




Expect smart thinking and insights from leaders and academics in data science and AI as they explore how their research can scale into broader industry applications.




Predicting the Next Financial Crisis: The 18-Year Cycle Peak and the Bursting of the Al Investment Bubble by Akhil Patel
“Insuring Non-Determinism”: How Munich RE is Managing Al’s Probabilistic Risks by Peter Bärnreuther
How Al is Transforming Data Analytics and Visualisation in the Enterprise by Chris Parmer & Domenic Ravita
Helping you to expand your knowledge and enhance your career.
Hear the latest podcast over on



CONTRIBUTORS
Ahmed Al Mubarak
Piyanka Jain
Nikhil Srinidhi Saurabh Steixner-Kumar
Biju Krishnan
Akhil Patel
Chris Parmer
James Duez
Francesco Gadaleta
Nicole Janeway Bills
EDITOR
Damien Deighan
DESIGN
Imtiaz Deighan imtiaz@datasciencetalent.co.uk

Data & AI Magazine is published quarterly by Data Science Talent Ltd, Whitebridge Estate, Whitebridge Lane, Stone, Staffordshire, ST15 8LQ, UK. Access a digital copy of the magazine at datasciencetalent.co.uk/media.
DISCLAIMER
The views and content expressed in Data & AI Magazine reflect the opinions of the author(s) and do not necessarily reflect the views of the magazine, Data Science Talent Ltd, or its staff. All published material is done so in good faith.
All rights reserved, product, logo, brands and any other trademarks featured within Data & AI Magazine are the property of their respective trademark holders. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form by means of mechanical, electronic, photocopying, recording or otherwise without prior written permission. Data Science Talent Ltd cannot guarantee and accepts no liability for any loss or damage of any kind caused by this magazine for the accuracy of claims made by the advertisers.

As we begin another new year, the data and AI world finds itself at an interesting inflection point. On one hand, we’re witnessing the emergence of technologies that promise to fundamentally reshape how enterprises operate. On the other hand, we’re confronted with increasingly urgent questions about value realisation, investment sustainability, and the practical realities of implementation at scale.
This tension between promise and pragmatism runs throughout our latest issue, beginning with our cover story from Ahmed Al Mubarak of Howden Re on agentic AI and context engineering. Ahmed explores what may well be the defining enterprise AI trend of 2026: the rise of autonomous AI agents capable of decision-making and task execution. His focus on context engineering for unstructured data addresses a critical capability gap that has long hindered AI adoption in real-world business environments.
The timing of this focus is deliberate. Industry analysts widely predict that 2026 will mark the year when AI agents transition from experimental proof-of-concepts to production deployments at scale across enterprises. Organisations that have spent the past two years testing and learning are now preparing to operationalise these systems. Yet as the article demonstrates, success will hinge not just on the sophistication of the agents themselves, but on our ability to engineer the contextual frameworks that allow them to operate effectively with the messy, unstructured data that dominates most business environments.
This forward-looking optimism, however, must be tempered with cleareyed realism about the challenges ahead. Akhil Patel offers a provocative contribution that serves as an essential counterweight to the prevailing AI enthusiasm. He is predicting that the AI investment bubble will burst within the next 12-18 months, coinciding with the peak of an 18-year economic cycle and potentially triggering the next global financial crisis.
Whether one agrees with Patel’s predictions or not, his analysis demands serious consideration. The capital flowing into AI has reached extraordinary levels, yet tangible returns remain elusive for many organisations. This disconnect between investment and value creation is precisely the kind of imbalance that has historically preceded market corrections.
The practical path forward emerges in our other featured contributions. Piyanka Jain examines how central decisioning systems are poised to replace traditional dashboard-centric business intelligence, a shift that reflects the move from passive reporting to active, AI-driven decision support. Nikhil Srinidhi’s article examines the architectural challenges of building data systems that can balance the flexibility AI demands with the control and governance that enterprises require.
Biju Krishnan in ‘Measuring an Earthquake with a Ruler,’ challenges the conventional wisdom around AI ROI measurement. He argues that traditional metrics are fundamentally inadequate for assessing transformative technology. Meanwhile, Chris Parmer from Plotly demonstrates how AI is already transforming enterprise data analytics and visualisation, providing concrete examples of value creation today rather than tomorrow.
As these technological advances accelerate, the regulatory landscape is also evolving. James Duez provides essential guidance on what the EU’s AI Act means for business, risk, and responsibility, a timely reminder that innovation must be matched with governance.
What emerges from these diverse perspectives is a more nuanced picture than either the AI evangelists or sceptics typically paint. Yes, agentic AI and advanced analytics hold transformative potential. Yes, 2026 may well mark an inflection point in enterprise adoption. But realising this potential will require not just technical sophistication but also architectural wisdom, measurement discipline, regulatory compliance, and perhaps most critically, honest assessment of where we are creating genuine value versus where we are simply riding a wave of capital and hype.
BRIDGING THEORY AND PRACTICE:
REWIRE LIVE 2026 - 5TH MARCH - FRANKFURT
The gap between AI’s promise and its practical implementation is precisely why we’re once again co-promoting Rewire LIVE 2026 on March 5th at the Senckenberg Museum in Frankfurt. This event represents exactly the kind of honest, businessfocused conversation our industry needs as we navigate the transition from experimentation to scaled deployment.
Unlike technical AI conferences, Rewire LIVE is designed specifically for business leaders grappling with real implementation challenges. The program focuses squarely on business models, organisational change, and ROI – not model architecture or coding frameworks.
Last year’s attendees from Deutsche Bank, Roche, Munich Re, Lufthansa, Novartis, DHL, Bayer, BioNTech, and over 30 other organisations came together to tackle the hard questions around architecture and integration, governance frameworks, and workforce augmentation. The interactive mastermind sessions, where participants work through real business challenges collaboratively, provide exactly the kind of peer learning that helps separate genuine opportunity from hype.
As we stand on the cusp of another significant year for enterprise AI adoption, events like Rewire LIVE offer an essential forum for the kind of pragmatic, business-focused dialogue needed right now.
Places are strictly limited, and for more information and registration, visit rewirenow.com/en/resources/event/ai-that-actually-works/
As we move into 2026, the organisations that will thrive are those that can hold both these truths simultaneously: embracing the genuine innovations in AI while maintaining rigorous standards for practical implementation and value delivery. We look forward to continuing these critical conversations with you, both in these pages and in person in Frankfurt.
Damien Deighan Editor
Aslarge language models (LLMs) evolve, one principle has become unavoidable in my day-to-day work: the quality of the input governs the quality of the output especially when the inputs are messy, multi-format, and spread across the enterprise. For years, many of us leaned on OCR, vision models, and increasingly elaborate prompts to coax LLMs into reproducing the structure of source documents. That works until it doesn’t. Real-world content varies wildly by layout and language, and often mixes dense prose with tables, figures, scans, handwriting, and screenshots. The result is brittle pipelines and prompts that need constant tweaking. What has emerged in response is context engineering: a disciplined way to design, structure, and deliver exactly the right information, in the right format, at the right time, so the model can actually do the task at hand (Schmid | 2025 | philschmid.de).
In my own practice as a data scientist, I’ve built solutions that transform raw reports into usable data for AI applications and business intelligence. Some models did a credible job turning financial statements with embedded tables into Markdown; most failed to preserve the table’s original semantics and layout. The deeper challenge was variability. Semi-structured tables in financial reports change year-to-year, company-to-company, and country-to-country. Language localisation adds another layer of ambiguity. Prompt engineering helped up to a point. But as I kept rewriting prompts to fit the next exception, it was clear that the problem wasn’t only the instruction. The problem was the context. Context engineering systematises the ‘what’ to unlock the ‘how’ we design the information environment; data, knowledge, tools, memory, structure, logic, and environment, that surrounds the model so it behaves predictably and productively (Mei et al. | 2025 | arxiv.org).

AHMED AL MUBARAK is a recognised UK global talent in machine learning and artificial intelligence, currently working as a Director of business Intelligence and data science at Howden Re. With a strong background in data strategy, AI integration, and digital transformation, Ahmed focuses on leveraging emerging technologies to drive innovation and efficiency across global business operations. His professional journey combines technical expertise with strategic insight, reflecting a deep commitment to responsible and impactful AI adoption.

I use a practical definition: context engineering is the discipline of shaping what the model sees and can do before it generates a token, ensuring the task is plausibly solvable with minimal improvisation (Schmid | 2025 | philschmid.de). In other words, it is not just better prompting; it is the deliberate combination of content, constraints, and capabilities that make LLMs useful inside complex workflows. Anthropic company makes a similar distinction between prompt engineering (instructions) and
context engineering (curation and delivery of the right evidence and tools) for agentic systems (Anthropic | 2025 | anthropic.com).
To make this concrete, I frame context engineering as layered components that the agent can rely on throughout its run. I often present the following table when onboarding stakeholders, because it clarifies how each piece contributes to reliable outputs.
CATEGORYCOMPONENTDESCRIPTION
Knowledge LayerData
Knowledge
Operational LayerTools
Memory
Structual LayerStructure
Behavioural LayerContext
Canonical, layout-preserving representations of source documents (text blocks, tables with header-cell linkage, figures with captions, entities, citations)
Domain rules, glossaries, policies, and examples e.g. underwriting guidelines, regulatory clauses
External capabilities the agent can call (OCR, table/figure extractors, search, calculators, unit converters, translation)
Session or persistent stores of prior decisions, reviewer feedback, and approved phrasing
Target schemas, section templates, and output contracts (JSON, doc templates)
Logic Guardrails and rules ('cite every number', 'prefer newest reguations', 'no PII')
Integration LayerEnvironment
Connectors, access scopes, and orchestration (indexes, queues, export targets)
PURPOSE / FUNCTION
Supplies grounded evidence the model can recombine without losing structure
Ensures outputs are domain-correct and consistent
Extends beyond pure text generation into action and computation
Provides continuity, reduces repeat errors, and enables learning over time
Gives the agent a shape to write into; improves reproducibility
Encodes operating norms that reduce ambiguity and risk
Makes the context usable within enterprise systems and compliance regimes
This framing aligns with the literature: surveys now describe context engineering as a holistic practice that couples retrieval, processing, and management of contextual inputs to LLMs (Mei et al. | 2025 | arxiv.org), while practitioner sources emphasise the importance of shaping what the model ‘sees’ and the tools it may invoke (Anthropic | 2025 | anthropic.com; LlamaIndex | 2025 | llamaindex.ai).
PROMPT ENGIN EERING FOR SINGLE TURN QUERIES
Unstructured content is everything that refuses to sit neatly in relational tables: emails, PDFs, slide decks, scanned forms, spreadsheets with evolving columns, charts, images, and handwritten notes. The practical obstacles are well-known to anyone who has tried to automate enterprise reporting. Reading order on multi-column pages is easily scrambled. Side-by-side tables lose header–cell relationships. Figures become detached from captions and units. Equations, stamps, and watermarks confuse naïve OCR. Multilingual fragments collide with domain jargon. Without a layout-preserving representation and a disciplined selection of context, LLMs hallucinate links
between cells, misinterpret numbers, or simply ignore crucial evidence.
In my experience, two constraints matter most. First, selecting the right context: the agent must retrieve enough evidence to be correct but not so much that the window is clogged with irrelevant material. Second, fitting the token window: the context must be compact, structured, and deduplicated, so the model sees just what is needed, exactly once. That means we cannot treat the document as a blob of text. We must convert it into a structured substrate so the agent can query tables as cells with headers, figures with captions and alt text, sections with IDs, entities with types then index those pieces for targeted retrieval (LlamaIndex | 2025 | llamaindex.ai).
tool name
tool input/outp ut parameters tool
query: Annotated[str, "A language query or question."]
) → str :
"""Useful for retrieving knowledge from a database containing information about XYZ. Each query should be a pointed and specific natural language question or query."""
<code>
return retrieved_knowledge
ENTERPRISE DATA TODAY: WHERE THE MESS LIVES Enterprise data is scattered by design. Some live in email threads and calendar invites. Some sit in OneDrive or SharePoint, some in Slack or Confluence, some in S3 buckets with cryptic prefixes, some in line-of-business portals. Even ‘simple’ files arrive in a dozen types of PDFs of varying provenance, images and scans, spreadsheets with hidden columns, or mixed-language reports from regional teams. If you manage to pull the right files, the next problem is semantic: extracting the right slices from unstructured or semi-structured formats while preserving their meaning. I have found that the fastest path to reliability is to normalise all sources into a layout-preserving, canonical
JSON that becomes the single source of truth for generation and export. Tools like modern document parsers and layout engines produce consistent elements: pages, blocks, tables, figures, entities, citations, without flattening away structure. On top of that canonical layer, we build a hybrid index (vector + lexical + metadata) and label each chunk with jurisdiction, line of business, effective dates, language, and freshness. The agent retrieves evidence bundles per section top-k passages, required tables, and key figures bounded to the token window, then writes into a target schema. Compared to ‘send the whole PDF to the model,’ this approach is auditable, scalable, and much cheaper.
To build integrations with hundreds of foundational libraries and forge relationships with their maintainers, contributing back to upstream projects through careful diplomacy.
02
Canonical JSON Format
To create a representation language rich enough for complex spreadsheets, simple enough for basic text documents.
03
Cutting Edge Quality
To handle unhandleable documents – scanned PDFs, embedded charts, complex layouts requiring visual understanding via Vision Language Models, Object Detection Models, and Computer Vision techniques.
And Generative LLM model to handle the text in the document.
One subtle but important shift in 2025 has been the rise of AI configuration files ; machine-readable context and instructions checked into the repository, such as AGENTS.md, CLAUDE.md, or copilot-instructions.md. Instead of scattering the ‘first context’ across prompts and tribal knowledge, teams standardise how agents should behave in a specific codebase or project. The file encodes the project structure, build/test commands, code style, contribution rules, and references. Agent tools read the file automatically and inject its content into their working context (GitHub | 2025 | github.blog; agents.md | 2025 | agents.md).
A recent work-in-progress study examined 466 opensource repositories and found wide variation in both what is documented and how it is written; descriptive, prescriptive, prohibitive, explanatory, conditional, with no single canonical structure yet (Mohsenimofidi et al | 2025 | arxiv. org). That variability matches my experience: AGENTS.md is most powerful when it encodes not just instructions but also context logic , the guardrails that determine how an agent chooses and uses evidence. If you want reproducible behaviour, version your context alongside your code.
When I propose context engineering to stakeholders, I describe it as a lightweight ‘operating system’ for agents. Its job is to orchestrate how data, knowledge, tools, memory, structure, logic, and environment come together at run time.
The ingestion pathway accepts sources from email, OneDrive/SharePoint, Slack/Confluence, S3, and direct uploads. Parsing combines OCR and layout detection to preserve headings, reading order, footnotes, sideby-side tables, figures with captions, and equations. Canonicalisation converts everything to JSON with strict linking between headers and cells, captions and figures, and cross-references. Indexing builds hybrid search over all elements with rich metadata. Selection composes compact evidence bundles per section that fit the window. Planning decomposes the task into sub-goals mapped to tools: compute KPIs, normalise units, summarise exposures, reason about compliance. Drafting writes section-bysection into target schemas with per-paragraph citations. Validation runs numeric, structural, and compliance checks. Export renders multiple formats PDF, PPT, HTML from the same canonical draft. Feedback writes reviewer edits into memory, so the next run starts smarter.
Standardised Elements
Title Section header
Narrative Text Body content
Table Structured data
Image Visual content
This pipeline turns a static model into a programmable, tool-aware writer. It also reduces risk. Grounded evidence and per-paragraph citations curb hallucination. Target schemas unlock automated QA. And the context logic protects against failure modes such as stale regulations or missing loss runs (Anthropic | 2025 | anthropic.com; DAIR. AI | 2025 | promptingguide.ai).
HANDS-ON DEMO: WRITING
TECHNICAL REPORT WITH AN AGENT
I’ll anchor the above with a real-world scenario I build frequently: producing a quarterly insurance technical report from scattered content. The company asks the AI agent to deliver a print-ready PDF, a presentation-grade PPT, and an HTML page with live citations. The data arrives in every shape imaginable: scanned policy schedules; emails with embedded tables; spreadsheets whose columns change annually; photos of damage; prior reports in multiple languages. Prompt engineering alone will not tame this variety.
The run begins with intake that preserves layout. Content from email, OneDrive, Slack, Confluence, and S3 is parsed so reading order, headings, footnotes, and sideby-side tables survive extraction. Each artefact becomes canonical JSON, not a flattened blob. Tables retain header–cell linkage and include text grids, optional HTML, and a faithful image snapshot. Figures carry captions and alt text. This universal representation makes mixed-language pages and embedded charts intelligible to the agent without losing structure (LlamaIndex | 2025 | llamaindex.ai).
Before querying anything, the agent receives a short AGENTS.md-style brief. It states the audience and tone, the mandatory sections (Executive Summary, Exposure Profile, Loss History, Coverage Analysis, Recommendations, Appendices), the approved phrasing for sensitive topics, and the guardrails: cite every number, prefer the newest regulation, redact PII, use UK spelling. It also enumerates registered tools with their scopes: table reconstructor, risk ratio calculator, currency converter, date harmoniser, translation helper, and templating engines for PDF/PPT/
HTML. This ‘first context’ constrains behaviour and prevents the tool from wandering.
For each section, the agent composes a bounded evidence bundle. For Loss History, it retrieves the five-year claim table with date, cause, paid, and case reserve; a figure showing quarterly frequency; and a passage that explains the spike in Q4. It computes frequency and severity, calculates loss ratios, normalises currencies and dates, and annotates each paragraph with its source IDs. Tables are rebuilt from structured cells, not pasted as screenshots. Captions remain attached to their charts. If evidence is missing, the agent flags the gap and suggests next steps instead of inventing data. This retrieval-aware writing loop produces text that is faithful, traceable, and ready for review (Anthropic | 2025 | anthropic.com; DAIR.AI | 2025 | promptingguide.ai).
Quality assurance runs in parallel. Validators check totals within tolerance, enforce header–cell alignment, and ensure every required section is present. Unit and date normalisers catch silent inconsistencies. A compliance pass redacts PII and scans for prohibited phrasing. Any discrepancy becomes a visible note for the agent to resolve by fetching better evidence or marking a decision for human review. Editorial changes flow back into memory, so the next report begins with the newest boilerplate, the latest regulatory references, and the team’s approved tone. Publishing is simply rendering the same canonical draft into multiple formats. The PDF is print-ready for underwriters and auditors, the PPT distils each section into a slide with highlights and exhibits, and the HTML carries deep links into the evidence log so reviewers can jump from a claim statistic to the source row. Because everything stems from the same structured draft, there is no drift between formats.
Several small techniques pay outsized dividends. I keep evidence bundles under a hard token budget and prioritise diversity of sources over repetition. I strip duplicate passages aggressively at retrieval time to avoid polluting the window. I store units and currencies explicitly alongside values in the canonical JSON and normalise them before generation. I treat tables as first-class objects: headers, data types, totals, footnotes, and units are embedded and validated. I make captions mandatory for figures and link them to the nearest paragraph to prevent orphaned visuals. I push style and compliance into context logic: casing, spelling (en-GB vs en-US), phrasing constraints for risk disclosures, and redaction rules. Importantly, I version the context schemas, briefs, rules alongside the code, because context is now part of the software artefact (GitHub | 2025 | github.blog; Mohsenimofidi et al. | 2025 | arxiv.org).
When a model fabricates a number, the instinct is to tighten the prompt. In my experience, fabrication is more often a context failure. The model did not see the right evidence, or it saw too much contradictory evidence, or it lacked a rule that forbade speculation. Retrieval noise, stale documents, and silent unit drift are common culprits. The remedy is upstream: curate the index, privilege freshness in the ranking, annotate units and dates, enforce ‘no evidence → no claim,’ and keep explicit gaps visible in the output. Another failure mode is format fidelity: tables that look right but misalign headers and cells. Treating tables as objects with validations, not pictures, prevents subtle integrity loss. A third is scale drift as tasks grow longer and agents call more tools. Here the fix is to encode planning: require the agent to produce a plan that maps sub-tasks to tools, then execute with explicit inputs/ outputs logged in memory. These patterns are echoed across practitioner guides and research agendas on agentic systems (Anthropic | 2025 | anthropic.com; Villamizar et al. | 2025 | arxiv.org; Baltes et al. | 2025 | arxiv.org).
Context engineering benefits from clear metrics. I measure groundedness (share of sentences with traceable citations), section completeness (mandatory fields present), numeric integrity (totals within tolerance, unit consistency), layout fidelity (table header–cell alignment, caption attachment), and editorial effort (redlines per thousand words). On the operational side, I track token budget adherence, tool error rates, and time-to-publish. These are not abstract KPIs; they pinpoint which part of the context pipeline needs attention: index quality, selection heuristics, rules, or validators. Methodological guidance for LLM-in-SE studies underscores the need for rigorous, reproducible evaluation when agents interact with real artefacts (Baltes et al. | 2025 | arxiv.org).
Agentic coding tools have normalised the idea that we should document for machines, not just humans. The adoption of AGENTS.md-style files in open-source shows teams actively shaping their agents’ context–project structure, build/test routines, conventions, and guardrails then versioning that context in Git. The emerging research suggests styles and structures vary widely, but the trajectory is clear: context is becoming a first-class software artefact (Mohsenimofidi et al. | 2025 | arxiv. org). In my view, the same pattern will define enterprise reporting, customer service, finance ops, and risk management. As tasks lengthen and tool calls multiply, the backbone of reliable automation will be a context OS: layout-preserving data, explicit knowledge, callable tools, durable memory, structured outputs, enforceable logic, and a well-integrated environment.
I started this journey believing that better prompts would fix unreliable outputs. After building dozens of pipelines on top of documents that resist structure, I now believe something different. Prompting is necessary; context engineering is decisive. When we treat context as an engineered system – complete with schemas, indexes, rules, and validators – LLMs become competent collaborators rather than gifted improvisers. In the insurance report demo, context engineering turned chaotic inputs into a grounded, auditable narrative that ships as PDF, PPT,
and HTML on schedule. The payoff is consistent across domains: fewer redlines, faster cycles, clearer audit trails, and models that learn from feedback. The discipline is still evolving, and conventions for documenting machinereadable context are far from settled. But the direction is unmistakable. The next generation of AI systems will be built on the quiet infrastructure we place around the model, not only on the cleverness we push into the prompt (Schmid | 2025 | philschmid.de; Anthropic | 2025 | anthropic.com; Mei et al. | 2025 | arxiv.org).
Anthropic. “ Effective Context Engineering for AI Agents ” 2025 anthropic.com engineering/effective-context-engineering-for-ai-agents
Baltes, S. et al. “ Guidelines for Empirical Studies in Software Engineeri ng involving Large Language Models ” 2025. arxiv.org/abs/2508.15503
DAIR.AI. “ Elements of a Prompt | Prompt Engineering Guide ” 2025 promptingguide.ai/introduction/elements
GitHub. “ Copilot Coding Agent Now Supports AGENTS.md Custom Instructions (Changelog )” 2025 github.blog/changelog/2025-08-28-copilot-coding-agent-now-supports-agents-mdcustom-instructions/
Horthy, D. “ Getting AI to Work in Complex Codebases ” 2025 github.com/humanlayer/advanced-context-engineering-for-coding-agents
LlamaIndex. “ Context Engineering: What It Is and Techniques to Consider ” 2025 llamaindex.ai/blog/context-engineering-what-it-is-and-techniques-to-consider
Mei, L. et al. “ A Survey of Context Engineering for Large Language Models ” 2025 arxiv.org/abs/2507.13334.
Mohsenimofidi, S., Galster, M., Treude, C., and Baltes, S. “ Context Engineering for AI Agents in Open-Source Software ” 2025 arxiv.org/abs/2510.21413
Schmid, P. “The New Skill in AI is Not Prompting, It’s Context Engineering” 2025 philschmid.de/context-engineering
Villamizar, H. et al. “ Prompts as Software Engineering Artifacts: A Research Agenda and Preliminary Findings ” 2025 arxiv.org/abs/2509.17548


