität spezialisiert.
Dell erweitert seine AI Factory mit AgenticRAG-Lösungen, bei denen PowerScale als KI-optimierte Plattform dient, während die Orchestrierung in der Compute-/Kubernetes-Schicht erfolgt. Zusammenfassend lässt sich festhalten, dass KI-Agenten eine neue, fundamentale Automatisierungsschicht bilden. Christian Winterfeldt, Senior Director Data Center Sales bei Dell Technologies DACH, erklärt dazu: „Der eigentliche Mehrwert von KI-Agenten im StorageUmfeld entsteht dort, wo sie Infrastruktur, Daten und Analytik zusammenführen und so Entscheidungen im Betrieb zunehmend datengetrieben und automatisiert unterstützen.“
Mehr unter: https://voge.ly/HPE_Agent
Autor: Dietmar Müller
Wir sind fest davon überzeugt, dass großartige Teams nicht in geschlossenen Systemen arbeiten, sondern auf offenen Plattformen. Für uns ist MCP der Weg, dieses offene Ökosystem in das KI-Zeitalter zu bringen.
Für die Effizienz eines Rechenzentrums ist es erforderlich, so viele Funktionen wie möglich zu automatisieren – nicht nur für einen einzelnen Speicherendpunkt, sondern für die gesamte Infrastruktur.
Sanchan Saxena, Head of Product bei Atlassian
Markus Grau, Enterprise Architect im CTO-Office bei Everpure
BILD: ATLASSIAN
BILD: EVERPURE
Anwälte, Ärzte oder Steuerberater, die Künstliche Intelligenz in ihrem Unternehmen einsetzen wollen, haben häufig Sicherheitsbedenken. Wer ausschließen will, dass sensible Unternehmensdaten in fremde Hände geraten, kann zu einem privaten Cloud-Speicher greifen. Durch die direkte Integration von KI in diesem privaten Cloud-Speicher können Daten lokal abgerufen, analysiert und abgelegt werden. Die NAS-Systeme sind so mehr als ein passiver Speicherort und Daten werden zu aktiven digitalen Ressourcen.
Das NASync iDX6011 und das iDX6011 Pro von Ugreen sind KI-NAS-Systeme, die mit starken Prozessoren und großem Arbeitsspeicher ausgestattet sind. Auf den CPUs läuft ein lokales LLM, das den Zugriff auf die eigenen Daten einfacher und produktiver machen soll. Sie verfügen über sechs Einschübe für 3,5-Zoll-Laufwerke bis zu 30-TBHDD. Zusätzlich gibt es zwei M.2-Slots für SSDs, die als Cache oder zusätzlicher Speicherplatz dienen. Insgesamt kann der kombinierte Massen-
Laut Andy Chuang, Product Manager bei QNAP, ist dieses NAS die Lösung für Unternehmen, die schnelle, skalierbare und agile Infrastrukturen benötigen, um ihre datenintensiven Workloads erfolgreich zu bewältigen.
speicher bis zu 196 TB groß sein. Dabei steckt im NASync iDX6011 Pro ein Core Ultra 7 255H der Arrow-Lake-Familie mit sechs P- und insgesamt 10 E- und LPE-Cores. Er liefert eine KI-Leistung von bis zu 96 TOPS und kann auf 64 GB LPDDR5X als Arbeitsspeicher zugreifen. Im günstigeren NASync iDX6011 arbeitet ein Core Ultra 5 125H aus der Meteor-Lake-Generation mit insgesamt 14 Cores, davon vier P-Cores, und einer KI-Leistung von 33 TOPS. Der LPDDR5X-Arbeitsspeicher ist 32 oder 64 GB groß. Im Pro-Modell ist zusätzlich ein OCuLink-Port integriert, über den ein externes GPU-Dock für eine PCI-Express-Grafikkarte eingebunden werden kann. Das soll zusätzliche KI-Leistung liefern. Ugreen hat mit dem LinkStation eGPU-Dock selbst eine passende Lösung
Im Ugreen NASync iDX6011 Pro kann der Arrow-LakeProzessor auf 64 GB LPDDR5X Arbeitsspeicher zugreifen. Der Massenspeicher kann mit sechs 3,5-Zoll-HDDs und zwei M.2-SSDs auf bis zu 196 TB ausgebaut werden.
im Portfolio. Für die Netzwerkanbindung bieten beide NAS-Modelle jeweils zwei 10GbE-Ports. Zudem verfügen sie über zwei Thunderbolt-4-Ports für die schnelle Verbindung zu externen SSDs. Ein HDMI-Ausgang ist ebenfalls an Bord.
Ugreen hat außerdem das UGOS-Pro-Betriebssystem um fünf lokale KI-Funktionen ergänzt. Dazu zählen: eine KI-unterstützte Suchfunktion, Uliya-KI-Chat, ein AI-Album, Voice Memos sowie AI File Organization. Der Uliya KI-Chat nutzt ein integriertes LLM, das Fragen zu lokalen Daten beantwortet, Zusammenfassungen erstellt und eine lokale Wissensdatenbank aufbauen kann. Das AIAlbum nutzt die KI, um Bilder mittels natürlicher Sprache zu finden und ähnliche Bilder zu identifizieren. Zudem werden Gesichter, Tiere, Objekte sowie dargestellte Szenen erkannt und automatisch in Kategorien einsortiert. Voice Memos transkribiert Sprachaufnahmen und erstellt Zusammenfassungen. AI File Organization nutzt KI für das automatische Sortieren gespeicherter Daten, um die Suche zu beschleunigen. Die gesamte Verarbeitung erfolgt lokal, sodass Daten laut Hersteller privat bleiben und nicht auf Servern von Drittanbietern gespeichert werden.
QNAP hat mit TVS-AIh1688ATX auch ein KI-NAS vorgestellt. Im Inneren arbeiten neue Intel-CoreUltra-Prozessoren (bis zum Core Ultra 9 mit 24 Cores, 24 Threads und 5,6 GHz oder Core Ultra 7 mit 20 Cores und 20 Threads) und eine NPU. Damit erreicht das KI-NAS eine Gesamtleistung von bis zu 36 TOPS. Es unterstützt bis zu 192 GB Arbeitsspeicher. Entwickelt wurde es laut Hersteller für KI-gestützte Bild- und Videoanalyse, Virtualisierung, Multimedia-Verarbeitung und groß angelegte Backups. So bietet das TVS-AIh1688ATX 12 SATA-HDD-Einschübe und 4 U.2-NVMe/ SATA-SSD-Steckplätze. Mit Unterstützung für High-Availability-(HA)-Architektur, Thunderbolt 5 und 100GbE-Netzwerkerweiterung soll es eine leistungsstarke Edge-KI-Storage-Plattform für Unternehmen sein. Integriert sind zudem zwei 2,5GbE- und zwei 10GBASE-T-Ports. Das Betriebssystem QuTS hero bietet laut QNAP EnterpriseFunktionen wie Selbstheilung, ZIL-Stromausfallschutz, WORM für unveränderliche Daten,
Inline-Deduplizierung und nahezu unbegrenzte Snapshots und SnapSync für Disaster Recovery.
Mit Zettlab ist ein neuer Anbieter von KI-NASSystemen im Markt aufgetaucht. Auf der CES 2026 hat sich der chinesische Hersteller für seine AI-NAS-Geräte gleich einen Innovations-Preis eingehandelt. Dabei setzt Zettlab laut eigenen Angaben auf leistungsstarke KI-Speicherlösungen mit ansprechendem Design. Derzeit hat der Neuling vier KI-NAS-Modelle am Start: das Zettlab D4, Zettlab D6, Zettlab D6 Ultra und Zettlab D8 Ultra. Sie unterscheiden sich zunächst in der Anzahl der Festplatten-Slots, wobei die Produktbezeichnung die mögliche Anzahl der Einschübe verrät. Unterschiedlich sind ferner nicht nur der maximale Speicher (bis zu 200 TB beim D8 Ultra), sondern auch der Prozessor. Während in den kleineren Modellen ein Rockchip RK3588 (mit 8 Cores und 6 TOPS NPU) arbeitet, werden die Ultra-Geräte vom Intel Core Ultra 5 125H mit 14 Cores, 18 Threads mit einer Leistung von 34 TOPS angetrieben. Unterstützt werden bis zu 32 GB DDR5. Als Betriebssystem ist ZettOS an Bord, das KI-Funktionen wie KI-Suche oder Transkriptionen ermöglicht. Die Ultra-Modelle bieten zudem lokale LLMs.
Der Branchen-Riese Synology hat bisher noch keine NAS-Lösung mit integrierter NPU ins Rennen gebracht. Allerdings hat der Hersteller mit der AI Console KI-Funktionalitäten in die Synology-Umgebung eingeführt. Sie soll Anomalien in Datenströmen erkennen, Sicherheitsevents analysieren und Ressourcenoptimierung unterstützen. Ziel ist eine automatisierte Entlastung der Administratoren durch Mustererkennung und Handlungsempfehlungen. In Verbindung mit Active Insight entstehen Szenarien, in denen Ransomware-Attacken schneller erkannt und durch sofortige Snapshots eingedämmt werden können. Die Zuverlässigkeit solcher Analysen hängt allerdings sehr stark von der Trainingsbasis ab.