PIYANKA JAIN is the CEO of Aryng and AskEnola. With decades of experience with global enterprises, she specialises in analytics strategy, decision science, and the practical adoption of AI. She is the bestselling author of Behind Every Good Decision and a leading voice on the responsible application of AI within analytics and adjacent fields.
Fordecades, dashboards served as the standard interface between people and data. They gave leaders visibility they never had before and helped formalise the way organisations reviewed performance. Their rise marked a shift toward data-informed cultures. Yet, in 2025 and beyond, their limitations are becoming undeniable. Insights are fragmented across systems, data lives in silos, and human interpretation often clouds truth with bias. The result is decision latency and inconsistency when speed and precision are what define market leaders.
Fortunately, a new architecture is emerging that closes these gaps. Enter the Central Decisioning System (CDS): a unified, intelligence-driven ecosystem that brings together people, data, and AI agents into one continuous decision loop.
Dashboards were once revolutionary, but today they are static, fragmented, and slow. They show what happened and where trends point, but they do not help users interpret patterns, weigh trade-offs, or decide what to do next. Leaders often bounce between multiple dashboards for finance, marketing, sales, and product, each one telling part of the story. KPI definitions differ across tools, the timing of refresh cycles is inconsistent, and visualisations depend heavily on manual configuration. The result is a set of partial truths that still require analysts to stitch together insights.
Organisations that rely exclusively on dashboards find themselves conducting long review meetings, reconciling numbers, and revalidating findings instead of acting. That level of friction becomes a structural limitation. This is why the future is not better, or fancier, dashboard solutions, but an entirely new decisioning architecture.
A CDS is a unified, always-on intelligence layer that connects all data sources, human inputs, and AI agents to make and distribute consistent, data-backed decisions across the organisation. With CDS, instead of piecing together insights manually, teams interact with a system that already understands relationships between entities, past decisions, business rules, and expected outcomes.
Core capabilities of a CDS would include:
● Seamle ss integration across systems such as emails, documents, Slack, and CRMs
● Semantic understanding of business concepts and relationships, creating a family tree of insights
● Automated triggers that connect data, people, and actions in real time
● A s elf-refreshing repository of organisational intelligence accessible to all. It would function like Yahoo Finance for your entire organisation: live, contextual, and endlessly queryable.
A new architecture is emerging [...]. Enter the Central Decisioning System (CDS): a unified, intelligencedriven ecosystem that brings together people, data, and AI agents into one continuous decison loop.
Enterprises today juggle too many systems with too little coherence, with dashboards often reflecting fragmented truth, making the idea of a single source of truth difficult to achieve.
Deep-dive analyses by specialists take weeks instead of minutes, and insight generation depends on a few analysts, creating bottlenecks that slow everyone else. When a question requires pulling data from multiple systems and validating definitions across teams, the time needed to arrive at a decision grows significantly. Analysts become gatekeepers, not by choice but by necessity, and those bottlenecks slow down the entire organisation. The result is delayed and inconsistent decision-making that erodes agility and trust.
A CDS removes all this friction by aligning data, logic, and analysis in one place. Instead of static reports, decision-makers receive validated, context-rich intelligence in minutes. This reduces variability in how decisions are made and increases confidence in the insights
teams rely on each day. In any market, this consistency becomes a structural advantage.
A CDS raises the baseline of decision quality across the company. Every employee, regardless of tenure, can understand business dynamics through patterns learned by the system. Recommendations become more consistent because they are generated from unified logic rather than individual interpretation. AIdriven actions reduce manual work, especially in areas where rules are already known.
The shift in team roles is significant.
Analysts transition from creating reports to designing analytical models and validating decision logic. Data engineers and data scientists focus on architecture and modelling that support scalable automation rather than one-off solutions. Their expertise shapes the intelligence layer that informs daily decisions. On the other hand, with CDS in place, a sales representative starts the day with a call list already ranked by
conversion likelihood. HR receives early indications of rising attrition risk before it becomes visible in traditional metrics. Finance is notified the moment an unexpected pattern appears in transaction data.
Each of these instances, and the decisions they involve, would previously have required manual investigation. A CDS, however, makes all of them not just data-driven, but also decision-driven, and ultimately, business-outcome-driven.
The path to a Central Decisioning System begins with the rise of AI analysts and agentic AI. These systems shift organisations away from static dashboards toward a model where users can engage directly with data through natural language. Instead of searching across multiple tools, teams can ask questions conversationally and receive precise, context-aware answers grounded in validated logic.
AI analysts bring a semantic understanding of business concepts that traditional analytics platforms

cannot provide. They recognise entities such as customers, products, regions, and channels, and they understand how these elements relate to each other across different datasets. This creates a shared vocabulary between humans and systems, which is essential for a CDS because it ensures that every query, recommendation, and action is grounded in consistent meaning. Agentic AI extends this capability by interpreting intent, identifying the underlying decision a user is trying to make, and assembling the required analysis automatically. It performs multi-step reasoning, retrieves information across systems, evaluates conditions, and suggests next actions. This is the early form of the decision automation that a CDS requires.
As AI analysts and agentic systems integrate more deeply into an organisation’s operational environment, they begin to connect analytics with real-time triggers, workflows, and data streams. Over time, these capabilities evolve into the unified intelligence layer that defines a CDS. The shift is gradual but significant: from isolated reports to an interactive intelligence environment that continuously interprets what the business needs and delivers actions rather than static outputs.
AI analysts and agentic AI are not the final stage, but they form the essential bridge that enables organisations to move toward a fully centralised, always-on decisioning system.
The potential risks of a CDS are also real, of course. It could become an opaque black box, and AI-generated insights could carry embedded

biases. To counter this, feedback loops should be built so human judgment continues to refine AI logic. Automation must be balanced with accountability to preserve trust in the system’s recommendations. Any system that concentrates decision logic must be designed with transparency.
A CDS should never operate as an opaque environment. To prevent this, explainability must remain a design principle. Clear audit trails, traceable reasoning, and documented logic paths help organisations maintain accountability. Feedback mechanisms allow teams to correct, challenge, or refine the system’s conclusions. These safeguards will ensure that the system strengthens decision quality without removing human oversight.
The CDS will reshape how data teams operate, reducing manual analytics work and emphasising
architecture, modelling, and oversight. Decision-making will shift from episodic reviews to a continuous, adaptive flow of intelligence. The organisations that thrive will be those that think and act as one system, with decisioning intelligence woven into every layer of their operations.
The future of enterprise intelligence is not another visualisation tool but a thinking fabric that connects insight to action continuously and intelligently. Building toward a Central Decisioning System starts now, not later. For leaders, the imperative is clear: audit your decision architecture today. The question is no longer if dashboards will fade but whether your organisation is ready for what comes after.
The organisations that thrive will be those that think and act as one system, with decisioning intelligence woven into every layer of their operations.

NIKHIL SRINIDHI
NIKHIL SRINIDHI helps large organisations tackle complex business challenges by building high-performing teams focused on data, AI and technology. Before joining Rewire as a partner in 2024, Nikhil spent over six years at McKinsey and QuantumBlack, where he led holistic data and AI initiatives, particularly in the life sciences and healthcare sector.