Mehr unter: https://voge.ly/KI-NAS/ Autor: Margrit Lingner
Auf einem T-Shirt für IT-Nerds steht der Spruch: „Es gibt keine Cloud, es gibt nur die Server fremder Leute!“ Er fasst das Misstrauen vieler IT-Verantwortlicher prägnant zusammen: Wer Kontrolle und Vertraulichkeit geschäftskritischer Daten und Workloads anstrebt, denkt über eine Rückverlagerung nach. Neben berechtigten Sicherheits- und Compliance-Bedenken spielt das menschliche Bedürfnis nach Besitz und Vorsorge eine Rolle – das „Hamster-Phänomen“: Kritisches wird lieber im eigenen Unternehmen gehalten. Dem stehen die wirtschaftlichen und betrieblichen Vorteile der Public Cloud gegenüber, etwa Skalierbarkeit, Agilität und oft geringere Fixkosten. Fehlendes Fachpersonal im eigenen Haus fließt ebenfalls in die Entscheidung ein. Technische Fragen betreffen, welche Daten Souveränität oder niedrige Latenz erfordern; FinOps-Überlegungen klären, welche Workloads kosteneffizient in der Cloud verbleiben sollten.
Wie ist der Trend zu beurteilen? Bei der Unternehmensberatung Microfin, die unter anderem derlei IT-Themen behandelt, beobachtet man derzeit keine flächendeckende „Rolle rückwärts aus der Cloud“, aber sehr wohl gezielte Repatriierungen einzelner Workloads – „und vor allem eine deutlich nüchternere Betrachtung von ‚Cloud-first‘“,
so Dr. Julia Pergande, Managing Principal bei Microfin. Typische Auslöser sind aus ihrer Sicht die Kostenfrage, Performance- und Latenzgründe, Überlegungen zur Compliance und zur Souveränität sowie im Hinblick einer übergeordneten Vendor-Strategie.
Was die Kosten angeht, haben einige Unternehmen nach der Migration festgestellt, dass schlecht optimierte oder nicht cloud-native Workloads in der Public Cloud erheblich teurer laufen als geplant – insbesondere bei hoher und wenig elastischer Grundlast. In solchen Fällen kann eine Rückführung in ein eigenes oder gehostetes Rechenzentrum wirtschaftlich sinnvoll sein. Zu den Performance- und Latenzgründen führen echtzeitnahe Produktionssysteme, spezialisierte OTUmgebungen oder Anwendungen mit sehr hohen Datenvolumina. Diese können von On-Premisesoder Edge-nahen Architekturen profitieren. In Einzelfällen entscheiden sich Unternehmen aus Gründen der Compliance und Souveränität bewusst gegen die Public Cloud, weil sich regulatorische Anforderungen oder interne Risikobewertungen anders entwickelt haben als erwartet – oder weil der notwendige Governance- und SecurityAufwand in der Cloud höher ist als zunächst angenommen. Manche Unternehmen stellen fest,
Das Thema Cloud-Souveränität spielt derzeit eine große Rolle.
BILD: MIDJOURNEY / KIGENERIERT
dass sie zu stark in die proprietären Services eines Hyperscalers eingestiegen sind und suchen durch Repatriierung in Kombination mit Standardplattformen (zum Beispiel Kubernetes-On-Premises) wieder mehr Unabhängigkeit im Sinne einer übergeordneten Vendor-Strategie. Insgesamt sei es daher präziser, von „Right-Sourcing“ zu sprechen: Workloads werden dorthin bewegt, wo sie fachlich, technisch, wirtschaftlich und regulatorisch am besten aufgehoben sind – und das könne mal die Public Cloud, mal ein europäisches Rechenzentrum, mal das eigene Datacenter sein. Erfolgreich seien die Unternehmen, die diese Entscheidungen nicht dogmatisch, sondern datenbasiert und regelmäßig überprüfen. Workloads werden dorthin bewegt, wo sie fachlich, technisch, wirtschaftlich und regulatorisch am besten aufgehoben sind – und das kann mal die Public Cloud, mal ein europäisches Rechenzentrum, mal das eigene Datacenter sein.
Eine „Massenflucht aus der Cloud“ kann auch Fabian Dörk, Cloud Services Director bei Claranet, nicht erkennen, wohl aber eine gezielte Repatriierung von Workloads. Wichtigster Einflussfaktor bei solchen Entscheidungen ist laut Dörk vor allem die Kostenfrage: Bei stabilen, berechenbaren Lasten ist das eigene Blech oft günstiger, so der Manager. Auch sieht er mitunter Anforderungen an extrem niedrige Latenzen, wie beim Edge Computing. Es sei kein „Zurück in die Vergangenheit“, sondern vielmehr eine Professionalisierung der Infrastruktur-Verteilung. In bestimmten Bereichen, wie KI, führt mitunter jedoch kein Weg an den Hyperscalern vorbei, auch dies spielt in die Repatriierungsfrage hinein. Unternehmen entscheiden sich demnach heute nicht mehr für einen Serverstandort, sondern für ein „Betriebssystem der Innovation“. Wer auf Azure OpenAI oder Amazon Bedrock setzt, baut seine gesamte Datenpipeline und Applikationslogik um diese proprietären Schnittstellen (APIs) herum, erläutert Dörk. Im Zweifel siegt im deutschen Mittelstand aktuell der „Time-to-Market“. Heißt: Man nimmt die Abhängigkeit in Kauf, um bei der KI-Transformation nicht den Anschluss an den Weltmarkt zu verlieren.
Ein gemischtes Bild zeigt sich, wenn man Uwe Geier, VP Cloud Solutions bei Ionos fragt, ob es seiner Meinung nach eine Repatriierung von Daten und Workloads ins eigene Rechenzentrum gibt und welche Faktoren solche Entscheidungen beeinflussen, zeigt sich, dass die Wirklichkeit mit-
KOMMANDO ZURÜCK!
Eine Cloud kann auch im eigenen Datacenter betrieben werden.
Repatriierung von Daten und Workloads ins eigene Rechenzentrum bedeutet, dass eine strategische Rückverlagerung von Anwendungen, Datenbanken und Speicher aus der Public Cloud ins eigene Rechenzentrum vorgenommen wird. Typischer Ablauf: Bestandsaufnahme und Analyse von Abhängigkeiten, Performance- und Compliance-Anforderungen; Auswahl einer Migrationsstrategie; stufenweiser Plan mit Pilot, Synchronisation, Netzwerkkonfiguration, Sicherheit, Tests und Rollback. Ziel ist mehr Kontrolle, Datensouveränität, stabile Kosten und bessere Performance bei begleitendem Change-Management.
unter eine Sense für Ideale ist. „Nein, das kann keine ernsthafte Perspektive sein“, so Geier. Bei reinem On-Premises-Denken steigen demnach die TCO pro Workload aufgrund hoher Infrastrukturkosten und des Investitionsbedarfs massiv an. Der TCO pro Workload („Total Cost of Ownership“, deutsch: Gesamtkosten des Betriebs) bezeichnet alle direkten und indirekten Kosten, die für den Betrieb einer einzelnen Anwendung oder Workload über ihren Lebenszyklus anfallen – etwa Infrastruktur und Lizenzen, Betriebspersonal, Energie, Netz, Wartung, Migration sowie Ausfallund Sicherheitskosten.
Fachkräftemangel ist ein weiterer, bremsender Einflussfaktor, der einer Datacenter-Repatriierung entgegensteht: Den meisten Unternehmen würden perspektivisch die Fachkräfte fehlen, führt Geier aus. Zudem steige die TCO pro Workload bei reinem On-Prem-Denken aufgrund hoher Infrastrukturkosten und des Investitionsbedarfs massiv an. „Auch setzt NIS2 Erfahrungskurven voraus, die es in der Breite schlicht nicht
DATEN UND WORKLOADS
Daten sind ruhende Informationen – Dateien, Datenbanken, Logs oder Backups; sie betreffen Integrität, Archivierung, Zugriffsrechte und Compliance. Workloads sind laufende Rechenaufgaben: Anwendungen, Dienste oder Jobs mit CPU-, Speicher- und Netzwerkbedarf sowie Anforderungen an Latenz, Skalierung und Verfügbarkeit. Deshalb unterscheiden sich Treiber (Compliance vs. Performance) und Migrationsaufwand erheblich. Bei Migrationen sollten daher Datenund Workload-Kriterien separat geplant und bewertet werden.