How would you define data architecture and why should business leaders care?
In a small company, your daily conversations serve as the data architecture. The problem arises at scale. Once you have multiple teams, you need something that contains those agreements and design patterns, and you can't have 100 meetings a week explaining this to a whole organisation.
It's critically important because without it, everyone is building with different blueprints. Imagine constructing a building with each person using a different schematic. Connecting it to the origin of the word ‘architecture,’ it's really a way of ensuring everyone is working toward the same end goal. For data, it's about how you work with technology, different types of data, how you process it, and how you deal with structural and quality issues in a way that moves the needle forward.
I'd argue that architecture is key to scaling data and AI correctly. That's why organisations have been investing heavily in it. However, many haven't got everything they'd like out of it, so there's still an ROI question worth discussing.
Data architecture is really a way of ensuring everyone is working toward the same end goal.
What made data architecture a C-suite topic, and what role does AI play?
Twenty years ago, companies like IBM provided the full value chain from databases to ETL to visualisation. Over time, many companies began specialising in niche parts of the data value chain. Enterprises suddenly faced new questions as the importance of data grew: Which combination of technologies should I use? Where should I do what? Often you had data in one place and certain capabilities in another. Do you move the data? Do you move the capability?
Now with generative AI requiring vast amounts of unstructured information, you're thinking about knowledge architecture and information architecture. How do you ensure the right information feeds these models? The problem is growing fast.
Could you clarify the key layers of a modern data stack? I'd break it into two aspects. First is the static aspect, the data technology architecture: what tools, components, and vendors you use from ingestion through to consumption.
The second aspect is the dynamic part: data flows. How data moves from creation to consumption, with clarity about where processes should be standardised and where they can vary.
What's important is providing guidelines on how these patterns and technologies can be applied at scale. Successful data architecture becomes easily applied by the teams actually building things.
What principles should good modern data architecture have?
on these decisions so organisations walk into them consciously rather than falling into them. Whoever's building the architecture needs to be well-versed in the business strategy. When architecture becomes so generic you can switch the company name and it works for any industry, it probably won't work.
What are the biggest misconceptions about modern data architecture?
It depends on the industry, of course, but the biggest misconception I've encountered is that extreme abstraction will always make your architecture better. There's a tendency for architecture to become overly theoretical, but we need to ensure we make pragmatic trade-offs.
How do you make it pragmatic? There might be a specific part of the architecture, like your storage solution, where it's okay not to have all the flexibility through abstractions or modularity. You can double down on specific technologies and storage patterns. It's okay to commit to something. For example, if you want to store all your data as Iceberg tables or Parquet files, and that's a decision you've made for now, you can go with it. You don't have to build it in a way where you're always noncommittal about your decisions.
What's important is recognising where commitment benefits you and where it could become a cost.
The business or data strategy describes what to do with data. Why we need it, what businessobjective it helps achieve, what date represents ourcompetitiveadvantage. Architecture focuses on how.
Ironically, while architecture suggests permanence, data architecture needs modularity and flexibility. If there's a disruption in one component or an entirely new processing method emerges, you should be able to switch that component without breaking the entire system.
The human angle is often ignored. How do you encapsulate architecture as code and reusable modules that development teams can easily pull from a repository? The more practical and tangible you make it, the better.
Another quality is observability. You should be able to tell which parts of your data architecture are incurring the highest costs, which are growing fastest, and where leverage is reducing when it should be increasing.
How should data architecture align with business strategy, and where do you see disconnects?
The business or data strategy describes what to do with data. Why we need it, what business objective it helps achieve, what data represents our competitive advantage.
Architecture focuses on how. So, building things effectively and efficiently with optimal resources. It provides perspective on trade-offs. You can't have lower cost, higher quality, and speed simultaneously. Architecture should provide crystal clear clarity
For example, in life sciences R&D, you'd want to give consumers freedom to explore datasets in different ways. Diversity is fine there. But there's no point building the most perfect storage layer that tries to remain neutral. The misconception that architecture must be perfectly modular at every angle leads to unnecessary work.
How has GenAI influenced data architecture decisions in traditional business sectors?
GenAI has achieved visibility from the board to developers. The realisation is that without leveraging proprietary information, the benefit GenAI provides will be the same for any company.
The biggest challenge is providing the right endpoints for data to be accessed and injected into LLM prompts and workflows. How do you build the right context? How do you use existing data models with metadata to help GenAI understand your business better?
The broader question is, how do you handle unstructured data? Information in documents, PDFs, PowerPoint slides. How do you make this part of the knowledge architecture going forward? There's no clear approach yet.
How should organisations approach centralisation versus decentralisation?
I'll be controversial. While data mesh was an elegant
concept, the term created more confusion than good. It became about decentralisation versus centralisation, but the answer always depends.
For high-value data like customer touchpoints, you'd want standardisation. Centralisation may be fine. But ‘centralised’ triggers reactions because it means ‘bottleneck.’
Much advantage comes when data practitioners are deep in business context. If someone is working in the R&D space or clinical space, the closer they are to domain knowledge, the better, even if they have a background as a data engineer or data scientist. In these situations when something is centralised, requirements get thrown back and forth.
Focus on how you want data, knowledge, and expertise to flow. There's benefit to having expertise at the edge, but also to controlling variability. Both approaches should be examined without emotion.
What's your approach to separating signal from noise in the current data and AI landscape?
First, understand what types of data you have. A data map that's 70-80% correct is enough to start. ‘All models are wrong, but some are useful.’
Second, understand technologies and innovations in flux within each capability. Know the trends so you can identify leapfrog opportunities rather than doing a PoC for every capability.
Third, determine what is good enough. ‘Perfect is the enemy of good.’ Half the time, organisations pick solutions with a silver bullet mentality. Be honest, this works in 80% of cases, but here's the 20% that won't. Being aware of that de-hypes the signal.
To recap: know capabilities' connection to business value, understand market trends, and identify the extent capabilities need to be implemented, recognising you have limited resources.
What mindset and capability shifts do organisations need around data initiatives?
Working backwards, successful organisations have product teams that rapidly reuse design patterns and components to focus on problems requiring their expertise. Moving away from what we call pre-work to actual work.
Data scientists spend 70-80% of their time on data cleaning and prep. We want everyone to easily pull integration pattern codes, templates, and snippets without reinventing the wheel.
Individuals need to build with reusability in mind. If it takes 10 hours to build a module, it may take three more hours to build it in a more generalised fashion. Knowing when to invest that time is critical.
People building architecture need a customerfacing mindset. Think of other product teams as internal customers. This drives adoption and creates a flywheel effect.
How should organisations structure the data architecture capability?
The most successful architects have grown from
engineering implementation roles. They've built things, been involved in products, then broadened their focus from one product to multiple products. That's the most successful way of scaling the architectural mindset.
Even if architecture is a separate chapter, intentionally bring them together in product teams. Make the product team, where developers, architects, and business owners collaborate, the first level of identity an employee has.
If you ask an employee ‘what do you do?’ They should say ‘I'm part of product team X,’ not ‘I’m in the architecture chapter.’ This mindset shift requires investment. It's a people issue. It’s about ensuring there is trust between groups and recognising what architecture is at that product team level.
How should we measure the impact of data architecture? What's a smarter way to think about the value?
There's no clear-cut answer because data architecture is fundamentally enabling and it's difficult to directly attribute value. It's like a highway. Can you figure out what part of GDP comes from that highway? You can use proxies, but it's abstract.
The most important thing is almost forgetting ROI. Nobody questions whether a highway is important. Nobody questions the ROI of their IT laptop. We need to dream about a future where data architecture is similarly valued.
Ensure whatever you build connects to an initiative with a budget and specific business objective. You're not just building something hoping it will be used. Recognise that some capabilities individual product teams will never be incentivised to build and you need centralised teams with allocated budget for that.
Benchmark against alternatives: what would it cost teams to build this on their own using AWS or Azure accounts? Is there an economies of scale argument?
Measure proxy KPIs where possible because, ultimately, it's about the feeling of value. But also tell the story of what would happen without a central provider. What would it cost individual teams to do that on their own? That helps justify and track ROI.
Can you give some examples from regulated industries that illustrate the principles you have shared?
In life sciences R&D, data architecture is about bringing together different data types, including unstructured information and making it usable quickly. There's a big push in interoperability using standards like FHIR and HL7. If you're designing something internally, why not use these from the start rather than building adapters later?
Beyond the commercial space, there's also increasing effectiveness in filing for regulatory approval and generating evidence. There's tremendous value in ensuring you have the right audit trails for how data moves in the enterprise, especially as companies enter the softwareas-a-medical-device space. Knowing how information and data travels through various layers of processing is made possible through data architecture.
One of the biggest competitive advantages is becoming better at R&D. How do you take ideas to market? How do you balance a very academia-driven approach with a datadriven and technology-driven approach? This is where data architecture can be quite impactful.
Think about developing different types of solutions that require medical data to support patient-facing systems or clinical decision support systems. In all of these, it's highly critical to get it right in terms of how data flows, but also to ensure the data that's seen and used has a level of authenticity and trust.
The kinds of data we're working with vary from realworld data you can purchase – from healthcare providers, hospitals, especially EMRs and EHRs – to very structured types of information. How do you take that information, combine it, build the right models around it, and provide it in a way that different teams can use to drive innovation in drastically different spaces? Data architecture there is less about giving you an offensive advantage and more about reducing the resistance and friction to letting the entire research and development process flow through.
For example, how do you build the right integration patterns to interface with external data APIs? The datasets you're buying are probably made accessible via APIs you need to call, and you're often bound by contracts that require you to report how often these datasets are used. If you're using a specific dataset 30 times, it corresponds to a certain cost. However, if you're not able to report on that, the entire commercial model you can negotiate with data providers will change. They'll naturally have to charge more because they don't have a sense of how it's being used and will be more conservative in their estimates.
Being able to acquire data in different forms with the right types of APIs and record usage is a huge step forward.
Good data architecture is needed because across that architecture, you apply data observability principles. How is my data coming in? When is it coming in? How fresh is the information? How is it stored? How big is it? Who is consuming this information? What kind of projects do they belong to? How are they using it? Are they integrating these datasets directly into our products or tools?
Successful organisations go for leaner solutions with four to five integration patterns. They say: ‘This is how we get external data. If there's a way not covered by these, talk to the team.’ This level of control is required, because without it, tracing data and maintaining lineage becomes very difficult.
A lot of the value comes from acquisition in the pipeline. The second source of value comes from how data is consumed. What kind of tools can you provide an organisation to actually look at patient data? For example, with multimodal information, genomic information, medical history, diagnostic tests. How do you bring them all together to provide that realistic view? This is also an area where data architecture is very important because this goes much more into the actual data itself.
Also, what are the links between the information? How do you ensure you can link different points of data to one object? What kind of tools can you provide to the end user to explore this information? The classic example is combining a dataset and providing a table with filters, letting users filter on the master dataset. But recognising the kinds of questions your users would have also allows you to support those journeys. In these situations, successful companies have always taken a more tailored approach. Identifying personas and then building up that link between all these different types of data, especially in the R&D space.

Can you elaborate on the stakeholder challenges in life sciences?
Life sciences need diverse technologies and integration patterns, but technology and IT are still seen as a cost bucket. The more technologies you have, the more quickly data gets siloed.
Where to draw the line on variability in data architecture – especially in storage and data acquisition – is critical. This quickly balloons to a large IT bill. When you can't directly link value to it, organisations cut technology costs without realising the impact. It can dramatically affect capabilities in commercial excellence or drug discovery pipelines. We need to bring these two worlds closer together.
How does the diversity of life sciences data – such as omics, clinical trials and experimental data –affect architecture?
When you have such diverse multimodal data and dramatically different sizes, it's important to ensure you have good abstracted data APIs even for consumption within the company. If I'm consuming imaging information or clinical trial information, how do I also have the appropriate metadata around it that describes exactly what this data contains, what are its limitations, under what context was it collected, and under what context can it be used, depending on the agreement?
This kind of metadata is key if you want to automate data pipelines or bring about computational governance. This is a key capability when you're dealing with very sensitive healthcare information, and data is often collected with a very predefined purpose. For example, to research a specific disease or condition. Initially it might not be clear whether you can use that information to look at something else in the future.
These kinds of agreements that have been made in the past or haven't been made yet need to get to the granularity where the legal contracts you sign with institutions, individuals, and organisations about data use are somewhat translatable and depicted as code in a way that can automatically influence downstream pipelines where you actually have to implement and enforce that governance.
For example, if a dataset is only allowed to be used for a specific kind of R&D, it needs to show up at the data architecture level that only someone from a specific part of the organisation (because they're working on this project) can access this information during this period. The day the project ends, that access is revoked, and all this is done automatically. This isn't the case yet. It's still quite hybrid. This computational governance, because of the multimodality of the information combined with sensitivity, is the biggest problem many of these companies are trying to solve today.
Could GenAI help researchers navigate complex data catalogues with regulatory and compliance requirements?
I think GenAI has immense capability here because many of the issues are around how you process the right types of information in a very complex setting, recognising there are legal guidelines, ethical guidelines, and contractual guidelines you want to ensure work properly. It also interfaces from the legal space to the system space, where the information actually becomes bits and bytes.
Through a set of questions and a conversation, you can at least determine what kind of use this person is thinking about, what kind of modalities are involved, where those datasets actually sit, and which ones are bound by certain rules. This is where the ability to deploy agents can make sense because when you want to really provide this kind of guidance, it means you need clarity that's fed into the model as context that it can then base its analysis upon. Or if it's a RAG-like retrieval approach, you need to know exactly where to retrieve the guidance from.
The logic to evaluate is sometimes something that may need to be deterministically encoded somewhere for it to be used. That requires individuals to identify or create what I call labelled data for this kind of application. If this was the scenario, this was the data, this was the user, this is what they wanted and here's the kind of guidance the AI should provide. With that level of labelled information, you have a bit more certainty.
Organisations have vast amounts of unstructured data that could be vectorised and embedded to navigate it better, to increase utilisation. How do you see this evolving in the future?
Vector databases, chunking, indexing, and creating embeddings in multidimensional spaces is the first step. But architecture is still limited by how you ensure data sources can be accessed via APIs and programmatic calls and protocols. You still need that so all the different islands of information have a consistent, standardised way of interfacing with them.
This is the upgrade data architectures are currently going through, driven by use cases.
What's your one piece of advice for leaders responsible for data architecture?
Simplify and make data architecture accessible. Use simple English. Don't use jargon. Make it a topic that even business users want to understand. Just like Microsoft made everyone comfortable with typing or Excel, architecture needs to adopt that principle. It doesn't mean everyone needs to spend cognitive capacity on it, but it's helpful if everyone understands its place.
Just like Microsoft made everyone comfortable with typing or Excel, architecture needs to adopt that principle.
DR SAURABH STEIXNER-KUMAR is a data and AI leader with a rare blend of scientific depth and industry impact. At one of the largest financial institutions in the world, he drives global analytics and machine-learning initiatives end-to-end. From setup to model development to deployment, he excels at delivering scalable, business-critical solutions. Saurabh previously worked in luxury retail, leading data science projects spanning personalised recommendations and marketing attribution, integrating state-of-the-art algorithms with big data platforms. With a PhD from the Max Planck Institute and a research portfolio published in Science and Nature Scientific Reports , Saurabh brings deep expertise in decision science, leadership, and stakeholder management. His career across major players in finance, retail, aviation, and neuroscience empowers him to bridge cutting-edge research with real-world applications, making complex AI not just understandable but actionable for modern enterprises.
INTRODUCTION: THE INVISIBLE THREAT
Money laundering is a crime built on invisibility. Unlike a bank robbery or credit card scam, there is no single dramatic act, no obvious victim, no immediate loss. It is so subtle that without checks in place, it would remain hidden forever. Criminals don’t need to create new money but only make dirty money look clean. In the contemporary world, it has become even easier and even more dangerous.
Funds from drug trafficking, corruption, cybercrime, and human trafficking are fed into the legitimate financial systems before being layered through transfers, investments, and complex transactions. These transactions are designed to obscure their origins before finally reemerging as seemingly legitimate money. It is particularly difficult to detect because of the deliberate blending

of illegal funds with legitimate activity. A fraudulent transaction may be hidden among millions of routine ones, structured to appear perfectly ordinary.
Hiding in the Maze
Complexity is what drives the money laundering schemes. The systems designed for our modern society, like fast cross-border payments and diverse financial products, are the very mechanisms that criminals exploit. Shell companies offering various financial solutions over multiple jurisdictions make it harder to uncover the trail of money.
Cryptocurrencies have recently added another dimension to the difficulty. While digital assets promise transparency, they also enable newer money laundering schemes where the regulators and compliance teams often trail behind the criminals.
DR SAURABH STEIXNER-KUMAR
For many years, financial institutions have primarily relied on the rule-based transaction monitoring systems to spot suspicious behaviour. It is a relatively simple logic of using thresholds, which, when crossed, trigger an alert that then must be investigated by the investigation unit. This usually overwhelms the teams because of a very high number of false positives.
A money launderer may study such rules and intentionally exploit them to only transact below set thresholds. This is called smurfing, where the transactions look normal, but they are part of a bigger money laundering scheme. One must look beyond rigid systems and explore newer avenues.
Money laundering is not a victimless crime. Laundered money funds organised crime, sustains corrupt regimes, and enables terrorist financing. Every successful laundered scheme reinforces the underlying criminal activity, fuelling cycles of exploitation and violence. For financial institutions, the risks are equally severe. Failure to detect laundering exposes banks to regulatory fines, reputation damage, and potential exclusion from international markets. It’s a stark reminder that the stakes are not just moral but existential.
What makes laundering so elusive is its reliance on legitimacy itself. Unlike overt fraud, where criminals attack the system in obvious ways, laundering relies on the financial system’s everyday functions. It uses ordinary accounts, routine transactions, and lawful institutions as its camouflage. It’s challenging to preserve the speed and efficiency of global finance while ensuring it is not exploited for crime. Too much friction can stifle legitimate activity, while too little opens the door to abuse. Navigating this balance is one of the great challenges of modern compliance.
A Moving Target
Money laundering can be described as a crime without borders, and in today’s hyper-connected world, that description has never been more accurate. Illicit funds now move with the same speed and ease as legitimate funds, slipping through jurisdictions in seconds and disappearing into layers of opaque financial networks. What once required couriers with suitcases of cash can be achieved with a few keystrokes. The result is a global problem that seeps into nearly every corner of the economy, undermining governments, fuelling organised crime, distorting markets, and damaging trust in the global financial market.
If you’ve ever wondered why news headlines so often feature war, terrorism, and organised crime, it’s important to remember that none of these tragedies would be possible without money quietly moving through the global financial system. Behind every act of violence lies a trail of funds that often appear, at first glance, to be completely ordinary transactions. You might assume stopping this flow would be straightforward, but financial institutions face two immense challenges. First , detecting illicit funds is incredibly complex. Criminals constantly evolve their tactics, using sophisticated and ever-shifting methods to mask the origins of their money. Only advanced analytics and modern technology can keep pace with such professionalised networks. Second , banks must operate efficiently and competitively. They’re expected to balance strong anti-financial crime efforts with the realities of running a business, which naturally shapes the level of ambition they can commit to. Traditional monitoring systems have been the industry standard for years, even though their limitations are widely recognised. Transforming this landscape can feel like fighting on several fronts at once. But the potential impact is enormous. By shifting from a mindset of simply meeting requirements to one of embracing what is truly possible with today’s technology, we open the door to saving countless lives. That goal makes every step of progress not only worthwhile but essential.
Dr. Oliver Maspfuhl (Over two decades in the financial sector)
Money laundering is not static. As soon as one method is exposed, another emerges. We will be exposed to innovative money laundering schemes of the future. The constant evolution ensures that detection efforts can never stand still. The demand is to see beyond the obvious patterns. Traditional methods have laid the foundation, but they are no longer enough. We need to embrace new technology to help us in this fight against money laundering. We need to ensure that the financial systems can be fully trusted by society and that they remain a tool for growth.
Shell companies are a cornerstone of money laundering networks. Easy to establish and often registered in tax havens, these paper entities typically have no employees, offices, or genuine operations. Their sole function is to obscure ownership and control of funds. By layering transactions across multiple shell companies in different jurisdictions, launderers create a trail so convoluted it can take years for investigators to follow. Some countries have introduced beneficial ownership registries to bring transparency, but enforcement is inconsistent, and
DR SAURABH STEIXNER-KUMAR
secrecy continues to be a selling point in many of these financial hubs.
The digital age has only widened the playing field. Online gambling platforms allow criminals to deposit illicit funds, place minimal bets, and withdraw the balance as clean money. Cryptocurrencies and blockchain-based assets present an even more complex challenge. While blockchains are transparent in theory, the pseudonymous nature of digital wallets, combined with mixing services and decentralised exchanges, can make tracing transactions extremely difficult. Regulators face a delicate balancing act of encouraging financial innovation without losing control.
The stakes extend far beyond financial misconduct. Laundered money doesn’t just shelter the profits of drug cartels and corrupt officials, but it also fuels human trafficking and terrorism. Traffickers use intricate financial networks to mask the funds earned from exploiting vulnerable people, routing money through informal transfer systems, cash-heavy businesses, and global banks. Terrorist groups, meanwhile, depend on laundering to fund operations, purchase weapons, and recruit followers, often hiding flows behind charities or digital currencies. In both cases, laundering provides the lifeblood that sustains industries of exploitation and violence.
What makes money laundering particularly difficult to combat is the way it adapts to every attempt at enforcement. Stricter banking regulations in one region often push illicit flows to less-regulated markets elsewhere. This means that money laundering does not disappear but merely shifts shape and location. Furthermore, the integration of the global financial system means that weaknesses in one jurisdiction can have a snowball effect worldwide.
Governments and institutions are fighting back. The Financial Action Task Force (FATF) has set international standards on anti-money laundering (AML), urging countries to harmonise their rules and cooperate more closely. Banks and regulators are increasingly deploying
artificial intelligence and advanced analytics to detect unusual patterns hidden in transactions. But criminals are agile, often moving faster than regulators can respond. Ultimately, tackling money laundering requires a combination of global coordination, technological innovation, and political will. Transparency in ownership structures, stronger cross-border cooperation, and accountability in both public and private sectors are essential. Money laundering may be a crime without borders, but that does not mean it is unstoppable.
The most traditional and trusted way of detecting money laundering in banks and financial institutions is the rule-based monitoring methods. These are the basic tools that are straightforward, transparent, and loved by the compliance departments. There is a very good reason that these methods exist, as these are simple to implement and at the same time easy to explain. There is a clear set of thresholds and scores that define the reasoning behind any suspected transaction. Some examples could be large cash deposits, transfers to high-risk areas, or an unusually high number of transactions.
Simplicity, although it is a sought-after trait, because it means that the regulators are at peace, also results in complacency. If banks want to be ahead of the criminals, they need to be flexible in their approach. They have to look beyond the simplified assumptions of rule-based systems and evolve. They need to move quickly before the criminals can find newer ways to evade the police. A smart criminal may use certain unknown patterns to move money before new rules can be set up to detect it. It’s a hide-andseek game, where the seeker is only looking in places where the hider was found before, unaware of the evolution of the playing field.
There is also the burden of maintaining a large team of investigators with the traditional approaches, because

these methods generate an extremely large number of false positives. This is well understood by the example of a legitimate customer who has had a new business client and therefore suddenly deals with a larger number of transactions or transactions in foreign currency. Or another legitimate customer who has had a major change in lifestyle due to marriage or having children, and suddenly has a different transaction pattern. In both these examples, the customers may be flagged, and investigators will have to use their already limited time to file and close these legitimate cases. Such a system is not only inefficient but also introduces fatigue, where the investigators become desensitised and overlook potentially genuine cases.
It is a well-known fact that a vast number of alerts generated by the rule-based systems are false positives; however, a manual investigation into these is what keeps the financial system running with well-known caveats. This is still by far the most standard way around the world, which, although draining financially and on the individuals, is accepted by the regulators. The once-advanced system is showing its age due to the changing environment. We have several new advanced financial offerings in the form of new digital platforms and cryptocurrency exchanges, which generate activities that are too subtle and too complex for the rule-based methods to detect.
The transaction monitoring field is also evolving thanks to recent technological developments. There is more research in dynamic and intelligence-driven tools like machine learning and artificial intelligence. There are smarter and more efficient ways that are in use and in development to detect suspicious behaviour of criminals. It should be seen as a necessary and natural evolution of the blunt tools from the past to the newer and sharper tools of the present and future. In retrospect, the rule-based systems form an essential starting and base point from which we build the solutions of the future to assist the fight against money laundering.
The rise of AI (artificial intelligence) and data science may be seen as a new phenomenon, but the field has existed for a long time and has been hiding in plain sight behind the more traditional concepts of psychology, statistics, and computer science. Slowly but steadily, it is reshaping the landscape of transaction monitoring, not only from the technological point of view, but also from a philosophical one. We are no longer simply looking at some definitions from the textbooks, but rather exploring hidden patterns. We are looking at recognising the context, intent, and other sophisticated reasoning that may point to criminal behaviour.
At the core of the new generation of money laundering detection are several key techniques that are transforming the financial industry.
Anomaly detection can be considered as the very basic kind of monitoring within the AI-driven tools. I like to compare
it with the concept of personalisation, where a certain routine behaviour of a customer is considered normal, and anything that is out of the ordinary of this personalised bubble is a cause of concern.
Conceptually, every customer forms a unique profile, and this is constantly adapting to the change in behaviour within a certain limit. The power of this method lies in its adaptability, as it is capable of understanding the subtle signs of a shift in behaviour. The goal is not to remove the false negatives but rather to reduce the noise significantly and allow the investigators to put effort into more meaningful alerts.
Predictive Analytics:
Anticipating Risk
Predictive analytics is a different way of looking at the problem. Where the traditional way of detecting money laundering is to detect it within the transaction behaviour after it has already taken place, predictive analytics tries to identify it before it occurs. I like to think of the movie Minority Report , where the idea is to look for signs and make a conclusive prediction of crime and potentially stop it.
Looking at the historical patterns of transactions and other metadata like demographic information and general behaviour, certain AI models can identify some signs of risk. Taking the movie example, if a person who has never held a gun is lifting and pointing a gun towards someone with anger on his face and a potential motive, it is safe to predict that he might shoot. Such a sign should be alerted for investigation.
Such predictions can not only help in identifying crime but also support the resource allocation that can then be based on the risk profiles. Prioritisation and categorisation of the investigations can be the difference between catching the criminal and letting him slip through the mountain of false alerts.
Entities involved in money laundering do not just use one instrument within one institution, but a large and complicated network to hide the trails. This may involve using differently spelled names and multiple accounts and transaction routes, to name a few that are hard to link together. Entity resolution aims to link all the fragmented pieces together to form a complete picture so that they can judge the transactions.
The technique can involve using linking and mapping tools to view the network of entities and unravel the broader behavioural pattern. Such a sophisticated mechanism is only possible with the AI-driven approach and could not be captured with the static rulebased algorithms.
Transaction monitoring has moved far beyond simple transfers of amounts in numbers. It also exists within the
DR SAURABH STEIXNER-KUMAR
subtle descriptions that form these transactions. There can also be unstructured forms of information from media and public activities. Human language is a complex thing to comprehend for computers, and the modern tools are now able to look deeper into these messages where the previous approaches could not.
Natural language processing is able to demystify the messages that follow transactions and may be able to generate alerts based on risk. Not only that, but the procedures of knowing the customer and regular screenings are also boosted with these new techniques and play their part in fighting money laundering.
It is crucial to note that the advancement in technology should be seen as a new development in sharpening the tools that we have at our disposal to fight money laundering. The objective of using new technology is not to replace humans or their expert judgment in detecting wrongdoing, but rather to make them better equipped to do the job more reliably and efficiently than ever before.
Such an approach is not only putting more trust in our financial systems, which is extremely important for our society to run, but also giving a sure sign to criminals that it is increasingly difficult to get away. From the regulators’ point of view as well, embracing technology to better the skills of detecting money laundering is not only a luxury but a necessity.
AI, over the past few years, has captured everyone’s imagination for the right reasons, but there are also some misconceptions. It’s a philosophical question to tag something intelligent, and one that I do not aim to answer in this article. However, basic facts can help us to understand the AI systems better and get the most out of them. There is no doubt that the advancements in the field have made the task of catching the suspicious transactions much more feasible, but the decision-making power of AI should not be seen as the ultimate truth. These systems, as promising as they seem, do suffer from many challenges. The systems are reliant on the quality and quantity of data that is presented to them, and that is one of the main obstacles, in addition to their adoption and acceptance within the industry.
One may have the most advanced models, but their results may be skewed if the supplied data is not accurate, comprehensive, and consistent. As it turns out, the financial transaction data is very fragmented, and even after many efforts to clean and complete it, there are many irregularities. Additionally, systems change over time, and there is a need to consolidate the data from the past to the present, legacy to strategic systems. Often, onboarding the data to be used by the new advanced system also leads to inconsistencies, which can then form a snowball effect affecting not only the present systems, but also systems of the future.
The scale of data also makes the task extremely difficult. The modern financial solutions generate a much larger amount of data, and the systems need to adapt to the increased load. Sure, the AI systems can help here, but they still require human intervention. The burden of governance, with all the challenges combined, can amplify the risks of misguided decisions. Therefore, rigorous data controls are an absolute necessity.
The absence of the actual ground truth is an unsolvable problem. In the traditional supervised machine learning models, one could improve predictions by comparing the results to the correct answer; however, in the search for suspicious transactions, this is the big unknown.
Suspicious activity reports (SARs), for example, do not always confirm criminal activity; they merely reflect suspicion. Any system based only on the reproduction of SARs can merely form a feedback reinforcing biases introduced by human investigators rather than the objective truth.
It’s a double-edged sword where one cannot increase the number of false positives to catch everything suspicious as it means increasing the resources and draining the institutions, and at the same time, cannot also increase the number of false negatives as it means the institution is posing a financial risk and risking its reputation. Striking the right balance is a very complex task that can only be bettered with iterations, as there is no real benchmark to rely on.
In the financial industry, there are always checks and balances, and the same is true for the AI systems. Regulations demand explanations and clarifications for all the processes and outcomes, and the institutions should be able to reliably explain them. This is a great challenge as many of the advanced systems work in their black boxes, and it presents a significant challenge in terms of time and effort to justify and unravel these boxes. Just because a model outputs something does not mean that the regulator may accept it.
There are XAI (explainable AI) techniques used for such activities. The idea behind them is to point out the features within the model that influence the decisions in terms of importance. The goal is to increase the transparency of the model and strike a right balance with the regulatory body in terms of effectiveness and explainability. More work needs to be put into such symbiotic activities.
Success depends on combining machine intelligence with human judgement, and innovation with accountability.
DR SAURABH STEIXNER-KUMAR
The balance between innovation and accountability is a tricky one. The financial institutions are put under pressure by the regulatory bodies to make sure all the appropriate models are in place to catch suspicious activities, but at the same time ensure transparency and explainability. On the other hand, the institutions also need to embrace the most cutting-edge AI techniques to keep pace and catch any suspicious activity while maintaining legitimacy.
The solution lies in the governance frameworks that balance innovation and oversight. It’s beyond the AI models and into data management, auditing infrastructure, and investigations. It’s a clear call for collaboration between the teams that traditionally sat in individual silos.
AI-powered transaction monitoring is not a silver bullet. It is a powerful tool, but one that must be handled with care. The challenges of data quality, uncertain ground truth, false positives, and explainability are not roadblocks but checkpoints. It serves as a reminder that technology alone cannot solve financial crime. Success depends on combining machine intelligence with human judgement, and innovation with accountability.
As criminals evolve their tactics, the institutions will need to keep up the pace to maintain their reputation and public trust. The future of transaction monitoring will be shaped not just by how smart AI techniques become, but by how responsibly it is managed.
THE FUTURE OF TRANSACTION MONITORING
Transaction monitoring is evolving into a race between the criminals and the technology that is used to catch such activities, and is no longer just about meeting the compliance requirements. The upcoming phase of innovation by the major financial institutions will define and shape their future.
Blockchain is a great tool in the eyes of the compliance teams, as it is a technology that cannot be altered once recorded and gives transparency. Regulators can follow the recorded flow of funds across the borders and investigate
the truth. However, there are legitimate concerns of privacy in public blockchains and confidentiality in private ones. There is more work to be done to combine AI with blockchain.
The complex ways the money moves make it hard to detect with traditional AI methods. To understand the complexity of such networks, advanced neural networks and reinforcement learning can be used. Such models can process diverse data such as structures, descriptions, and network relationships to uncover patterns too subtle for simpler methods. However, the caveat is that the more advanced the model becomes, the harder it is to explain.
Perhaps the most transformative innovation is dynamic risk scoring. Today, customer risk ratings are typically static, assigned at onboarding and updated only occasionally. But financial behaviour changes constantly, and static scores can quickly become outdated.
Dynamic scoring can calculate the risk on an ongoing basis based on real-time data. If the customer is suddenly involved in higher-risk transactions, then the risk profile could be updated so that investigators can adapt and act quickly. This has the advantage of faster reaction times to catch suspicious activities.
The future of transaction monitoring will be defined by resilience. Financial crime in terms of money laundering will keep on adapting to the newer globalised financial environment, and therefore, the technology of blockchain, deep learning, reinforcement learning, and dynamic scoring should not be seen as final solutions but rather as stepping stones to the ever-evolving technology landscape.
What’s clear is that static, rule-based monitoring is no longer enough. The future belongs to systems that learn, anticipate, and connect the dots faster than criminals can exploit them. In that future, institutions won’t just react to suspicious activity, but also predict and prevent it.
AI is not just enhancing transaction monitoring, it is redefining it. For financial institutions, regulators, and data scientists alike, this evolution offers both opportunity and responsibility in the ongoing battle against financial crime.
What’s clear is that static, rule-based monitoring is no longer enough. The future belongs to systems that learn, anticipate, and connect the dots faster than criminals can exploit them.


To hire the best person available for your job you need to search the entire candidate pool – not just rely on the 20% who are responding to job adverts.
Data Science Talent recruits the top 5% of Data, AI & Cloud professionals.
Fast, effective recruiting – our 80:20 hiring system delivers contractors within 3 days & permanent hires within 21 days.
Pre-assessed candidates – technical profiling via our proprietary DST Profiler.
Access to talent you won’t find elsewhere – employer branding via our magazine and superior digital marketing campaigns.
Then why not have a hiring improvement consultation with one of our senior experts? Our expert will review your hiring process to identify issues preventing you hiring the best people.
Every consultation takes just 30 minutes. There’s no pressure, no sales pitch and zero obligation.