gibt“, so der Manager und ergänzt: „Wenn verteilte Rechenprozesse ‚at-edge‘ oder kollaborativ agierende KI-Agenten über Backends gesteuert werden müssen, führen On-Premises-Lösungen zu spürbaren Latenzproblemen.“
Eine Abkehr von der Cloud beobachtet kein relevanter Marktakteur. Auch bei Plusserver beobachtet man eher eine Neugewichtung statt eine generelle Repatriierung des Daten- und Verarbeitungsgeschehens, berichtet Peter Höhn, CCO des Unternehmens. Höhn spricht von „selektiver Repatriierung, aber keine generelle Rückkehr zu On-Premises“. Es sei eine Neugewichtung, bei der es häufig um Kostenkontrolle, Egress-Gebühren oder Compliance-Anforderungen geht. „Unternehmen holen bestimmte sensible Workloads zurück oder verlagern sie in souveräne Cloud-Umgebungen“, so der Manager. Ein spannender Trend gehe außerdem in Richtung einer Colocation mit direkter Anbindung an eine souveräne Cloud. „So sparen sich Unternehmen das eigene Rechenzentrum, können aber ihre eigene Hardware in einer abgeschirmten Umgebung nutzen, und der Weg in die Cloud bleibt für bestimmte Workloads jederzeit offen“, sagt Höhn.
Am Ende des Tages bleibt die vielbeschworene Repatriierung ins eigene Datacenter selektiv, kein Massenphänomen. Technisch sind souveräne Alternativen heute greifbar — Open-Source-Projekte, Gaia-X und der Sovereign Cloud Stack liefern konkrete Bausteine, um Datenhoheit und Interoperabilität zu stärken. Schwieriger als die Technik sind jedoch die juristischen Fragen: Der jüngere Angemessenheitsbeschluss der EU-Kommission hat den transatlantischen Datentransfer erleichtert, und der US-Cloud Act greift formal vornehmlich bei schweren Straftaten; trotzdem werden Bedenken über Drittstaatenzugriffe immer wieder
Daten und Workloads haben cloudbedingt oft weite Reisen vor sich.
laut. Dabei ist eines klar zu gewichten: die Angst vor einem pauschalen „Killswitch“, der die US-Cloud-Infrastruktur vom Rest der Welt abschneidet, ist eine reine Angstphantasie – technisch, wirtschaftlich und geopolitisch wäre eine derartige Abkoppelung undenkbar. Doch trotz dieser Sicherheit heißt es nicht, dass juristische Risiken völlig irrelevant sind; Datenschutzbehörden, DSGVO-Pflichten und Datenschutz-Folgenabschätzungen halten das Thema am Köcheln. Und auch Anbieter aus der EU profitieren von dieser Erzählung.
Entscheidend ist daher eine nüchterne, methodische Abwägung: real quantifizierbare Risiken von spekulativen Worst-Case-Szenarien trennen und technologische, rechtliche und wirtschaftliche Bewertungen zusammenführen — inklusive externer Rechtsprüfung, Threat- und Impact-Modelling, belastbarer TCO- und Exit-Kalkulationen. Prüfen, ob Maßnahmen wie lokale Key-Verwaltung, Netzsegmentierung, Hybrid- oder Colocation-Setups und souveräne Cloud-Services die Risiken tatsächlich mindern. Praktisch empfiehlt sich ein gestuftes Vorgehen mit Datenklassifikation, Piloten, klaren Vertragsklauseln zu Zugriff und Audits sowie wiederkehrenden Reviews: Nur dort repatriieren, wo der kombinierte Nutzen die Kosten und Restrisiken eindeutig übersteigt.
Eine Repatriierung von Daten und Workloads ins eigene Rechenzentrum wird vor allem durch den den Kostenfaktor begrenzt.
Autor: Dr. Stefan Riedl
BILD: MIDJOURNEY / KIGENERIERT
Moderne Datensicherheit bedeutet eine Security-Strategie auf mehreren Ebenen, angefangen bei der Architektur der Storage-Systeme.
BILD:CANVA/KIGENERIERT
WAS SIND AIR-GAP-KONZEPTE?