ACAIO I consulted for explained that their company's CFO consistently blocked AI initiatives over return on investment (ROI) concerns, killing them before they could begin. I saw a Copilot rollout shelved because, even though the pilot showed efficiency gains, those gains could not be translated into a Profit & Loss (P&L) impact.
Leadership courts headlines with AI’s strategic promise, spotlighting the smallest proof-of-concept, yet inside the boardroom they default to ROI gatekeeping that, as the next sections reveal, systematically erodes that promise.
THE DISRUPTION THREAT
AI functions as a general-purpose technology, similar to electricity, the internet, or mobile computing. These technologies don't just improve existing processes; they reshape entire industries and create capabilities that didn't exist before.
History provides clear examples of the risks organisations face when they fail to recognise and adapt to transformative technological changes. For instance, the automotive industry initially dismissed Tesla's electric vehicles as niche products without significant market potential. Established players focused on incremental enhancements to traditional combustion engines, overlooking the disruptive impact of electrification and software integration. Meanwhile, Tesla redefined the industry's core by prioritising these technologies. Within a decade, what began as scepticism turned into an existential crisis for legacy automakers. Today, traditional car companies are urgently retooling factories and overhauling software systems as they strive to catch up with Tesla, which has already set new industry standards.
Even companies that emerged during the internet era are not immune to this threat. Firms like Uber and Lyft, once considered
BIJU KRISHNAN is a seasoned AI strategist and governance expert with over 20 years’ experience. For the past 12 years he’s focused on big data, analytics, and AI. His career spans foundational technology roles at global leaders like Shell, T-Systems, Accenture, Data Robot and Hitachi, giving him a deep, practical understanding of enterprise data challenges.
With his focus on bridging business needs and technological implementation, Biju now specialises in pragmatic AI strategy and governance, helping organisations elevate their AI maturity while ensuring compliance.
pioneers of innovation, are compelled to evolve or risk obsolescence. While Uber has established a capable AI engineering division with a strong track record, it now faces mounting pressure from competitors leveraging sustained technological investment. For example, Google's ongoing commitment to self-driving technology since 2009 has resulted in Waymo, a fleet of autonomous taxis that poses a direct challenge to Uber's business model. This underscores the importance of continuous innovation and the danger of complacency, even for those who once disrupted their own industries.
AI's value compounds in the same way. Early benefits appear subtle: better decisions, faster experiments, new product features. Over time, these accumulate into structural advantages.
History provides clear examples of the risks organisations face when they fail to recognise and adapt to transformative technological changes.
Organisations develop capabilities they couldn't buy or predict at the start. The companies that treated the internet as a cost centre instead of a strategic asset in 1995 never became the ones that defined 2005.
By mid-2025, research revealed a troubling gap: executives couldn't translate generative AI initiatives into measurable ROI.
● One MIT study captured headlines with a stark number. It reported that 95% of enterprise AI pilot programmes fail to generate quantifiable financial returns.
● Atlassian, whos e Confluence and Jira tools dominate knowledge work, published similar findings in its AI Collaboration Index 2025: 96% of companies saw no dramatic improvements in efficiency, innovation, or work quality.
These statistics drew intense media coverage, amplified by the ongoing narrative of AI as the next industrial revolution. Yet this enterprise adoption failure is old news to anyone who worked in AI before ChatGPT. VentureBeat reported in 2017 that 87% of data science projects never reached production. A 2020 Forbes article found that only 15% of leading firms had deployed AI capabilities at scale.
Boards and C-level executives acknowledge AI's strategic value, but doubt their ability to capture it. That scepticism forces CAIOs and CDAIOs to justify every investment, reinforcing the ROI gatekeeping that systematically erodes AI's strategic promise.
Traditional AI ROI assumes model accuracy equals business value. A fraud detection system promises millions in savings from fewer false positives. A churn model identifies at-risk customers for retention campaigns. But these calculations ignore the messy middle. The fraud alert means nothing if investigators lack the capacity to act. The churn
prediction fails if marketing can't execute personalised outreach. The model's value depends entirely on the business process it touches, yet finance teams attribute outcomes solely to the algorithm.
Generative AI productivity promises are no different. A client in the pharmaceutical industry piloted Microsoft Copilot with two hundred employees. The data showed an average of four hours saved per week per employee. Their business case multiplied hourly rates by the time saved and presented it to the CFO. He rejected it immediately. As a company veteran, he knew time savings don’t directly impact the balance sheet. However, a doubled Microsoft subscription does, and it would blow the IT budget.
Maybe a different angle would have worked better. Instead of pushing ROI, they could have pitched Copilot as workforce development, a low-barrier way to upskill current employees. The alternative is hiring AI-savvy people from scratch, with recruiting fees, onboarding time, and training on company knowledge. Rather than fighting for IT dollars, they might have approached HR for learning and development funds. That conversation probably wouldn't trigger the same budget alarms.
The point I’m trying to make is that if you know the ROI argument you are making is wishful thinking, don’t expect the CFO to see it any differently. If your pitch doesn’t have a direct ROI link, find other pillars to support the investment that are hard to dismiss.
Internal alliances are also very important. Business leaders are eager to position themselves as adopters of futuristic technology. Instead of categorising your AI investments under IT or data, seek sponsors across the organisation to strengthen your case.
A BCG India executive shared a story about creative technology investment. Their client issued a sixty-page RFP for new CRM software.
Traditional IT suppliers responded with three-hundred-page proposals that mentioned AI at least a hundred times but were clearly the same old methodology repackaged.
Most suggested a two-to-threeyear timeline with around a hundred staff on the project. In contrast, a small insurance-specific software firm responded with a QR code linking to a sandbox that already implemented the client's requirements, plus additional features from their domain expertise. They built the functional demo in two weeks and proposed a two-tothree-month implementation timeline with pricing tied to actual business outcomes. While not directly about AI development, this shows how relying on past experience to estimate costs can lead to massive overinvestment.
AI platforms can cut experimentation and proof-ofconcept costs by creating repeatable ways to build and run AI systems. Reinventing the wheel for each use case is how companies report no return on investment.
I like the 20/20 rule from Tobias Zwingmann: keep proof-of-concept experiments under twenty thousand dollars and twenty days.
With the right approach, doing more with less is achievable today. Cloud computing and AI-assisted coding make it possible, and investing in AI platforms helps you create repeatable deployment patterns.
If your organisation’s culture requires ROI discussions to get anything approved, you have to adapt your AI strategy to that reality.
A friend who is a CAIO at a large retailer faces this exact situation. He chose to focus GenAI on the shop floor instead of knowledge worker productivity. The CFO, a long-tenure employee, understands shop floor maths intimately and is receptive to anything that helps manage increased business with fewer people. Focusing on the shop floor, where staffing costs correlate directly with per-shop revenue, makes ROI arguments easier to formulate. Pick battles you can win rather than fighting on all fronts.
Despite the increasing prevalence of AI across industries, only a select group of organisations possesses the capability to clearly demonstrate the ROI from their AI initiatives. Although monitoring AI applications is gradually becoming an industry standard, many organisations still encounter major obstacles when attempting to connect these monitoring efforts to tangible business key performance indicators (KPIs).
For most, the challenge lies in integrating technical metrics with broader business outcomes. This disconnect makes it difficult to provide solid proof of the value created by AI projects. The task is further complicated by the existence of data silos within organisations, which hinder the seamless merging of relevant information.
Recognising these challenges, Chief AI Officers (CAIOs) should prioritise efforts to align business KPIs with MLOps and AIOps metrics. By working towards the integration of these data sources, organisations can gradually build a foundation that enables clearer demonstrations of AI-driven value. Over time, the availability of such integrated data will facilitate greater buy-in from company leadership, supporting more strategic investments in AI technologies.
While there is no one-size-fits-all solution, the following advice, drawn from field experience, can help secure crucial buy-in for AI initiatives:
Educate Leadership: Offer C-level education on AI's strategic importance to ensure leadership alignment.
Reframe Value: Acknowledge that some AI initiatives cannot survive a traditional ROI discussion; their value must be framed as a strategic investment.
Creative Budgeting: Source budgets creatively from various organisational pools – such as R&D, HR, or marketing – rather than burdening dedicated AI allocations. Bring shadow IT initiatives into the light.
Lead with Business Metrics: Where possible, lead with business outcomes, keeping ROI calculations in reserve, especially when they rely on speculative assumptions.
Build Efficient Foundations: Invest in persona-specific AI platforms to reduce the costs of experimentation and production deployment, enabling you to achieve more with fewer resources.
Engage Innovative Suppliers: Partner with vendors who offer innovative operating and financial models.
Choose Your Battles: If ROI is unavoidable, shape your AI strategy around initiatives where the correlation to value is easily demonstrated.
The rise of generative AI, like ChatGPT, has finally given AI leaders a seat at the table. It is now up to us to leverage this position, moving beyond rigid ROI measurements to deliver the transformative strategic value that artificial intelligence promises.
AKHIL is the Director of Property Share Market Economics. He specialises in making robust market forecasts and identifying key turning points in the economic cycle. His work has been featured in the BBC, Scottish TV, and Money Week magazine. He holds degrees from Oxford University and the London School of Economics, and is the author of The Secret Wealth Advantage.

The AI and tech sector has experienced an unprecedented flood of investment over the last two to three years, particularly in generative AI. But what are the implications of this boom? We sat down with Akhil Patel, a globally recognised expert in economic and market cycles, to explore this question.
Why is it important that people understand economic cycles?
The world is cyclical. Human beings and the systems they operate in display cyclical behaviour in many areas, particularly in stock markets and economies. You see periods of rising prosperity and activity, then suddenly periods of falling prosperity and crises. Many people have experienced both the upside and downside over the last 10 to 20 years. Understanding the rhythm of the cycle helps you assess where you are currently and what might be coming next.
Tell us about the 18-year cycle you study.
The hypothesis, supported by substantial evidence, is that there's a fairly regular 18-year cycle – sometimes 16-17 years, sometimes 20 years, but pretty consistent. All major financial crises and recessions in the past 200 years in Western economies, particularly the US and UK, show this pattern of boom and bust, always resulting in a major financial crisis at the end,
The world is cyclical. [...] You see periods of rising prosperity and activity, then suddenly periods of falling prosperity and crises.
followed by relatively lengthy periods of increasing activity, wealth, and prosperity.
What data sources inform your analysis?
I should clarify that I'm not the discoverer of this cycle – my work makes it practical for business and investment decisions. The foundation comes from American economist Homer Hoyt, who in the 1930s analysed land sales data in Chicago over the 19th century. He discovered an 18-year pattern of boom and bust in property values and identified five complete cycles as Chicago grew from villages to a major metropolis.
We use land prices and land sales as fundamental data. In the modern economy, we track house prices. I also use money supply data, since banking system activity strongly influences property markets. The bond market and yield curve provide good warning signals about recessions. Stock market data, particularly homebuilders, is useful because the market is a price discounting mechanism, typically three to six months ahead of events.
Most Western countries are now synchronised to the cycle. In the 19th century, the UK and the US exhibited the 18-year pattern but were opposite each other. After World War II, all countries reset at the same point due to reconstruction in the late 1940s and early 1950s. They all experienced a major crisis in 2008.
Interestingly, in countries that had been really beaten back, such as Japan, they had a major boom in the 1950s and 1960s. Japan actually had a relatively minor crisis in the 1970s when we had a major crisis in Western economies. But very famously, 18 years after that, Japan had a really significant crisis in the early 1990s.
The real question as we go forward now is the extent to which China also exhibits the same pattern. The Chinese economy is a bit different. It has capitalistic characteristics, but also very heavy state intervention. But the signs are that in the Chinese market, property plays a central role. There's a lot of leverage against that property.
We use land prices and land sales as fundamental data [...] Land is essentially a scarce asset that doesn't get created – it's a gift of nature. Therefore, whoever owns land has monopoly pricing power.
Why are land and property values so important to the cycle?
Any economic activity requires land because it must take place somewhere. Land is essentially a scarce asset that doesn't get created – it's a gift of nature. Therefore, whoever owns land has monopoly pricing power. While there's competition in labour and capital markets that reduces surplus, the residual value flows to land. Even if you own your business property, the extent to which you're making profits tends to get funnelled into the land market.
This makes land attractive for speculation, buying land, holding it, and selling it for a higher price tomorrow. It also underpins collateral in the banking system. Banks can push credit into the property market, enabling people to pay more for land. But when it comes down to it, it affects what the banking system can do. So it has a dual role in both boom and bust.
What leading indicators would you use to spot market turns?
Construction activity and house prices are obvious indicators. Land is very locational, and towards the cycle's end, the most speculation occurs in relatively small towns or at city edges. Money supply is crucial – if banks are pumping money into the economy, it's largely going into property markets.
I also use the stock market. If homebuilding stocks decline while the broader market rises, it suggests analysts are forecasting lower future earnings, indicating a slowdown coming in the property market and potentially the broader economy.
Walk us through the current cycle from 2007-2008 to today.
It's an 18-year cycle – sometimes the first seven years are shorter or longer, and the second seven years vary, but the final crisis recovery phase is fairly
regularly around four years.
The cycle begins when you're really feeling difficulties from the last crisis. The banking system is on its knees, banks aren't lending, sentiment is negative, house prices are down, and the stock market has dropped typically 50%. But that's when the crisis ends and the new cycle starts.
The previous cycle peaked around 2007, and the current one started in 2011 or early 2012. Remember, in the UK, we were talking about a triple-dip recession. Mario Draghi said, ‘I'll do whatever it takes to save the euro.’ Big statements like this often mark the cycle's turning.
Activity begins, often in new industries related to new technology. I'd particularly point to everyone having 4G smartphones by the early 2010s, which birthed numerous industries affecting banking, dating, transportation, and accommodation. This drove investment in Silicon Valley and London. By 2012-2013, construction cranes appeared, and property markets burst in 2013.
You'd expect about seven years of upward movement, so around 2019, you should have shown slowdown signs. We did get that, though people weren't paying attention. The world was slowing into COVID, which effectively ended the mid-cycle recession. Then we introduced an enormous stimulus that started the second half.
What might have taken four or five years happened between mid-2020 and early 2022. Property prices went bananas. Central banks panicked in 2022 about inflation and took rates from zero to north of 5% very quickly, which has somewhat killed what might have been a longer boom.
Nonetheless, we're getting close to the current cycle's peak. You'd expect the next four years to involve a fairly significant downturn, if not a financial crisis.
No two cycles repeat exactly. The US was at the centre of the 2008
crisis, so it's likely the epicentre might be elsewhere this time. Areas going crazy with construction and speculation – the Middle East, parts of Asia, Japan, and Germany – are candidates. You look for countries with the most rapid property price increases, construction, optimism, and excessive behaviour.
Did the COVID pandemic change the trajectory of this cycle?
COVID was incredibly disruptive. The money pumped directly into people's bank accounts was unprecedented. When people emerged with record savings, they went for it – at a time when businesses had shut down and supply chains were restricted. Sellers had greater pricing power, demand was price-insensitive, and we had an inflation burst.
That behaviour you'd normally expect toward the end of the second half. The final two years before the peak usually have the greatest mania. This cycle's variation is that we got the most excessive behaviour early. However, given the share prices of companies like Nvidia and what's happening in AI, we're seeing manic behaviour right on time. So it's not that all of the excessive behaviour has occurred in the first couple of years, but the AI investment mania is the variation for this cycle.
Is the AI investment surge a bubble?
Yes. Looking at prices people pay relative to current or prospective earnings, I can only call it a bubble. There's enormous hype. The business case for some AI companies isn't as strong as it should be. If you're spending hundreds of billions on training models, you'd want a greater guarantee of proper returns.
Pricing and fundamentals have taken different paths – a classic bubble indication. The interrelationships between main AI players are concerning: Nvidia investing in OpenAI, circular contracts, Nvidia's exposure to large customers in Taiwan (significant geopolitical risk), and Nvidia's share price significance to the overall US market. There's enormous
interconnection. When one thing falls, it could have a significant domino effect.
Many people know about this, so some concern might be priced in. But historically, it's the things people haven't thought about that trigger crises. People weren't talking about subprime mortgages in early 2007. Maybe data centres, which require land and bank credit, face regulation that squeezes activity, brings prices down, causes bank failures, reduces lending, creating a cascading effect.
No two cycles repeat exactly. The US was at the centre of the 2008 crisis, so it's likely the epicentre might be elsewhere this time.
Which countries might move first in a 2026 downturn?
Parts of the US have an enormous investment there. But look at Dubai and Saudi Arabia – building skyscrapers, artificial islands, ski resorts in deserts. That's malinvestment.
The UK has spent the last 10 years arguing about Brexit and hasn't really had a very crazy speculative boom like we had in the 2000s. So I don't think it would trigger the crisis, but it would be affected by it, of course. Ireland and Spain, affected by the Euro crisis last time, have had significant property booms. A left-field suggestion would be somewhere like Germany. The German government was quite pleased at how it handled the last crisis because it hadn't had much of a property boom and didn't need to bail out the banks in the same way that the US government and British government did. Maybe people there are less aware of the consequences of some of these things related to the property market. But on the other hand, things are quite flat in Germany, as I understand, given the effects of decline in manufacturing and the Ukraine war.
Triggers are usually where there's been the most rampant speculation.
I'd say the Middle East is probably more likely.
Are there parallels to the dot-com bubble?
The dot-com bubble occurred midcycle, about seven years in. The US had a six-month recession in 2001 with no banking system effect. The AI bubble is more related to the cycle's end and decline in land prices. AI is a huge global investor linked to banks and credit providers. So there are some parallels. Both involved enormous capital investment and overinvestment in infrastructure capacity. They certainly have those two things in common.
Another interesting parallel is Japan in the 1980s – industrial conglomerates with preferred banking partners in incestuous groupings. Banks lending to companies like Mitsubishi to buy and speculate in land would boost Mitsubishi's share price, which would boost the bank's share price because it owned shares in Mitsubishi. I see parallels to the current AI space.
Another parallel is the railway booms of the 19th century –enormous capital investment in lines that could never make returns, yet there was hype and speculation driving share prices up. Ultimately, hot air underneath the claims.
When will the next crash occur?
For the last 10 years, we've highlighted 2026 as the likely peak – when you don't get much more residential property market appreciation. You'd then expect six to twelve months later to be at the start of a significant financial crisis. The residential property peak was probably 2007, maybe late 2006 in the US. The financial crisis didn't really hit until late 2007 and built up in 2008.
We're arriving at the peak now, might get there sometime this year, and you'd expect not long before a major crisis – maybe 2027.
There can sometimes be longer lags. In the 1920s, the US residential peak was 1926, but the commercial market boomed in 1927-1928. Manhattan skyscrapers were built well
over demand assessment – building for building's sake, with no genuine tenants. Then a really significant crash in 1929-1931.
I don't think we're in the same era as the 1920s. The base case is peak this year, then looking for a major crisis within a year after that.
How do you define ‘peak’?
The top of the property market, the land market. Residential prices stop going up. They may not go down initially – might go sideways. There's an argument we're starting that period now. I think we'll get a bit more before the peak. Data is often lagging by two or three months.
The stock market tends to peak after real estate. Sometimes it's quick to price in crisis problems, sometimes it's longer. If something significant happened – trade war ending, Fed reducing rates to 2%, Ukraine war ending, US-China trade war stopping – it may artificially stimulate things longer. You're living on borrowed time at this cycle point.
Against a worsening economic backdrop, we might see a very volatile stock market – big down moves, then the government pumping money in. Trump sets store by stock market performance, so the government might intervene. It could be a series of big moves up and down, like the
late 1970s and early 1980s. By the early 1980s, investors had had enough – Businessweek ran "The Death of Equities" in August 1982, which was pretty much the best time to buy stocks in 20 years.
It's not a one-time event. Even in 2007-2008, there was nearly a year between Bear Stearns and Lehman Brothers collapsing.
How might this crisis play out? There's a peaking land market as a backdrop. Real estate stops rising. Delinquencies increase. Then something monumental, like an AI bubble crash, occurs.
This has a dual effect. First, interconnected companies and financing providers collapse. Second, a symbolic effect – something major crashed, so people examine all investments and pull back. This cascades to other sectors. Banks lend less, and businesses fail. It's like dominoes.
The first sign of the problem in the last cycle was in February 2007, when HSBC reported losses on some of its funds. That led to a bit of a sell-off in the US market – it soon recovered, but the bond market started to price in problems. Then there was a period of calm. The stock market got back up. There were problems in the summer: everyone might recall the run on
Northern Rock, which had been borrowing very short-term money to lend to people buying property. That couldn't be sustained because interest rates were moving up, at least in the rate of interest that banks lend to each other. Then people got worried about the cash that was in the bank, and the first run on a British bank in 150 years happened.
Then that went away, and markets got up to new highs. But clearly underneath, there were a lot of problems. In March, Bear Stearns collapsed when it was unclear to what extent central banks were backstopping the system. Then there was the series of rolling crises during 2008 and 2009.
Could we see sovereign debt defaults?
Default, maybe not, but bond market problems – the rate they pay on borrowings – likely, given debt levels, lack of confidence, and concerns about the dollar's future role.
We saw a taste in September 2022 when Liz Truss spooked bond markets with spending plans. The Bank of England dealt with it, but it created a rate spike we've never really recovered from.
The US might experience something similar, partly because people aren't rushing into dollars like before. Central banks are buying gold, diversifying reserves. BRICS countries are looking to create financial systems less dollar-based, maybe commodity-based or with bigger roles for Chinese currency or currency baskets.
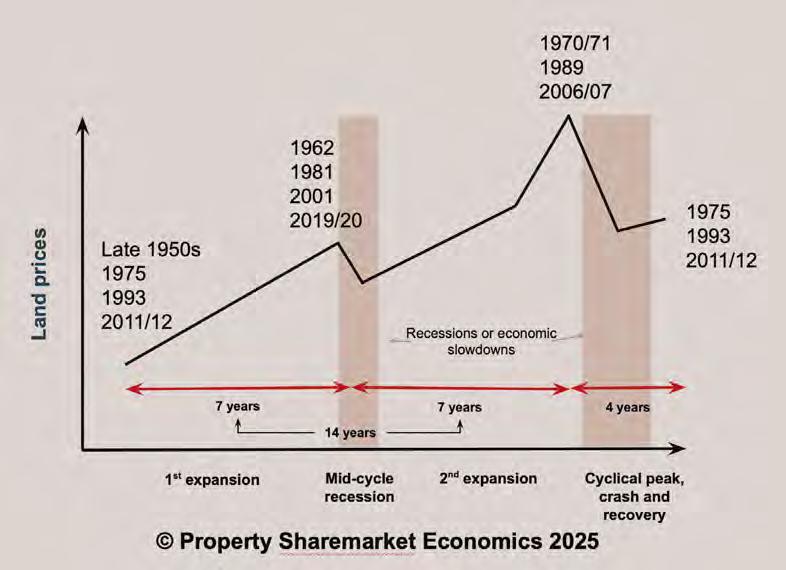
The crisis will play out differently from last time. Western countries might have less of a safe haven role because they're indebted, and there are alternatives. This will create significant panic if default looks possible. Countries can't actually default unless they've borrowed in currencies that are not their own. If it's their own currency,
they can print as much as needed. There are consequences, but no technical default.
What about Bitcoin as a safe haven?
I've had that thought for some time, but have been surprised by Bitcoin's price action recently. Gold has surged toward $4,500, silver above $50 for the first time, but Bitcoin's been strange – moving up and down. It's early to conclude either way, but I'm not sure the thesis is as sound as I thought earlier this year.
When you get to a cycle's end, people must park money somewhere. Above certain levels, you can't keep it in banks. Deposit insurance might not work. Some big tech companies sitting on enormous cash might see inflows. Maybe the US dollar and government for being tried and trusted at a size people can use. Also, the gold market. Bitcoin might be one of those markets. You'd have to look at different property types or stock market parts. Maybe Nvidia increases in value because of that.
We're coming out of a cycle with international financial arrangements quite different from when we started. Know how the cycle has played out in the past, have your eyes open, and be prepared for something different.
Are bank bail-ins possible?
Yes, but they are more likely in countries that can't access their currency and need ways to bail out institutions. I'm looking particularly at Eurozone countries where acquiring euros in a crisis depends on Brussels' decisions.
It's not universally going to happen. Many governments have given themselves the option, but I'd be surprised if it's widespread. They'll use crises to advance policies like digital currencies or widespread stablecoin use in the US, changing bailout and stimulus dynamics.
We've had a taste – the UK's Eat Out to Help Out during COVID gave money on a time-limited basis for hospitality. You could do this more widespread, directly stimulating negatively affected parts of the
economy. The problem is it gets caught up in politics.
Inflation will drop in a crisis unless there's enormous stimulus in areas generating inflation. Otherwise, expect disinflation and deflation when interest rates drop.
The comfort is that tech stocks tend to move upwards first in recovery phases, symbolic of capital and investment in ideas flowing through tech. If you're in that space, it can be an exciting time with many opportunities. Recovery takes place there first.
We're scratching the surface of these technologies' potential. While we're in a bubble with overinvestment in AI, fundamentally, the technology is game-changing with the right applications. Similarly, many crypto coins are rubbish, but the technology is game-changing for revolutionising payments and contracting. It's going to fundamentally reshape the economy.
Productivity gains in the next 1020 years will be enormous and give me optimism for the next cycle. The key is surviving the downturn. If you can do that with the ability to invest or make decisions out of opportunity rather than necessity, you can be in a really good position for the next cycle's beginning – the best time to invest and expand.
What should people do in these final 12-18 months?
It depends on circumstances, but generically: first, if you're invested in crypto and stock markets, ensure you're not over-leveraged. Don't commit more money. Build reserves. Don't buy based on capital gain just because it rose 20% last week. Stick to fundamental values.
Second, we're potentially at a time of difficult conditions. Assess your businesses, investments, and borrowings. Under different scenarios – revenue declining X percent – can you survive? Can you reduce costs? Continue servicing debt? Ensure that for a few years you won't be forced to sell something you don't want to. You definitely don't want selling during a crisis – you won't get good prices and
you'll be forced to sell your best stuff.
Do you have any advice for tech business leaders and founders approaching a downturn?
Cash tends to be scarce in these organisations, so build that up. If you have borrowings, manage them and handle not being able to roll over debt during a crisis. Banks having problems won't lend on speculative business opportunities.
The majority of expenses are staff expenses. Knowing how to handle that cost base during a downturn is very important – reducing hours or headcount. As unfortunate as it may be, the goal is survival.
But also look around. If you're surviving with reserves, look at businesses you might partner with or acquire as things recover. It's both retrenching and being willing to expand, having survived.
Can you tell us about your book?
The Secret Wealth Advantage: How You Can Profit from the Economy's Hidden Cycle is structured as a journey through the cycle. I take readers through each stage using different historical episodes, outlining how each stage plays out, what to look for, and investment decision ideas.
I explain why the cycle happens – the role of land capturing gains of progress and development. I explain why people don't see the cycle, how money and banking fit in, why investment managers don't understand how to navigate it, and how to stay safe, avoiding fraudulent activity that tends to emerge at cycle peaks. It's both explanatory and predictive, giving people a clear idea of how the cycle plays out and how to take advantage of it.
How can people learn more about your work?
Visit propertysharemarketeconomics.com and sign up for our free newsletter. There's also access to archive material, so you can see what we wrote and said on podcasts in the past, some of the market calls we've made.
CHRIS PARMER is the Chief Product Officer and Co-Founder of Plotly, the premier Data App platform for Python. As the creator of Dash, Chris leads development efforts to make the framework the fastest way to build, deploy, and scale interactive analytic applications. As data science teams become a standard part of the enterprise, Chris works to ensure that even the most advanced analytical insights are accessible to everyone, whether or not they know how to code. His favourite part about working at Plotly is working with our passionate customers.

Can you tell us about your background before Plotly and what led to co-founding the company in 2013?
My co-founders and I are traditional engineers and scientists – I was an electrical engineer who dealt with R&D data in every job. Around 2013, we witnessed two major technological shifts that created a significant opportunity.
First, the entire industry was adopting Python as the primary language for data analytics across all sectors, particularly in science, engineering, and data science. Second, web browsers were becoming remarkably powerful application platforms, largely thanks to Chrome and Google’s V8 engine.
These changes revealed a gap in the technology landscape. We saw the opportunity to build a web-based visualisation layer featuring sophisticated interactive data visualisations rendered entirely in browsers – something completely new at the time. Since then, we’ve expanded from data visualisations into comprehensive data applications and now AI-powered data analytics.
How does natural language change the traditional analytics learning curve?
Natural language serves as a universal equaliser. Every analytics tool – Salesforce, Google Analytics, Tableau – has
unique chart builders with different paradigms: X versus Y, rows versus columns, dimensions versus measures. Each requires mastering complex UI-based interfaces.
Natural language eliminates this fragmentation. When pulling data from multiple systems, you can request visualisations in plain language without learning tool-specific interfaces. This could democratise data visualisation across organisations, removing the bottleneck of specialist experts who currently handle complex reporting requests.
How do you see AI helping non-technical users move beyond just viewing charts to actually understanding underlying patterns in data?
A picture still tells a thousand words – visualisation remains the primary interface for understanding data and scenarios. AI’s breakthrough is its ability to generate code that creates new visualisations, allowing users to examine data from multiple angles rapidly and efficiently.
Currently, humans still generate insights by interpreting visualisations, though this may evolve as vision models begin interpreting graphs and analytics directly. Today, these tools primarily accelerate the different ways users can examine data to develop their own insights.
In business settings, we see different user types –data scientists doing deep analysis versus business users focused on storytelling for strategic decisions. Do you envision these roles converging to use the same interface?
I view data science broadly as any computational work beyond basic data visualisation. While often associated with machine learning, many industries require heavy computation that isn’t necessarily ML – bioinformatics in life sciences, quantitative portfolio optimisation in finance, or complex scenario modelling in business.
Traditional drag-and-drop visualisation tools can’t handle these computational requirements, which is why Python-based tools are essential across these industries. We’ve built first-class interfaces through our Dash framework that let stakeholders interact with the scenarios and models that data scientists create.
AI is dramatically lowering barriers to quantitative work. In our latest product, data scientists can define models using natural language, while end users can still interact with published applications through GUIs. More importantly, if stakeholders want to create their own analysis, they can now do so using natural language prompts to generate their own scenarios.
While there are currently some complexity limitations for AI-generated data science models, that gap narrows daily. The exciting part is that everyone can work with the same Python backend – whether directly through code or via natural language interfaces. This reduces technology switching and creates a more unified workflow across different user types.
My biggest ‘aha moments’ occur when AI creates visualisations I wouldn’t have conceived myself.
Have you experienced moments where AI-assisted visualisation revealed insights that traditional analysis might have missed?
My biggest ‘aha moments’ occur when AI creates visualisations I wouldn’t have conceived myself. Our AI systems generate diverse chart sets, presenting users with multiple visualisation options they might not have considered.
LLMs leverage their world knowledge to produce charts highly relevant to specific industries or data domains. I might approach a dataset with preconceived ideas about analysis approaches, but then receive numerous alternative perspectives on the same data. This automatically generates new exploration pathways – a remarkable workflow that expands analytical possibilities beyond my initial assumptions.
Can you share a concrete example of this in action?
I’ve been working extensively with San Francisco’s public 311 call data – city complaints about issues like sidewalk trash or blocked driveways. Simply inputting this dataset immediately generated analyses I hadn’t considered: neighbourhood-by-neighbourhood response rate comparisons, year-over-year trend analysis, and performance assessments tied to our new mayor and administration.
The system automatically explored questions like whether response times had improved in different neighbourhoods, or if cleanup efforts had focused particularly around the Civic Center near the mayor’s offices. I approached the data with broad curiosity, but was immediately presented with eight different charts showing exploration directions – including several I hadn’t initially considered. This demonstrates how AI can expand analytical thinking beyond our initial assumptions.
311 CALL DATA VISUALISED USING PLOTLY STUDIO
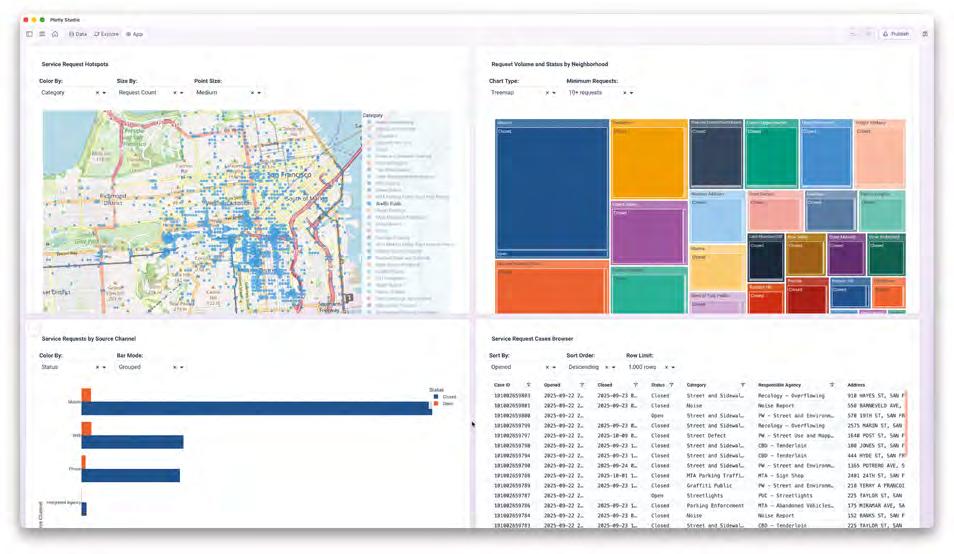
CHRIS PARMER
Have you encountered AI-generated charts that were misleading despite being technically correct?
Absolutely. This typically stems from data quality issues –the classic challenge where data preparation and cleaning represents 80% of a data scientist’s work. We’ve seen visualisations with missing bars that initially appear to be AI errors. Users assume the AI ‘messed up’ the graph due to missing data points. However, investigation often reveals that certain periods – like March in one example – simply aren’t present in the source data.
AI generates code to visualise data as provided, so the visualisation quality directly reflects the underlying data quality. The AI isn’t creating the data problem; it’s accurately representing flawed or incomplete datasets.
What about other technical challenges like outliers, binning decisions, or error bar methodologies?
Data analysis involves countless assumptions and choices: binning strategies, moving average windows, filtering criteria, shared versus independent y-axes when comparing visualisations. Often, there’s no definitively ‘right’ answer –AI makes decisions just as human analysts would.
Our product design philosophy focuses on surfacing these ambiguities through user controls. Rather than AI making hidden assumptions about binning intervals or moving average windows, we encode these choices into dropdown menus within visualisations. Users immediately see whether binning is set to one month or two weeks, whether the moving average window is seven days, or whether y-axes are shared.
This approach makes underlying assumptions transparent and adjustable, unlike chat-based AI systems
where these decisions remain buried in the model’s reasoning or generated code. Some of these hidden assumptions could prove dangerous if users can’t examine or modify them.
How do you see transparency’s role in building trust with AI-driven analysis?
Transparency is absolutely essential to our product. We embed transparency at multiple levels: users can adjust parameters in the final application interface, and we auto-generate specification files in natural language that describe exactly what the code does. Crucially, this specification is created by a separate AI agent to avoid bias from the code-generating system.
We’re also building transparent logging interfaces showing step-by-step data transformations in generated code. This addresses a fundamental misunderstanding about how modern AI data analysis works. Early ChatGPT enthusiasm led people to believe you could simply feed raw datasets to LLMs and get answers, but LLMs can’t actually process numerical data – they generate tokens.
Today’s approach is fundamentally different: LLMs generate Python code, which then processes and analyses data. The LLM understands dataset structure – column names and types – enabling domain-specific code generation based on user requirements. But actual data processing happens through the generated code, making the process more rigorous.
Our tools focus on making code transparency accessible to broader audiences by implementing debuggers, logs, and other software engineering practices that were previously limited to technical users.
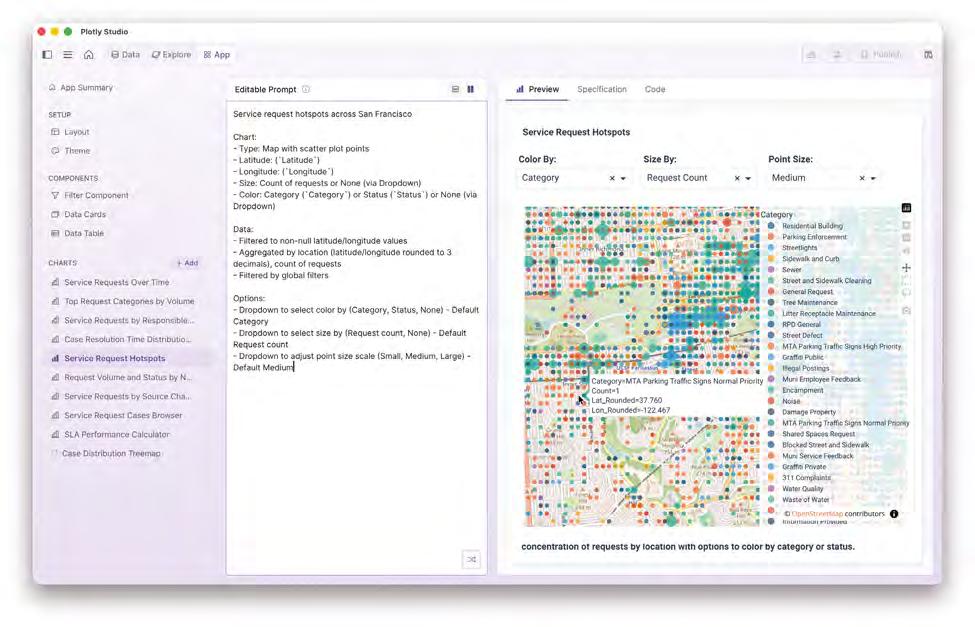
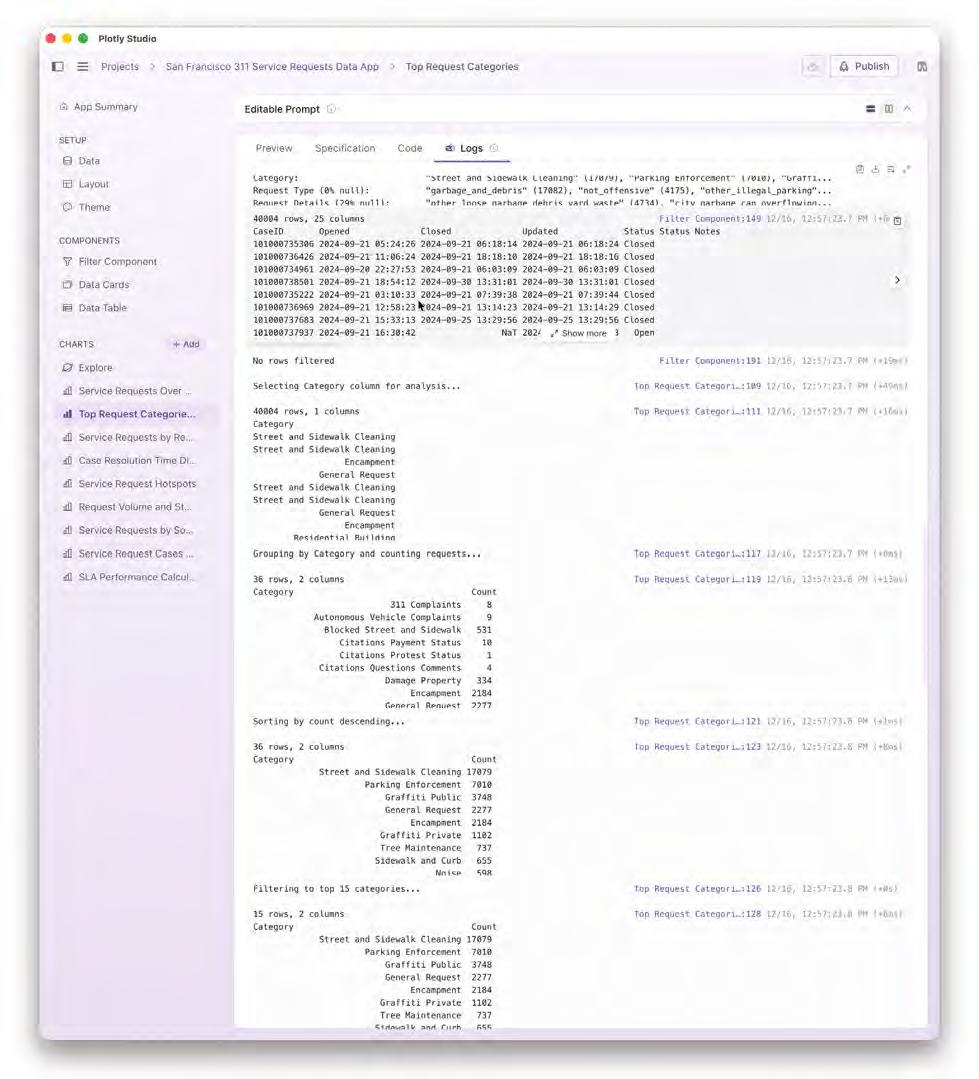
There’s concern that AI might quietly bias analysis outcomes to please users through selective filtering or binning. How do you address this risk?
We approach this by trusting users while implementing strong defaults. Storytelling bias has always existed – if someone wants to mislead, they’ve had tools to do so before AI and will continue to have them.
Rather than moderating output or preventing user intent, we focus on providing excellent defaults that enable honest storytelling. For example, we don’t offer 3D pie charts like the one Steve Jobs famously used in 2007 to make the iPhone market share appear larger. Our pie charts
automatically order sectors from largest to smallest and include clear labels.
We invest heavily in thoughtful visualisation defaults that make misleading presentations difficult while trusting users to act with good intent.
The recent OpenAI GPT-5 launch provides a contemporary example. Their bar chart showed confusing results where a lower numerical score appeared higher visually than a higher score from another model. Whether this was model-generated, human error, or deliberate misleading remains unclear, but it demonstrates that visualisation accuracy challenges persist.
CHRIS PARMER
It’s easier than ever to create visualisations, but the responsibility for accuracy and verification still lies with creators and communicators.
That example highlights why our technical approach matters. If that was image generation, it represents a completely different technology than ours. We don’t use LLMs for vision or image generation – we generate Python code that processes data into JSON structures, which JavaScript engines convert to SVG and render in browsers. This architecture eliminates the possibility of visual hallucinations that could occur with image-generation approaches.
For non-technical users who can’t evaluate code, how can they determine if AI-generated analysis code is accurate?
We address this through multiple accuracy layers. First, basic functionality: does the code actually run without syntax errors? Raw LLM output today only succeeds about one-third of the time – two-thirds contain syntax errors that prevent execution. However, with our autocorrection loops and surrounding tooling, we achieve 90%+ accuracy rates.
The deeper challenge is ensuring analytical correctness. We’re building transparent verification tools into our product, including English-language descriptions of code functionality. This works well for analytics because analytical code follows sequential steps – ‘bin data by hour, then calculate average’ – creating straightforward one-toone correspondence between descriptions and code with minimal hallucination risk.
Most importantly, we provide step-by-step data transformation verification. Users can examine raw data, see intermediate transformations, and inspect final results. This enables easy spot-checking at each stage – the same verification process needed for any analytics project, whether human or AI-generated.
We’re actually building superior verification interfaces compared to current practices. Try auditing a complex Excel spreadsheet with hundreds of formulas – our transparent, step-by-step approach will be far more accessible. This represents standard verification practice regardless of how code is generated.
Should AI systems push back when users communicate agendas or attempt to manipulate analysis toward predetermined conclusions?
We’re deliberately not having our systems generate insights for users. Instead, we provide visualisation and scenario exploration tools with humans making interpretations.
Consider my 311 complaints example: if someone from the mayor’s office requested visualisations showing city improvement, a chatbot might hallucinate confirmatory answers and fabricate supporting numbers. Our system would generate code comparing this year versus last year and visualise the results without interpretation – letting users draw their own conclusions from actual data.
While the system could potentially manipulate data to support narratives, we discourage this behaviour and ensure end viewers can examine underlying data sources. Ultimately, people have always been able to fabricate
data to support their stories – AI doesn’t fundamentally change this reality.
What technical guardrails do you have in place to prevent misleading AI-generated results?
Our primary guardrail is visualising data directly without interpretation layers. We’ve embedded a decade’s worth of data visualisation best practices into the product itself – appropriate chart types, our established house style, and proper aggregation methods and controls that enable visualisations to tell complete stories.
We also rely on the frontier models themselves, which are building moderation techniques directly into their systems. We’re largely deferring to these advanced models to handle much of the content moderation.
Have you encountered situations where AI-powered tools actually made things harder for users or forced them to adapt in unexpected ways?
Natural language interfaces can obscure what’s technically possible with underlying code. When coding directly, you develop intuition about feasibility because you’re crafting the strategy yourself. We’ve seen users request impossible functionality, making it difficult to provide clear feedback about technical limitations – leading them down unproductive rabbit holes.
This reflects AI’s ‘jagged frontier’ – remarkable capabilities in some areas, surprising limitations in others, with boundaries that aren’t apparent until experienced. I tell users that their existing expertise in Python, data science, or Plotly libraries remains valuable. The better you understand underlying fundamentals, the more effectively you can guide AI toward achievable solutions.
Can you explain Plotly’s technical approach to the platform?
We’ve maintained a code-first approach to data visualisation and application development since our founding. Our Python library, launched in 2014, now sees tens of millions of downloads monthly. This positions us perfectly for the AI era because LLMs excel at code generation.
Our open-source libraries – Dash and Plotly graphing library – include tens of thousands of examples that LLMs have been trained on. This enables them to generate sophisticated Python code for applications and visualisations.
Our latest product, Plotly Studio, is an AI-native application for creating visualisations, dashboards, and data apps. However, we’ve learned that LLMs represent only 30% of the solution. The remaining 70% is the tooling ecosystem – running code, verification, testing, and iterative improvement. This creates what many call ‘agentic AI’ – code generation within an execution environment that can test and refine its output.
Ultimately, people have always been able to fabricate data to support their stories – AI doesn’t fundamentally change this reality.
CHRIS PARMER
Plotly Studio bundles everything: Python runtime, code generation, automatic rendering, error correction, and an intuitive interface. This comprehensive approach makes agentic analytics accessible to everyone.
This sounds similar to data scientist workflows –Sandbox environments, iterative analysis. Is that the direction you’re heading?
Exactly. We enable data scientists and analysts to visually explore datasets through various lenses – raw data, simulations, scenario modelling. These analytical capabilities leverage custom code execution, which traditional BI tools struggle with. While most BI platforms excel at data visualisation, they’re limited in running analytics on top of that data.
Code-based analytics unlock these advanced capabilities, and AI now allows users to instruct this process in natural language rather than requiring programming expertise.
Plotly Studio’s simplicity masks significant technological complexity. We’ve embedded hundreds, potentially over a thousand suggestions that guide code generation toward consistent structures. Unlike other vibe coding tools that generate monolithic files with thousands of lines, we enforce clean architecture: separate files, structured projects, and consistent templates that improve both accuracy and maintainability.
We’ve encoded years of hard-learned lessons from building applications for customers. This includes optimisation defaults like automatically enabling WebGLbased visualisations over slower SVG alternatives. LLMs are powerful when guided by experienced operators –we’ve baked that expertise directly into the product so users benefit from best practices without needing deep technical knowledge.
Python installation remains notoriously difficult for newcomers. We’ve packaged Python directly into our application runtime, handling cross-platform compatibility, certificate issues, corporate network constraints, and permissions automatically. Users can download and run immediately without technical setup.
Our auto-correction system provides rich context to LLMs when syntax errors occur – variable scope, debugging traces, and detailed error information enable superior self-correction. We’ve architected code generation for parallel execution across multiple agents. While generating
2,000-5,000 lines of Python code would typically require 10 minutes sequentially, our parallel approach delivers complete applications in 90 seconds to two minutes.
Error compounding presents a fundamental challenge: if each step in a 10-step agentic process achieves 99% accuracy, the overall success rate drops to approximately 90% (99^10). We’ve specifically designed our architecture to minimise steps and enhance self-correction capabilities, maintaining high accuracy in complex multiagent workflows.
This engineering focus on error prevention and parallel processing enables the reliable, fast experience that makes advanced analytics accessible to non-technical users.
What’s the technical mechanism for maintaining structure and minimising errors in your AI agents?
We’ve built a custom engine that runs code in our controlled environment with strict structural requirements. Rather than allowing freewheeling agents, we provide specific instructions, expected inputs/outputs, and constraints to ensure high accuracy and consistent testing.
AI systems work best in feedback loops – generating code, running it, testing it, and self-correcting. LLMs won’t do this by default, so we’ve structured our code generation for easy testing. Our proprietary testing engine evaluates generated code and provides targeted error correction loops for automatic fixes.
This controlled approach maintains the accuracy needed for reliable analytics applications while preserving the flexibility that makes AI-powered analysis powerful.
Looking ahead, what do you think people will get wrong about AI and data visualisation in the coming years?
The biggest risk is rushing to fully automated insights generation. It remains unclear how effectively AI can generate insights independently versus requiring human interpretation. I believe we should focus on building excellent tools for human interpretation rather than having AI make decisions without understanding implicit analytical ambiguities.
Many systems may attempt to ‘skip to the finish’ – having AI interpret results and make decisions autonomously. This could lead to incorrect insights and assumptions, representing a potentially dangerous leap too far ahead of current capabilities.