„Air Gap“ bedeutet Luftlücke und stellt in der ITWelt eine Trennung zwischen Systemen oder Datenumgebungen zu Netzwerken oder externen Systemen dar. Das bedeutet, dass Datenumgebungen, beispielsweise ein Backup-System, von anderen Systemen isoliert stehen. Das kann physisch (räumliche Isolation) oder logisch (digitale Isolation) passieren und soll dazu beitragen, mögliche Angriffswege zu unterbrechen. Bei einem physischen Air Gap ist das geschützte System/Netzwerk physisch von anderen Netzen getrennt. Möglich ist das durch einen eigenen Raum ohne direkte Verbindung zu externen Geräten. Ein physischer Air Gap bietet Schutz vor











Remote-Angriffen, verhindert Datenlecks und schützt auch bei internen Angriffen. Besonders relevant sind diese Konzepte bei hochkritischen Umgebungen. Mittels strengen Zugriffskontrollen und Sicherheitsrichtlinien können auch physisch verbundene Systeme voneinander isoliert werden. Das ist dann der logische Air Gap. Geregelt werden diese Kontrollen und Richtlinien unter anderem durch Firewall-Regeln, Netzwerksegmentierung und Verschlüsselung. So können die Vorteile der Konnektivität, wie etwa vereinfachter Datenaustausch, genutzt und trotzdem eine reduzierte Angriffsfläche geboten werden.
Vogel IT-Medien GmbH
Max-Josef-Metzger-Straße 21, 86157 Augsburg Tel. 0821/2177-0, Fax 0821/2177-150
eMail: it-business@vogel.de www.it-business.de
Geschäftsführer:
Tobias Teske, Matthias Bauer
Co-Publisher: Lilli Kos (-300), (verantwortlich für den Anzeigenteil)
Chefredaktion: Sylvia Lösel (sl) (V.i.S.d.P. für redaktionelle Inhalte)
Chef vom Dienst: Heidi Schuster (hs), Ira Zahorsky (iz)
Redaktion: Redaktion: Mihriban Dincel (md), Natalie Forell (nf), Klaus Länger (kl), Margrit Lingner (ml), Dr. Stefan Riedl (sr), Alexander Siegert (as)
Weitere Mitarbeiter dieser Ausgabe: Dr. Dietmar Müller
Account Management:
Besa Agaj, David Holliday, Stephanie Steen eMail: media@vogel.de
Anzeigendisposition:
Mihaela Mikolic (-204), Denise Falloni (-202)
Grafik & Layout: Carin Boehm, Johannes Rath, Udo Scherlin
Titelbild: © Midjourney - KI-generiert [M] J. Rath EBV: Carin Boehm, Johannes Rath
Anzeigen-Layout:
Carin Boehm, Johannes Rath, Udo Scherlin
Leserservice / Abo: it-business.de/hilfe oder E-Mail an vertrieb@vogel.de mit Betreff „IT-BUSINESS“. Gerne mit Angabe Ihrer Kundennummer vom Adressetikett: *CS-1234567*
Zentrale Anlaufstelle für Fragen zur Produktsicherheit
Frank Schormüller, frank.schormueller@vogel.de, Tel. 0931/418-2184
Unsere Papiere sind PEFC-zertifiziert
Druck:
Vogel Druck- und Medienservice GmbH Leibnizstr. 5, 97204 Höchberg
Haftung: Für den Fall, dass Beiträge oder Informationen unzutreffend oder fehlerhaft sind, haftet der Verlag nur beim Nachweis grober Fahrlässigkeit. Für Beiträge, die namentlich gekennzeichnet sind, ist der jeweilige Autor verantwortlich.
Copyright: Vogel IT-Medien GmbH. Alle Rechte vorbehalten. Nachdruck, digitale Verwendung jeder Art, Vervielfältigung nur mit schriftlicher Genehmigung der Redaktion.
Manuskripte: Für unverlangt eingesandte Manuskripte wird keine Haftung übernommen. Sie werden nur zurückgesandt, wenn Rückporto beiliegt.
Redaktionell erwähnte Unternehmen
Vogel IT-Medien, Augsburg, ist eine 100prozentige Tochtergesellschaft der Vogel Communications Group, Würzburg, einem der führenden deutschen Fachinformationsanbieter mit 100+ Fachzeitschriften, 100+ Webportalen, 100+ Business-Events sowie zahlreichen mobilen Angeboten und internationalen Aktivitäten. Seit 1991 gibt Vogel IT-Medien Fachmedien für Entscheider heraus, die mit der Produktion, der Beschaffung oder dem Einsatz von Informationstechnologie beruflich befasst sind. Dabei bietet er neben Print- und Online-Medien auch ein breites Veranstaltungsportfolio an.
Die wichtigsten Angebote des Verlages sind IT-BUSINESS, eGovernment, Healthcare Digital, BigData-Insider, CloudComputing-Insider, DataCenter-Insider, IP-Insider, Security-Insider und Storage-Insider.
Inserenten