JAMES DUEZ
JAMES DUEZ is the CEO and co-founder of Rainbird.AI, a decision intelligence business focused on the automation of complex human decision-making. James has over 30 years’ experience building and investing in technology companies with experience in global compliance, enterprise transformation and decision science. He has worked extensively with Global 250 organisations and state departments, is one of Grant Thornton’s ‘Faces of a Vibrant Economy’, a member of the NextMed faculty and an official member of the Forbes Technology Council.
he European Union’s Artificial Intelligence Act (AI Act) introduces the first comprehensive regulatory framework for artificial intelligence, setting out rules to govern its development, deployment, and oversight through a risk-based classification model. The framework prohibits practices deemed to pose unacceptable risks, imposes stringent requirements on high-risk systems, and establishes proportionate transparency obligations for systems assessed as lower risk.
The implications for enterprises are considerable. In regulated sectors such as banking, financial services, insurance, healthcare, tax and law, most AI deployments are likely to fall under the high-risk classification. Organisations operating in these areas must demonstrate transparency, explainability, auditability, and human
oversight in AI-driven decision-making.
However, a central challenge emerges from the limitations of many current AI systems, particularly large language models (LLMs) and other black-box machine learning (ML) approaches, which are probabilistic in nature, lack determinism , and often fail to provide sufficient transparency or auditability
This paper offers an overview of the AI Act and its requirements, analyses its implications for enterprises, examines the limitations of black-box AI in meeting regulatory standards, and discusses deterministic and auditable AI as a viable compliant approach. It also provides sectorspecific insights into the likely impacts and opportunities created by the Act and outlines practical steps organisations can take to prepare for compliance.
PHILIPP KOEHN JAMES DUEZ
Artificial intelligence is an umbrella term describing a large number of technical approaches that have evolved over time. It never was ‘one thing’. Thanks to this latest hype cycle around generative AI (and now agentic AI), it has evolved from an experimental technology into a foundational component of enterprise transformation. Its applications already span credit underwriting, fraud detection, patient risk assessment, and tax auditing, influencing outcomes with significant legal, financial, and human implications.
As adoption has expanded, so too have concerns about transparency, fairness, bias, and accountability. Regulators across the globe are responding, and the EU AI Act represents the first binding framework to translate these concerns into enforceable standards, while other territories bring forward their own laws.
The Act aims to mitigate risks associated with AI while simultaneously fostering confidence in its use. By codifying obligations related to explainability, oversight, and accountability, the legislation seeks to encourage responsible deployment and establish consistent conditions for market participants. For business leaders, the AI Act presents both obligations and opportunities. Compliance is mandatory, but early alignment may allow organisations to position themselves as trusted operators within numerous regulated environments.
The Act establishes a tiered framework that classifies AI systems according to their potential risk. At the highest level of concern , systems deemed to present unacceptable risk are prohibited outright. These include applications that engage in manipulative social scoring, exploit vulnerable groups, or deploy biometric surveillance for mass monitoring. Such systems are considered incompatible with European values and human rights.
High-risk systems , by contrast, are those deployed in critical contexts where errors could have serious consequences. This category encompasses credit scoring, KYC and AML checks, and fraud monitoring in financial services; underwriting and claims adjudication in insurance; diagnostics and treatment recommendations in healthcare; suitability assessments in legal and compliance contexts; and recruitment or employee evaluation in the workplace. These systems are subject to the most stringent compliance requirements.
Limited-risk systems are those that could cause harm if misused, though the potential impact is less severe. They are primarily subject to transparency obligations, such as disclosing when users are interacting with AI.
Minimal-risk systems , including consumer applications like spam filters or video games, remain covered by general consumer protection and safety rules without additional obligations.
As adoption has expanded, so too have concerns about transparency, fairness, bias, and accountability[...]
The Act aims to mitigate risks associated withAI while simultaneously fostering confidence in its use.
The vast majority of use cases in regulated sectors are inherently high risk. These systems must satisfy a range of specific obligations.
● Organisations must implement robust risk management processes that identify, assess, and mitigate potential harms.
● Data governance requirements mandate that input and training data are relevant, representative, and free from bias.
● Comprehensive documentation and recordkeeping are essential to demonstrate compliance, supported by detailed technical files.
● Transparency and information obligations require that users are clearly informed about the system’s capabilities and limitations.
● Human oversight mechanisms must be established to allow for review and, when necessary, the overriding of automated decisions.
● Finally, systems must meet rigorous standards for robustness, accuracy, and security, ensuring consistent and reliable performance and resilience against manipulation.
The penalties for non-compliance are substantial. Breaches involving prohibited practices can result in fines of up to €35 million or seven percent of global turnover, while failures to comply with high-risk system obligations may incur fines of up to €15 million or three percent of global turnover. Lesser infringements, including non-compliance with transparency obligations, also carry significant financial penalties.
JAMES DUEZ
Legal and Regulatory Exposure
Boards and senior executives will be directly accountable for the decisions made by high-risk AI systems. This accountability includes ensuring that such systems are explainable, auditable, and free from discriminatory bias. Regulatory authorities are expected to demand verifiable evidence of compliance.
Operational and Cost Considerations
Complying with the Act will require organisations to implement new governance frameworks. Enterprises must maintain detailed compliance documentation for each high-risk deployment, introduce monitoring systems capable of producing auditable decision trails (almost impossible with an LLM approach), train staff in oversight functions, and review procurement processes to ensure alignment with regulatory standards. Although the initial costs of compliance may be high, the financial and reputational costs of non-compliance could prove far greater.
Reputational Considerations
Public and stakeholder trust in AI remains fragile. It’s clear that failure to meet regulatory expectations will result in reputational damage, customer attrition, and/or litigation. Conversely, organisations that can demonstrate compliance and accountability stand to strengthen their reputations and gain competitive advantage.
Generative AI and machine learning systems are predictive technologies that have dramatically expanded enterprise capabilities but face considerable compliance challenges under the AI Act, especially when applied to decisioning. These systems are inherently opaque and unable to clearly explain how outputs are generated, thereby violating a raft of obligations. Their non-deterministic nature means identical inputs can produce variable outputs, undermining accuracy and repeatability. Models trained on internetscale public datasets inevitably inherit and amplify bias, which can remain undetected until deployment. Auditability is another critical issue, as outputs cannot easily and logically be reconstructed in a format suitable for regulatory scrutiny.
Human oversight, the last bastion of any automated system, is also deeply problematic. Human supervision of opaque systems is inherently difficult because of deep cognitive automation bias and the challenge of validating outputs without visibility into the reasoning process. Even techniques such as retrieval-augmented generation (RAG) or GraphRAG do not resolve the fundamental issue that probabilistic models cannot deliver the deterministic, rule-based reasoning required by the Act, and are revealing themselves to be susceptible to degradation and scale and easy to poison.
Deterministic neuro-symbolic approaches align much more closely with the legal obligations outlined in the AI Act.
● Precise incorporation of knowledge graph-based world models can combine with symbolic inference to ensure that regulation, policy and institutional knowledge is treated as a first-class citizen in the AI tech stack, eliminating hallucinations completely.
● Deterministic reasoning guarantees that identical inputs will always produce identical outputs, providing repeatability and reliability.
● Auditability ensures that every decision is accompanied by a complete evidential trail, enabling immediate regulatory review.
● Governance alignment arises when compliance logic is tightly encoded directly within the reasoning process itself, reducing dependence on ad-hoc, after-the-event external observation or guardrail mechanisms.
Collectively, these features make deterministic AI uniquely suitable for deployment in mission-critical, high-risk processes while maintaining compliance with the Act.
The AI Act will levy its greatest impact on sectors that are deploying AI applications in high-risk domains.
● In financial s ervices , areas like credit decisioning, suitability, AML (transaction monitoring and KYC) and fraud prevention will require systems capable of producing consistent, auditable, and nondiscriminatory results.
● In insurance , underwriting and claims processing will attract increasingly close regulatory attention, but where auditable systems can simultaneously improve both efficiency and trust.
● In healthcare , eligibility assessments, prior authorisations, and clinical risk evaluations must meet exacting standards of precision and transparency, aligning with both the AI Act and existing regulations like the GDPR.
● In le gal and tax contexts , tax assessments, audits, and compliance reporting must depend on deterministic reasoning to ensure outcomes are explainable to auditors, regulators, and ultimately, courts.

While compliance introduces new obligations, it also generates opportunities: organisations that embrace trustworthy AI architectures will be able to strengthen operational resilience, enhance efficiency, and support their digital transformation agendas.
Organisations that can demonstrate compliance and accountability stand to strengthen theirreputations and gain competitive advantage.
The AI Act is creating a divide in the market, separating vendors who can demonstrate transparency and determinism from those who cannot. Software vendors reliant on only probabilistic models may increasingly struggle to compete in these regulated sectors, while those offering compliant, explainable, and auditable systems are likely to become the preferred choice for highstakes applications.
For enterprises, compliant AI will deliver strategic benefits beyond risk management. By deploying inherently auditable systems, organisations increase efficiency and reduce compliance risk. They will get to build stronger relationships with both customers and regulators. This approach will also drive innovation, supporting faster service delivery, new product development (with associated revenues), and improved customer outcomes.
Enterprises should adopt proactive measures to prepare for the next phase of the AI Act. They should begin by auditing their existing AI systems, cataloguing deployments, classifying them according to the Act’s criteria, and identifying high-risk applications.
Next, they should conduct gap analyses to assess deficiencies in precision, determinism, auditability,
bias mitigation, and oversight. Procurement strategies must be refined to prioritise solutions that deliver precise, deterministic and auditable outputs. Organisations should establish governance frameworks that integrate AI risk management policies, assign accountability at board level, and align oversight with enterprise risk structures. Building internal capabilities is equally essential: teams must be trained to validate and manage compliant AI systems.
Finally, proactive engagement with regulators will help organisations align expectations, demonstrate readiness, and avoid the risk of future enforcement.
The EU Artificial Intelligence Act represents a defining moment in the governance of AI, setting a global precedent for transparency, accountability, and safety. Its impact will continue to reshape how enterprises design, deploy, and monitor AI systems in critical applications.
Compliance is not optional, and the limitations of black-box models make them ill-suited to meet its demands.
Deterministic, explainable AI architectures offer a practical and effective path forward, enabling organisations to satisfy regulatory requirements while building lasting trust.
Enterprises that act early to embed complianceready AI into their operations will not only minimise risk and regulatory exposure but also secure a meaningful competitive advantage in a world where institutional knowledge (and the ability to scale it to machine levels) plus trust-by-design, have become the ultimate differentiators.

FRANCESCO GADALETA

Artificial intelligence is no stranger to bold ideas, but every once in a while a concept appears that feels genuinely alien, something that doesn’t just tweak existing methods, but questions their very foundations. VortexNet is one of those ideas. Inspired not by neuroscience or statistics, but by fluid dynamics , this experimental neural architecture proposes a striking shift in how we think about learning systems: not as chains of static mathematical operations, but as flows of information that swirl, oscillate, and
resonate like water around an obstacle. At first glance, it sounds almost too eccentric to take seriously. Yet behind the poetic metaphor lies a rigorous mathematical framework grounded in modified Navier–Stokes equations , the same equations used to describe the motion of fluids. The proposal comes from researcher Samin Winer , and while still at an early, largely theoretical stage, it raises provocative questions about some of the most stubborn limitations in modern AI and in particular, large language models.
(VortexNet) proposes a striking shift inhow we think about learning systems: not as chains of staticmathematical operations, but as flows of information thatswirl,oscillate, and resonate like wateraround an obstacle.
FRANCESCO GADALETA is a seasoned professional in the field of technology, AI and data science. He is the founder of Amethix Technologies, a firm specialising in advanced data and robotics solutions. Francesco also shares his insights and knowledge as the host of the podcast Data Science at Home . His illustrious career includes a significant tenure as the Chief Data Officer at Abe AI, which was later acquired by Envestnet Yodlee Inc. Francesco was a pivotal member of the Advanced Analytics Team at Johnson & Johnson. His professional interests are diverse, spanning applied mathematics, advanced machine learning, computer programming, robotics, and the study of decentralised and distributed systems. Francesco’s expertise spans domains including healthcare, defence, pharma, energy, and finance.
WHAT’S BROKEN IN TODAY’S NEURAL NETWORKS?
Despite their remarkable successes, today’s deep learning systems remain constrained by well-known structural problems.
One of the oldest is the vanishing gradient problem . As training signals propagate backwards through deep networks, they often shrink to near zero, leaving early layers with little ability to learn. The consequence is a kind of informational decay: the deeper the network, the harder it becomes to preserve meaningful learning signals at its foundations.
A second challenge is the problem of long-range dependencies While transformers and attention mechanisms have improved the ability to link distant parts of a sequence,
the solution is expensive. Attention scales quadratically with input length, making truly long-context reasoning computationally prohibitive.
Then there is the issue of multiscale processing . Human cognition effortlessly balances fine-grained details with high-level context, switching seamlessly between letters, words, and full meanings. Neural networks struggle to achieve this balance without elaborate architectural tricks.
These problems are not unsolved as much as they are mitigated with workarounds , often at significant computational cost. VortexNet enters precisely at this point of tension, proposing that the solution may come not from more layers or more parameters (as it seems to be the trend nowadays), but from physics itself
Instead of treating information as something that flows linearly from layer to layer, VortexNet treats it as something that moves, rotates, and interacts dynamically , much like a fluid. The guiding inspiration is the von Kármán vortex street , a phenomenon observed when fluid flows past an obstacle, producing alternating vortices in its wake. These vortices transfer energy and information across scales in complex, structured patterns.
In VortexNet, this behaviour is not merely metaphorical. The architecture directly implements vortex-like dynamics using:
● Complex numbers , which naturally encode magnitude and phase (perfect for modelling oscillations and rotations).
● Vortex layers , where counterrotating activation fields interact rather than simply passing signals forward.
● Physical parameters such as viscosity, convection, and forcing, borrowed directly from fluid dynamics and made trainable within the network.
Viscosity controls how quickly information diffuses. Convection determines how activations carry
information through the system. Forcing represents the external input. Together, these components allow learning signals to circulate and resonate , rather than merely propagate.
A particularly elegant adaptation is the introduction of a Strouhal neural number , inspired by the Strouhal number in fluid mechanics, which predicts vortex shedding frequencies. In the neural context, this ratio governs how activations oscillate across layers, helping the network discover its own natural resonant frequencies, much like pushing a swing at just the right rhythm to amplify motion with minimal effort.
To prevent uncontrolled oscillations, VortexNet introduces an adaptive damping mechanism , continuously adjusting stability during training. The goal is to keep the system at the so-called ‘edge of chaos’: stable enough to learn, yet expressive enough to model complex dynamics.
SO, WHY THIS COULD MATTER? If VortexNet’s theoretical promises hold, the implications are substantial.
First, vanishing gradients may be alleviated through resonant pathways that allow learning signals to bypass rigid, layer-by-layer attenuation. Instead of information fading as it travels, it can be reinforced through distributed oscillations.
Second, the model introduces the idea of implicit attention . Unlike transformers, which explicitly compare every token to every other token, vortex interactions naturally influence each other through their physics. This could provide a way to model long-range dependencies without quadratic computational cost
Third, VortexNet inherently supports multi-scale processing
Just as large vortices spawn smaller ones in turbulent flows, the architecture can, in principle, represent fine details and global structure simultaneously.
Finally, the system exhibits a form of dynamic memory . Stable oscillatory patterns, known in dynamical systems as attractors, can encode persistent information without requiring explicit memory buffers. Memory, in this view, is not stored statically but
maintained through motion
PHYSICS-INSPIRED COMPUTING
VortexNet belongs to a wider movement in AI research that seeks to embed physical principles directly into computation . This includes physicsinformed neural networks (PINNs), neural ordinary differential equations, and neuromorphic hardware. What unites these approaches is a departure from purely symbolic or statistical abstractions toward continuous, dynamical systems
Traditional neural networks are fundamentally digital: discrete layers, discrete operations, discrete transitions. VortexNet is explicitly analogue in spirit . Information does not hop. It flows.
This perspective resonates with what we know about biological brains. Neurons do not merely switch on and off; they oscillate, synchronise, and form transient assemblies. Computation in the brain is not a clean sequence of steps but a dynamic field of interacting signals . Vortex dynamics may capture part of that deeper structure.
The proposed applications are ambitious: long-sequence modelling for genomics and medical records, time-series prediction in finance and climate science, and multimodal learning that naturally integrates vision, sound, and text across scales.
Yet realism is essential. VortexNet remains highly experimental . Its current demonstrations are limited to basic benchmarks such as MNIST digit recognition. There are formidable challenges ahead, among which:
● Efficiently implementing partial differential equation solvers inside deep learning frameworks.
● Ensuring numerical stability with automatic differentiation.
● Establishing computational scalability compared to transformer-based systems.
● Developing a robust theoretical foundation for convergence, stability, and generalisation.
The framework touches chaos theory, dynamical systems, and computational physics, all fields rich with insight but notoriously difficult to tame.
Whether VortexNet itself becomes a mainstream architecture is impossible to predict. But its deeper significance may lie elsewhere. It challenges the assumption that progress in AI must come from bigger models, longer
contexts, and more parameters . Instead, it asks a more radical question: What if the very way we move information through a network is wrong?
Today’s AI landscape is dominated by transformer architectures and next-token prediction. VortexNet reminds us that this is not the only possible future. There are entire scientific domains, fluid dynamics, thermodynamics, and nonlinear systems, that remain largely untapped as sources of
computational inspiration.
Perhaps the next generation of intelligent systems will not resemble ever-larger language models. Perhaps they will look more like turbulent fluids , where information moves in swirling, resonant patterns rather than straight lines.
It is too early to say whether VortexNet will succeed. But as a provocation, a reminder that artificial intelligence can still be reimagined from first principles, it is one of the most intriguing ideas to surface in recent years.


BY NICOLE JANEWAY BILLS
NICOLE JANEWAY BILLS is the founder & CEO of Data Strategy Professionals. She has four years of experience providing training for data-related exams and offers a proven track record of applying data strategy and related disciplines to solve clients’ most pressing challenges. She has worked as a data scientist and project manager for federal and commercial consulting teams. Her business experience includes natural language processing, cloud computing, statistical testing, pricing analysis, ETL processes, and web and application development. She attained recognition from DAMA for a Master Level pass of the CDMP Fundamentals Exam.
These book recommendations centre on data governance, data management, and the people behind successful data programs. From change management and C-suite leadership to hands-on implementation and enterprise information strategy, these selections reflect the continued demand for structure that works in real organisations. The reading list reflects a continued shift toward treating data and information as true business assets, supported by people, process, and accountability.
Author: Aakriti Agrawal and Dr Arvind Agrawal
Time to read: 7 hrs 10 mins (215 pages)
Rating: 5/5 (9 total ratings)
This book focuses on the human side of data governance by showing how change management can make or break a program. The authors introduce the Aim, Need, Community, Hooray, Obstacles, and Resilience (ANCHOR) framework as a practical path for building trust, reducing resistance, and helping teams shift from inconsistent data habits to intentional practice. Through relatable scenarios and clear guidance, the book highlights how leaders can align behaviour, expectations, and communication to support long-term adoption of governance. It is especially helpful for organisations that already have the right tools but struggle with team engagement or cultural readiness.
TL;DR: A people-first guide to data governance adoption that uses the ANCHOR framework to help leaders build trust, reduce resistance, and drive consistent data behaviour across the organisation.
Author: Sunil Soares
Time to read: 2 hrs 40 mins (80 pages)
Rating: 4/5 (152 total ratings)

21Sunil Soares offers a practical playbook for chief data officers (CDOs) who need to define, launch, and operationalise data governance programs. The book breaks down the core components of governance – from policy development to stewardship models – and pairs them with templates, examples, and repeatable steps. Soares draws from years of working with large enterprises, making the guidance both scalable and grounded in real-world challenges. It serves as a strong reference for new CDOs and experienced leaders who want structure and clarity in how they govern data.
TL;DR: A hands-on handbook that gives CDOs clear guidance to stand up and scale data governance across complex organisations.
Author: John Ladley
Time to read: 11 hrs 40 min (350 pages)
Rating: 4.5/5 (147 total ratings)
3
John Ladley delivers a comprehensive guide to building data governance programs that work across business and technology teams. He explains the foundational concepts, decision rights, and operating models needed to support governance at scale. The book stands out for its balance of strategy and practical execution, showing how to embed governance into daily workflow rather than treat it as a separate initiative. Ladley also addresses common barriers – from unclear roles to poor communication – and provides tools to help leaders maintain momentum after the initial launch.
TL;DR: A complete blueprint for designing and sustaining data governance, combining clear concepts with practical steps that help teams turn policy into daily practice.


THE DATA MANAGEMENT TOOLKIT: A STEP-BY-STEP IMPLEMENTATION GUIDE FOR THE PIONEERS OF DATA MANAGEMENT
Author: Irina Steenbeek
Time to read: 7 hrs 12 min (216 pages)
Rating: 4.5/5 (22 total ratings)
4
Irina Steenbeek presents a structured approach to building repeatable data management processes. Her toolkit breaks complex data functions into manageable components and offers step-by-step instructions that help teams move from high-level strategy to operational detail. The book is especially valuable for organisations starting from scratch or formalising early data efforts. With real-world examples, Steenbeek helps data management leads create a program that is both scalable and sustainable.
TL;DR: A step-by-step guide that helps data management practitioners turn strategy into actionable processes through structure and repeatable methods.
FOR BUSINESS: A GUIDE TO UNDERSTANDING INFORMATION AS AN ASSET
Author: John Ladley
Time to read: 18 hrs 24 mins (552 pages)
Rating: 4.4/5 (23 total ratings)
In this foundational work, John Ladley explains how organisations can treat information as a true business asset rather than a technical afterthought. The book outlines how enterprise information management (EIM) ties together governance, architecture, quality, and analytics to support enterprise goals. Ladley uses practical examples to show how better information practices improve decision-making, reduce risk, and strengthen operational performance. For leaders navigating broad data and information challenges, this book offers a clear framework for aligning people, process, and technology.
TL;DR: A practical guide that shows how to treat information as a business asset by aligning EIM with governance, architecture, and organisational goals.
5


Author: Susan Cain
Time to read: 12 hrs 16 min (368 pages)
Rating: 4.5/5 (35,021 total ratings)
6
Susan Cain explores the strengths introverts bring to work, leadership, and everyday life. Through research and personal stories, she highlights how introverts contribute through deep thinking, careful planning, and intense listening. The book challenges the assumption that extroversion is the ideal and encourages organisations to create environments where both personality types can thrive. It is a helpful read for professionals who want to better understand how temperament shapes collaboration and performance.
TL;DR: A thoughtful look at the strengths of introverts and how organisations can create environments that support different working styles.

Author: Samir Sharma
Time to read: 5 hrs 38 min (169 pages)
Rating: new release
Samir Sharma focuses on one of the most common challenges in data strategy: turning plans into real execution. The book introduces the Strategy Canvas as a practical working tool that helps teams connect business goals with data architecture, data governance, and delivery priorities. Rather than staying at a high level, Sharma walks readers through mapping decisions, dependencies, and outcomes in a way that keeps strategy grounded in daily work. The book is well-suited for leaders who struggle with misalignment between vision and what teams actually build.
TL;DR: A practical field guide that helps teams close the gap between data strategy and execution using a clear, hands-on framework that connects goals to delivery.

These book selections reflect the core realities of modern data leadership: guiding change, creating structure, and sustaining accountability across the organisation. Data Governance Change Management emphasises trust and behaviour as the foundation for adoption. T he Chief Data Officer Handbook for Data Governance and John Ladley’s Data Governance and EIM works provide clear models for building durable programs. The Data Management Toolkit supports hands-on execution through practical steps. Quiet reinforces that leadership style and temperament shape how data programs succeed in real teams. This collection offers clear direction for leaders working to strengthen data governance and data management in active, complex environments.
















